Базы данных. Обработка данных и организация БД. Функции СУБД
1. Принципы обработки данных
История возникновения и развития систем обработки данных органически связана с историей развития вычислительной техники.
На первом этапе (50-е годы прошлого века) компьютеры использовались для решения задач вычислительного характера, которые характеризует следующее:
- небольшой объем исходных данных;
- сложные алгоритмы обработки данных;
- исходные данные – числа;
- описание данных располагается в программе;
- исходные данные в программе используются однократно;
- исходные данные размещаются в оперативной памяти компьютера вместе с программой в так называемом сегменте данных (рис. 1).
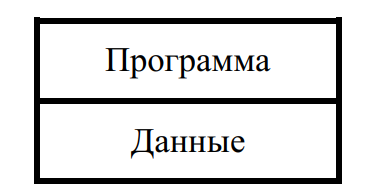
Рис. 1. Представление программы и данных в памяти компьютера
Типичным примером такого класса задач является задача решения системы алгебраических уравнений одним из численных методов. Если система состоит из десяти уравнений, то число исходных данных будет составлять 110 чисел, а в результате решения получим 10 чисел. Естественно предположить, что повторно решать систему уравнений с теми же коэффициентами нет смысла.
Второй этап применения компьютеров (60-е годы прошлого века) характеризуется переходом к новому поколению ЭВМ и появлением нового класса задач, который относится к использованию средств вычислительной техники в автоматизированных информационных системах.
Эти задачи характеризуются:
- большим объемом исходных данных;
- использованием сложных структур данных;
- исходные данные хранятся в виде файлов на внешних устройствах памяти автономно от программы (рис. 2);
- программа содержит описание структуры файла;
- данные файлов используются многократно.
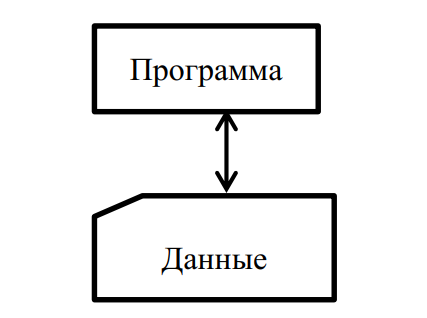
Рис. 2. Использование файлов для обработки данных
В ЭВМ этого периода времени в качестве внешних запоминающихся устройств, главным образом, использовались магнитные ленты, т.е. устройства последовательного доступа к данным. Это привело к тому, что при достаточно высоком быстродействии вычислений данные информационных задач хранились на “медленных” внешних запоминающих устройствах.
Можно предположить, что именно требования информационных задач вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали большой емкостью, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных. С появлением магнитных дисков началась история систем управления данными во внешней памяти.
Однако файлы с произвольным доступом решили проблемы лишь частично.
Файловые системы обладают рядом недостатков:
- Зависимость программ от данных. Сведения о структуре данных включались в код программы. При изменении структуры данных необходимо было вносить изменения в программу.
- Избыточность данных. Практика применения такого подхода показала, что при наличии нескольких программ, обрабатывающих файлы, возникают трудно преодолимые проблемы с обеспечением достоверности исходных данных. Предположим, что на предприятии отдельные службы решили автоматизировать часть своих функций с помощью ЭВМ. Тогда бухгалтерия для собственных целей создаст набор данных, содержащий сведения о рабочих и служащих предприятия, и использует этот набор для решения своих задач. Отдел кадров для своих задач создаст набор данных, который также содержит сведения о сотрудниках предприятия, причем часть данных этого набора отражает ту же информацию, что данные первого набора. В результате многие данные, хранящиеся в памяти ЭВМ, дублируются, что ведет к неоправданному расходу памяти. Избыточность данных также порождает риск противоречий между разными версиями общих данных. Например, если сотрудник изменил фамилию, а изменения внесены в разные файлы не одновременно, то через некоторое время такие расхождения могут существенно снизить качество информации, содержащейся в файлах данных.
- Неэффективность параллельной работы нескольких пользователей. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу. В операционных системах обычно применялся следующий подход. В операции открытия файла среди прочих параметров указывался режим работы (чтение или запись). Если к моменту выполнения этой операции некоторым пользовательским процессом P2 файл был уже открыт другим процессом P1 в режиме записи, то в зависимости от особенностей системы процессу P2 либо сообщалось о невозможности открытия файла, либо он блокировался до тех пор, пока в процессе P1 не выполнялась операция закрытия файла. При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена.
Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к организации данных. Этот подход предполагает хранение данных и их описания в одном месте (рис. 3).
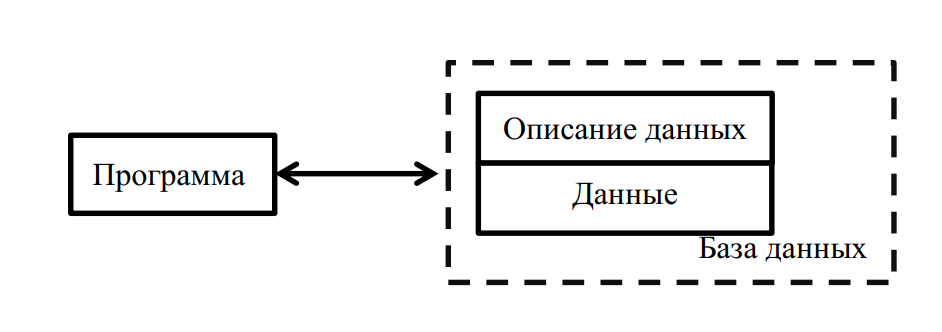
Рис. 3. Схема обработки данных с использованием баз данных
При таком подходе к обработке данных используется единая система взаимосвязанных файлов с минимальной избыточностью, получившая название база данных (БД).
Описание данных называют метаданными. Метаданные хранятся в части базы данных, которая называется каталогом или словарём-справочником данных (ССД). Зная формат метаданных, можно запрашивать и изменять данные без написания дополнительных программ.
Одна и та же база данных может быть использована для решения многих прикладных задач. Наличие метаданных и возможность информационной поддержки решения многих задач – это принципиальные отличия базы данных от любой другой совокупности данных, расположенных во внешней памяти ЭВМ.
2. Основные понятия баз данных
Прежде всего, разберемся с понятиями “данные” и “информация”. Данные представляют собой набор значений, характеризующих объект, процесс, явление и т.д. Сами по себе данные не несут никакой информации. Например, числовое данное равное 5 может быть количеством проданного товара, номером месяца, экзаменационной оценкой, ценой товара и т.п.
Данные становятся информацией тогда, когда пользователь задает им определенную структуру, т. е. осознает их смысловое содержание. Например, в информационной системе торговой фирмы регистрируются продажи товаров. Для этого необходимы следующие данные: код товара, наименование товара, количество, цена, покупатель, дата.
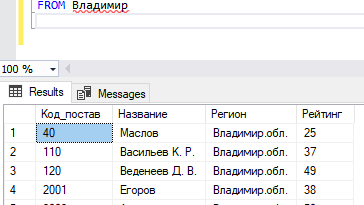
Для каждой продажи соответствующие данные имеют конкретное значение. Например, факт, что фирма «НПП Автоматика» купила 21 марта 2020 года 500 транзисторов КТ209А по цене 7 рублей за штуку, в информационной системе будет представлен в следующем виде (табл. 1)
Таблица 1. Факт конкретной продажи
| Код
товара |
Наименование
товара |
Количество | Цена | Покупатель | Дата |
| 1010 | транзистор
КТ209А |
500 | 7 | НПП Автоматика | 21.03.2020 |
Значения, приведенные в табл. 1, имеют смысл только во взаимосвязи друг с другом. Отдельно выбранное число 500 теряет свой содержательный смысл.
Для описания аналогичных представлений данных в предметной области задач вводится ряд новых понятий.
Элемент данных (поле) – наименьшая единица поименованных данных.
Для данного примера элементами данных являются код товара, наименование товара, количество, цена, покупатель, дата.
Для описания продажи товара используется понятие «Запись».
Запись –совокупность элементов данных (полей).
Для представления всего набора продаж используется понятие «файл»
Файл — поименованная совокупность всех экземпляров записей заданного типа.
Каждый факт продажи товара содержится в одной записи файла. Файлы системы могут содержать огромное количество таких фактов. Таким образом, такой файл содержит данные. Информация же – это организованные данные или выводы из них. Например, информацией будут являться ответы на вопросы:
- Сколько было продано транзисторов КТ209А в январе 2020 года?
- Какие клиенты фирмы, и в каком количестве ежемесячно покупают товар данного наименования?
Обычно такая информация получается в результате обработки большого количества данных и, следовательно, информация отличается от данных.
Таким образом, можно сказать, что данные – это информация, зафиксированная в некоторой форме, пригодной для последующей обработки, передачи и хранения, например, находящаяся в памяти ЭВМ или подготовленная для ввода в ЭВМ; информация – любые сведения о каком-либо событии, явлении, процессе и т.п., являющиеся объектом некоторых операций: восприятия, передачи, преобразования, хранения или использования.
В теории и практики баз данных используется следующая терминология:
Подготовка информации состоит в её формализации, сборе и переносе на машинные носители.
Обработка данных – это совокупность задач, осуществляющих преобразование данных. Обработка данных включает в себя ввод данных в ЭВМ, отбор данных по каким-либо критериям, преобразование структуры данных, перемещение данных на внешней памяти ЭВМ, вывод данных, являющихся результатом решения задач, в табличном или в каком-либо ином удобном для пользователя виде.
3 Информационные системы, использующие концепцию баз данных
Под информационной системой (ИС) будем понимать совокупность программно-аппаратных средств, предназначенных для автоматизации деятельности, связанной с хранением, передачей и обработкой информации.
ИС в общем случае состоит из следующих компонентов: базы (несколько баз) данных, системы управления базами данных (СУБД), описания базы данных.
Архитектура таких систем обработки данных представлена на рис. 4.
Рассмотрим компоненты этой структуры.
База данных (БД) – совокупность данных, организованных по определённым правилам, предусматривающим общие принципы описания, хранения и манипулирования данными, независимая от прикладных программ [8]. Эти данные относятся к определённой предметной области и организованы таким образом, что могут быть использованы для решения многих задач многими пользователями.
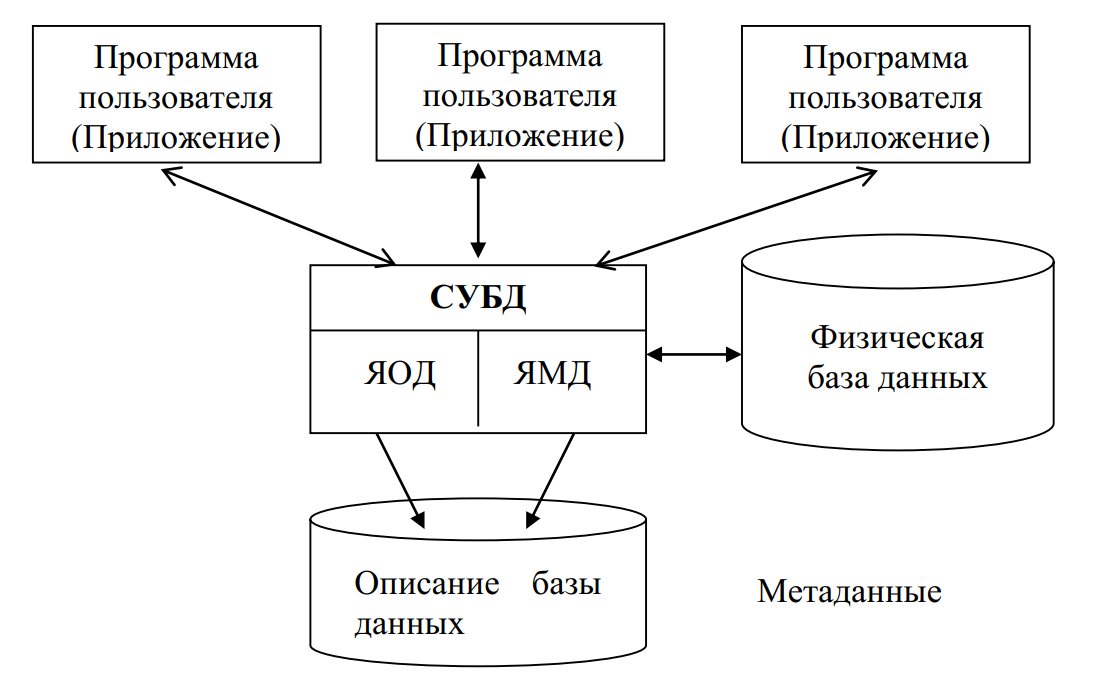
Рис. 4. Архитектура информационных систем, использующих концепцию баз данных
На данных, хранящихся в базе данных, основана вся информация, необходимая в работе любой организации. Но следует заметить, что данные, из которых состоит база данных, должны быть тщательно и логично организованы. Поэтому БД строится по определенным правилам и должна удовлетворять ряду требований, из которых основные:
- Минимальная избыточность. Каждый элемент данных вводится в БД один раз и хранится там в единственном экземпляре. При вводе данных СУБД осуществляет проверку на дублирование.
- Возможность актуализации. Данные, хранящиеся в БД, могут устаревать, при этом возникает необходимость ввести новые данные. Структура данных должна позволять включать новые и удалять устаревшие данные, а также вносить изменения в хранящиеся данные. При этом не должны меняться общая схема БД и программы пользователей.
- Обеспечение целостности данных. В системе возможно возникновение случайных ошибок в результате неосторожных действий пользователей, ошибок в программах и сбоев оборудования. СУБД должна обеспечивать защиту данных от разрушений и возможность восстановления искаженных данных.
- Безопасность и секретность. Пользователи должны работать только с теми данными, которые им необходимы. Данными, хранящимися в системе, не должны пользоваться лица, не имеющие на это права.
- Возможность обеспечения разнообразных запросов пользователей. Это требование является основным для БД.
Система управления базами данных (СУБД) – это совокупность программ и языковых средств, предназначенных для управления данными в базе данных, ведения базы данных и обеспечения взаимодействия её с прикладными программами [8].
Ведение базы данных – деятельность по обновлению, восстановлению и изменению структуры базы данных с целью обеспечения её целостности, сохранности и эффективности использования [8].
С помощью СУБД производятся запись данных в базу данных, их выборка по запросам пользователей и прикладных программ, обеспечивается защита данных от искажений и от несанкционированного доступа и т.п.
Каждой прикладной программе СУБД предоставляет интерфейс с базой данных и располагает средствами доступа к ней. Таким образом, СУБД играет центральную роль в функционировании информационной системы, так как обращение к базе данных возможно только через СУБД.
Концепция баз данных подразумевает рост совместного использования данных различными приложениями (прикладными программами) и сокращение избыточности хранения одних и тех же данных. Для организации управления этими процессами используется описание базы данных.
В описание базы данных хранится структура всех таблиц базы данных, информация об индексах, служащих для быстрого обращения к данным, правила проверки данных и много другой специальной информации о данных. Описание базы данных является частью современной базы данных.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистемы складского учета, четвертое приложение посвящено планированию производственного процесса.
При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
4. Функции СУБД
Как уже отмечалось выше, СУБД выполняет роль интерфейса между прикладными программами и базой данных, обеспечивающего их независимость.
С точки зрения пользователя, СУБД реализует функции:
- Определение структуры создаваемой базы данных. Как правило, создание структуры базы данных происходит в режиме диалога. СУБД последовательно запрашивает у пользователя необходимые данные. В большинстве современных СУБД база данных представляется в виде совокупности таблиц. Рассматриваемая функция позволяет описать и создать в памяти компьютера структуру таблиц.
- Предоставление пользователям возможности манипулирования данными (выборка необходимых данных, выполнение вычислений).
Реализация этих обеих функций в СУБД осуществляется на основе использования специального языка программирования, входящего в состав СУБД. В языках программирования СУБД принято выделять язык описания данных (ЯОД) и язык манипулирования данными (ЯМД).
ЯОД – это язык высокого уровня, предназначенный для описания структуры базы данных. С его помощью описываются типы данных, их размер и связи между собой. Это язык декларативного типа. В соответствии с полученным описанием СУБД сможет найти в базе требуемые данные, правильно преобразовать их и передать, например, в прикладную программу, которой они потребовались. При записи данных в базу данных СУБД определяет место в памяти ЭВМ, куда их требуется поместить, преобразует к заданному виду и устанавливает необходимые связи.
Язык манипулирования данными представляет собой систему команд манипулирования данными и используется в прикладных программах для выполнения операций с базой данных (поиск, вставка, удаление и обновление). При этом фактическая структура физической базы данных известна только СУБД.
Кроме, указанных выше основных функций, СУБД выполняют и другие функции:
- обеспечение логической целостности базы данных;
- обеспечение физической целостности базы данных;
- управление полномочиями пользователей на доступ к базе данных;
- обеспечение одновременного доступа к данным для нескольких пользователей.
Обеспечение логической целостности базы данных.
Основной целью реализации этой функции является повышение достоверности данных в базе данных.
Целостность – свойство базы данных, означающее, что она содержит полную и непротиворечивую информацию, адекватно отражающую предметную область.
Целостность базы данных обеспечивается ограничениями на значения элементов данных, поддержкой заданных принципов взаимосвязи данных (ссылочная целостность), управлением транзакциями.
Достоверность данных может быть нарушена при их вводе в БД или при неправомерных действиях процедур обработки данных, получающих и заносящих в БД неправильные данные. Для повышения достоверности данных в системе используются ограничения целостности, которые служат для определения неверных данных. Так, во всех современных СУБД проверяется соответствие вводимых данных их типу, описанному при создании структуры.
Система не позволит ввести символ в поле числового типа, не позволит ввести недопустимую дату и т.п. В развитых системах ограничения целостности описывает программист, исходя из содержательного смысла задачи, и их проверка осуществляется при каждом обновлении данных. Более подробно разные аспекты логической целостности базы данных будут рассматриваться в последующих разделах.
Данные в БД хранятся в разных таблицах, которые связаны между собой. Для поддержки заданных принципов взаимосвязи данных в СУБД существуют правила ссылочной целостности. Например, между двумя связанными таблицами может быть установлено правило: при удалении записей в родительской таблице автоматически осуществляется каскадное удаление всех записей из дочерней таблицы, связанных с удаляемой записью.
Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД. В состав транзакции может входить несколько команд изменения базы данных, но либо выполняются все эти команды, либо не выполняется ни одна. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении) транзакция остается незавершенной, то она отменяется, т.е. происходит откат транзакции.
Обеспечение физической целостности базы данных
СУБД, кроме ведения собственно базы данных, ведет также журнал транзакций. Ведение журнала изменений в БД (журнализация изменений) и создание резервных копий, дают возможность восстановить данные при наличии аппаратных сбоев, а также ошибок программного обеспечения.
Управление полномочиями пользователей на доступ к базе данных.
Разные пользователи могут иметь разные полномочия по работе с данными (некоторые данные должны быть недоступны; определенным пользователям не разрешается обновлять данные и т.п.). В СУБД предусматриваются механизмы разграничения полномочий доступа, основанные либо на принципах паролей, либо на описании полномочий.
Обеспечение одновременного доступа к данным для нескольких пользователей.
Достаточно часто может иметь место ситуация, когда несколько пользователей одновременно выполняют операцию обновления одних и тех же данных. Это может привести к нарушению логической целостности данных. Для повышения эффективности работы с базой данных следует «изолировать» пользователей друг от друга. Для этого СУБД используют блокировки.
Блокировкой называется временное ограничение на выполнение некоторых операций обработки данных.
Существуют разные типы блокировок. Блокировка может быть наложена как на всю базу данных, так и на отдельную строку таблицы.
5. Виды архитектуры информационной системы
Архитектурой информационной системы называется концепция, согласно которой взаимодействуют компоненты информационной системы.
Любая информационная система включает в себя три компонента:
- управление данными;
- бизнес-логику;
- пользовательский интерфейс.
Данные хранятся в базах данных, а управление ими осуществляется с помощью системы управления базами данных. Бизнес-логика определяет правила, по которым обрабатываются данные. Она реализуется набором процедур, написанных на различных языках программирования. Пользователь работает с интерфейсом, где логика работы ИС представлена в виде элементов управления – полей, кнопок, списков, таблиц и т.д.
Однако, эти три компонента в разных ИС взаимодействуют друг с другом различными способами.
Существуют следующие виды архитектур ИС:
- централизованная;
- файл-серверная;
- клиент-серверная;
- трехслойная.
5.1 Централизованная архитектура
При использовании этой архитектуры база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере (рис. 5). Для такого способа организации не требуется поддержки сети и все сводится к автономной работе.
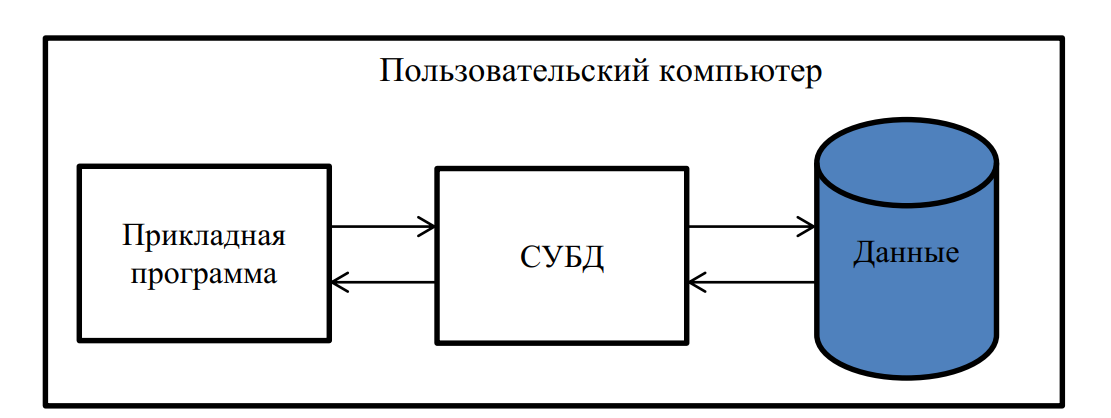
Рис. 5. Централизованная архитектура ИС
Многопользовательская технология работы обеспечивалась либо режимом мультипрограммирования (одновременно могли работать процессор и внешние устройства – например, пока в прикладной программе одного пользователя шло считывание данных из внешней памяти, программа другого пользователя обрабатывалась процессором), либо режимом разделения времени (пользователям по очереди выделялись кванты времени на выполнении их программ).
Такая технология была распространена в период «господства» больших ЭВМ (IBM- 370, ЕС-1045, ЕС-1060). Основным недостатком этой модели является резкое снижение производительности при увеличении числа пользователей.
5.2. Файл-серверная архитектура
Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры «файл-сервер» (рис. 6).
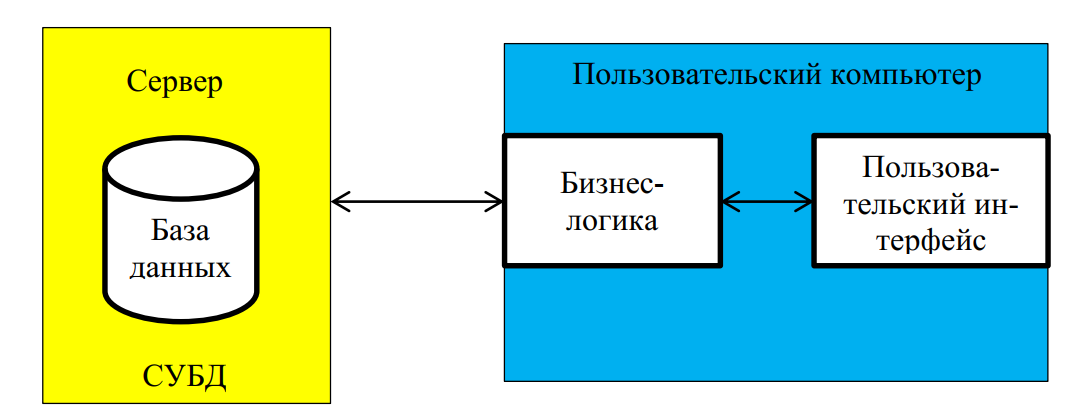
Рис. 6. Файл-серверная архитектура ИС
Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных. Компьютеры пользователей соединены с сервером сетью, поэтому доступ к данным, могут получить несколько пользователей одновременно.
В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных.
Недостатки архитектуры с файловым сервером вытекают, главным образом, из того, что данные хранятся в одном месте, а обрабатываются в другом. Их нужно передавать по сети, что приводит к очень высоким нагрузкам на сеть и резкому снижению производительности приложения при увеличении числа одновременно работающих клиентов. Например, предположим, что в базе данных на сервере хранится список продаж товаров торговой фирмы.
За год было осуществлено 20000 продаж. Пользователю нужно получить сумму продаж за каждый месяц. Для решения этой задачи пользователь должен запросить данные всех 20000 продаж с сервера по сети, после чего на пользовательском компьютере выполнится процедура, которая осуществит подсчет сумм продаж в каждом месяце. Результатом процедуры будет 12 строк. Таким образом, чтобы получить 12 строк придется передать по сети 20000 строк.
Вторым важным недостатком такой архитектуры является децентрализованное решение проблем целостности, из-за их несогласованной обработки разными пользователями.
5.3. Клиент-серверная архитектура
До определенного момента на СУБД возлагались лишь задачи хранения данных и организации доступа к ним. С развитием технологий в состав СУБД разработчики стали включать новый компонент – процедурный язык программирования. С его помощью в СУБД стало возможным создавать процедуры для обработки данных, которые можно вызывать повторно. Такие процедуры называются хранимыми процедурами. Наличие хранимых процедур дало возможность осуществлять некоторую часть обработки данных на сервере.
Таким образом, архитектура «клиент – сервер» разделяет функции приложения пользователя (называемого клиентом) и сервера (рис. 7). Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL.
При этом ресурсы клиентского компьютера не участвуют в физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Так как клиентскому приложению посылается результат выполнения запроса, по сети «путешествуют» только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных.
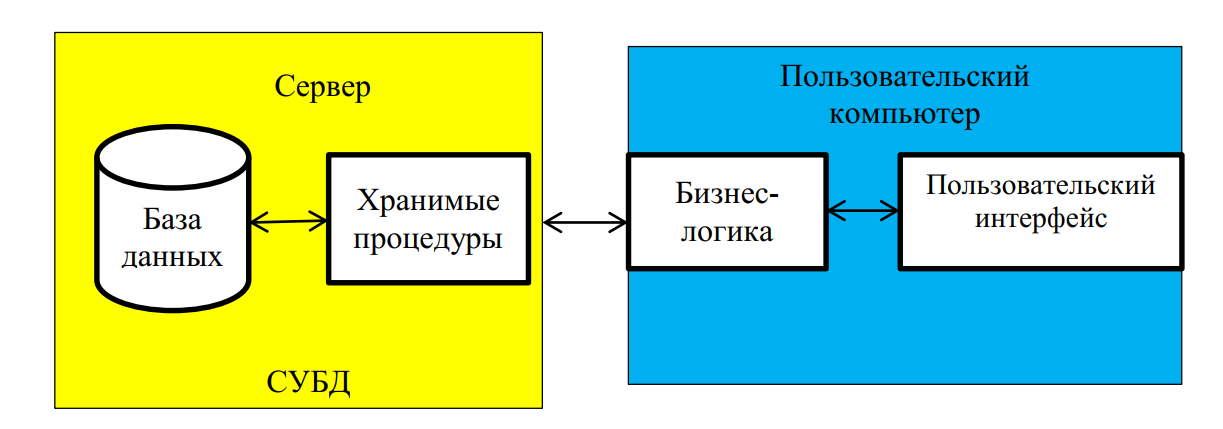
Рис. 7. Клиент-серверная архитектура ИС
Все это повышает быстродействие системы и снижает время ожидания результата запроса. Рассмотрим пример из параграфа 5.2 в условиях клиент-серверной архитектуры. Пользователь отправит на сервер запрос, который запустит процедуру. Процедура выполнится непосредственно на сервере. Она подсчитает сумму продаж за каждый месяц и отправит полученные 12 строк по сети на клиентский компьютер. Таким образом, произойдет существенная экономия трафика: вместо 20000 строк будет передано по сети всего 12.
При выполнении запросов сервером существенно повышается степень безопасности данных, поскольку правила целостности данных определяются в базе данных на сервере и являются едиными для всех приложений, использующих эту БД. Таким образом, исключается возможность определения противоречивых правил поддержания целостности.
Клиент-серверная архитектура позволяет разгрузить сеть и поддерживать непротиворечивость данных за счет их централизованной обработки. Однако, языки хранимых процедур не приспособлены для полноценной реализации бизнес-логики. Поэтому бизнес-логика в клиент-серверных ИС по-прежнему реализуется на клиентских компьютерах.
В архитектуре «клиент – сервер» работают так называемые «промышленные» СУБД.
Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу информационных систем масштаба среднего и крупного предприятия, организации, банка. К разряду промышленных СУБД принадлежат MS SQL Server, Oracle, Informix, Sybase, DB2, InterBase и ряд других.
Рассмотрим основные достоинства данной архитектуры по сравнению с архитектурой «файл-сервер»:
- Существенно уменьшается сетевой трафик.
- Уменьшается сложность клиентских приложений (большая часть нагрузки ложится на серверную часть), а, следовательно, снижаются требования к аппаратным мощностям клиентских компьютеров.
- Существенно повышается целостность и безопасность БД.
К числу недостатков можно отнести более высокие финансовые затраты на аппаратное и программное обеспечение, а также то, что большое количество клиентских компьютеров, расположенных в разных местах, вызывает определенные трудности со своевременным обновлением клиентских приложений на всех компьютерах-клиентах. Тем не менее, архитектура «клиент – сервер» хорошо зарекомендовала себя на практике, в настоящий момент существует и функционирует большое количество БД, построенных в соответствии с данной архитектурой.
5.4. Трехуровневая архитектура
Рассмотрев архитектуру «клиент – сервер», можно заключить, что она является 2-звенной: первое звено – клиентское приложение, второе звено – сервер БД + сама БД. Все недостатки клиентсерверной архитектуры связаны с тем, что на клиентском компьютере лежит слишком большая нагрузка, которую можно было бы перенести на сервер.
Поэтому дальнейшее развитие технологий двигалось в направлении переноса нагрузки с клиентских компьютеров на сервер. В дополнение к хранимым процедурам разработчики стали использовать серверные языки программирования. Это дало возможность создавать в ИС промежуточный уровень — сервер приложений.
В трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений (рис. 8). При этом клиентским приложениям остается лишь пользовательский интерфейс.
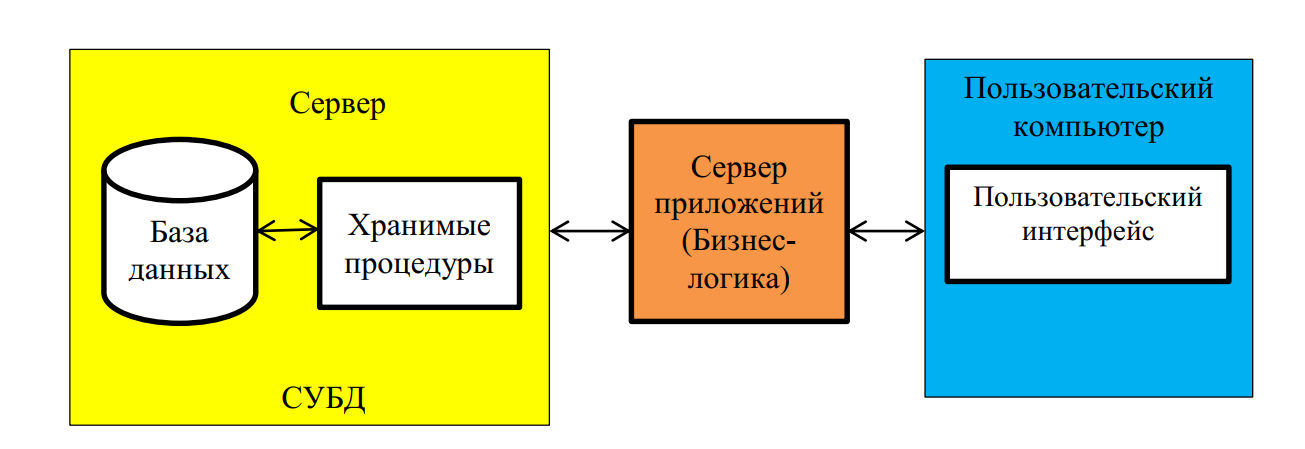
Рис. 8. Трехуровневая архитектура ИС
Теперь при изменении бизнес-логики более нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей.
Недостатком трехзвенной архитектуру являются высокие расходы на администрирование и обслуживание серверной части.
6. Организация БД. Трехуровневое представление данных
Первая попытка создания стандартной терминологии и общей архитектуры представления данных была предпринята в 1971 г. по результатам конференции по языкам и системам данных CODASYL. При национальном институте стандартов США был создан комитет планирования стандартов и норм — ANSI/SPARC (ANSI — American National Standard Institute, SPARC — Standards Planning and
Requirements Committee). Этот комитет в 1975 г. предложил обобщенную трёхуровневую модель представления данных, включающую концептуальный, внешний и внутренний уровни (рис. 9).
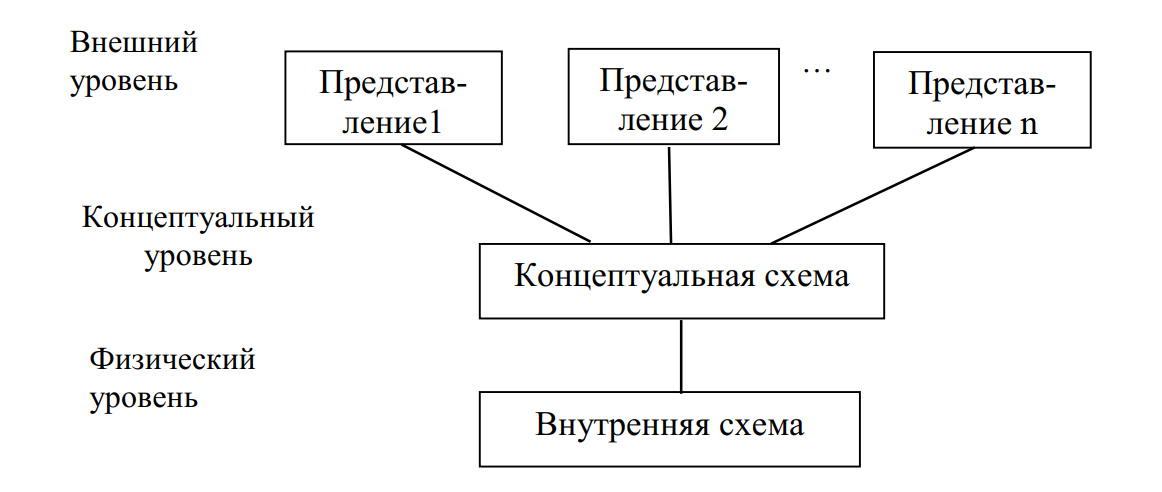
Рис. 9. Трехуровневая организация БД
Рассмотрим суть каждого уровня.
Внешний уровень отражает требования к данным с точки зрения конкретного пользователя (или приложения), т.е. лица, решающего узкую задачу на конкретном рабочем месте. Так как с базой данных работают несколько пользователей, то внешний уровень состоит из нескольких различных внешних представлений базы данных. Каждый пользователь видит и обрабатывает только те данные, которые ему необходимы.
Другие данные, которые ему неинтересны, также могут быть представлены в базе данных, но пользователь может даже не подозревать об их существовании. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров. Описание представления данных для группы пользователей называется внешней схемой.
Создание базы данных предполагает интеграцию данных, предназначенных для решения нескольких прикладных задач разных пользователей. Соответственно, при интеграции данных должны учитываться требования к данным каждого пользователя, основанные на его представлении о данных и связях между ними. Далее эти требования должны обобщаться в единое представление, которое и будет служить основой для построения единой базы данных.
Концептуальный уровень отражает обобщенное представление всех пользователей о данных, которое является моделью предметной области, создаваемой база данных. Описание этого представления называется концептуальной схемой или схемой БД. Концептуальная схема представляет информационное описание предметной области с учетом логических взаимосвязей, поэтому её еще называют инфологической (информационно-логической) моделью.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Внутренний уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности, обеспечения экономного использования дискового пространства, организации мероприятий по защите данных. Он содержит детальное описание структур данных и физической организации файлов с данными, описание вспомогательных структур (индексов), используемых для ускорения поиска, сведения о распределении дискового пространства для хранения данных и индексов и т.д. Описание БД на внутреннем уровне называется внутренней схемой или схемой хранения.
Как показывает изучение трехуровневой архитектуры БД, концептуальная схема является самым важным уровнем представления базы данных. Она поддерживает все внешние представления, а сама поддерживается средствами внутренней схемы. Внутренняя схема является всего лишь физическим воплощением концептуальной схемы. Именно концептуальная схема призвана быть полным и точным представлением требований к данным в рамках некоторой предметной области.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных, которая означает, что изменения на нижних уровнях никак не влияют на верхние уровни. Различают два типа независимости от данных: логическую и физическую.
Логическая независимость от данных означает полную защищенность внешних представлений от изменений, вносимых на концептуальном уровне. Ясно, что пользователи, для которых эти изменения предназначались, должны знать о них, но очень важно, чтобы другие пользователи даже не подозревали об этом. Таким образом, логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных.
Физическая независимость от данных означает защищенность концептуальной схемы от изменений способов организации базы данных в памяти ЭВМ, вносимых на внутреннем уровне. Таким образом, физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных.
Таким образом, трехуровневая архитектура позволяет добиться следующего:
- Каждый пользователь имеет возможность обращаться к одним и тем же данным, используя свое собственное представление о них.
- Каждый пользователь имеет возможность изменять свое представление о данных, причем это изменение не оказывает влияния на других пользователей.
- Пользователи не зависят от особенностей хранения в ней данных.
- Администратор базы данных имеет возможность изменять структуру хранения данных в базе, не оказывая влияния на пользовательские представления.
- Внутренняя структура базы данных не зависит от переноса базы данных на новое устройство памяти.
- Администратор базы данных имеет возможность изменять концептуальную структуру базы данных без какого-либо влияния на всех пользователей.
7. Понятие модели данных и виды моделей
Для формирования представления о данных, их составе и использовании в конкретных условиях служат различные модели данных. Поэтому центральным понятием в области баз данных является понятие модели.
Модель – это некоторая абстракция представления предметной области, отражающая только избранные детали.
Предметная область – это область применения конкретной БД. Таким образом, при решении конкретных задач реальная действительность воспроизводится с существенными ограничениями, зависящими от области деятельности, поставленных целей и мощности вычислительных средств, т.е. в БД находят отражение только те факты о предметной области, которые необходимы для функционирования информационной системы, в состав которой входит БД.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. Модели данных, которые используются в теории баз данных, приведены на рис. 10.
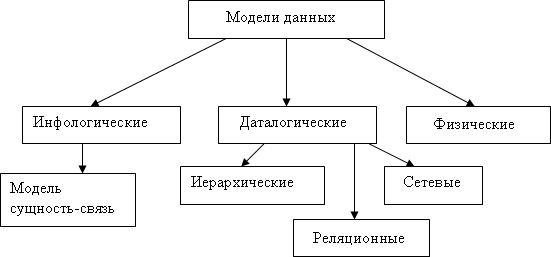
Рис. 10. Модели данных
Модель данных на внутренним уровне оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве внутренних моделей используются различные методы размещения данных, основанные на файловых структурах: это организация
файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных.
Модель данных, используемая на концептуальном уровне, должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или концептуальными.
Данная модель представляет собой набор конструкций, которые описывают структуру БД в виде совокупности сущностей, атрибутов и связей.
При разработке инфологической модели базы данных должны быть решены следующие вопросы:
- о каких объектах или явлениях реального мира требуется накапливать и обрабатывать информацию в БД;
- какие их основные характеристики;
- как связаны между собой эти объекты.
Таким образом, при создании инфологической модели выделяется часть реального мира, определяющая информационные потребности БД, т.е. ее предметную область.
Модели внешнего уровня называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Следует особо отметить, что концептуальная модель данных не зависит от конкретной СУБД или аппаратной платформы, которая используется для реализации БД. Поэтому в дальнейшем в процессе проектирования баз данных необходимо выполнить преобразование концептуальной модели в модель данных конкретной СУБД. Такие модели называются даталогическими.
Даталогические модели описывают логическую структуру данных, хранимых в базе, и поддерживаются конкретной СУБД.
Даталогические модели делятся на фактографические и документальные. Документальные модели служат для описания слабоструктурированной информации в виде текстов на естественном языке.
К числу классических относятся следующие фактографические модели данных:
- иерархическая,
- сетевая,
- реляционная.
Кроме того, в последние годы появились и стали более активно внедряться на практике многомерная и объектно-ориентированная модели данных.