
Построение распределенных систем обработки информации
1. Понятие распределенной информационной системы
Информационные технологии – это процессы, использующие совокупность средств и методов сбора, обработки и передачи данных для получения информации нового качества о состоянии объекта, процесса или явления (нового информационного продукта).
Информационная система (база) – это организационно-упорядоченная взаимосвязанная совокупность средств и методов информационных технологий, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели. Информационные системы создаются для обеспечения взаимодействия информационных процессов в природе и обществе, и связанного с этим взаимодействием обмена какими-либо сигналами или сведениями в рамках организационно-технической системы.
Сами же информационные процессы (ИП) представляют собой совокупность взаимосвязанных и взаимообусловленных процессов выявления, отбора, формирования из совокупности сведений информации, ее ввода в техническую систему, анализа, обработки, хранения и передачи.
В качестве основных технических средств обработки и передачи информации в информационных системах выступают компьютеры и средства связи.
Под распределенной информационной системой (базой) понимается неограниченное количество баз данных, дистанционно отдаленных друг от друга, функционирующих и осуществляющих обмен данными по единым правилам, определенным централизованно для всех баз данных, входящих в распределенную информационную базу. Приведем также несколько альтернативных определений распределенных информационных систем.
- Распределенная информационная система – информационная система, объекты данных и/или процессы которой физически распределяются на две или более компьютерные системы.
- Распределенная система – это набор независимых компьютеров, представляющийся их пользователям единой объединенной системой.
- Распределенная система – это такая система, в которой взаимодействие и синхронизация программных компонентов, выполняемых на независимых сетевых компьютерах, осуществляется посредством передачи сообщений.
- Распределенная система – набор независимых компьютеров, не имеющих общей совместно используемой памяти и общего единого времени (таймера) и взаимодействующих через коммуникационную сеть посредством передачи сообщений, где каждый компьютер использует свою собственную оперативную память и на котором выполняется отдельный экземпляр своей операционной системы. однако эти операционные системы функционируют совместно, предоставляя свои службы друг другу для решения общей задачи.
- Термин «распределенная система» описывает широкий спектр систем от слабо связанных многомашинных комплексов, представляемых, например, набором персональных компьютеров, объединенных в сеть, до сильно связанных многопроцессорных систем.
Отметим также шуточное определение распределенной информационной системы, принадлежащее американскому ученому в области теории вычислительных систем Лесли Лэмпорту. Согласно его утверждению, вы понимаете, что пользуетесь распределенной системой, когда поломка компьютера, о существовании которого вы даже не подозревали, приводит к останову всей системы, а для вас – к невозможности выполнить свою работу.
Большинство современных распределенных информационных систем обладают следующими общими признаками.
- Отсутствие единого времени для компонентов распределенной системы. Это важное предположение для решения задач проектирования и построения распределенных систем. Оно характеризует территориальное распределение компонентов системы, а именно процессоров, входящих в ее состав, но что более важно, из него следует отсутствие синхронности в их работе.
- Отсутствие общей памяти. Это ключевая характеристика, из которой следует необходимость обмена сообщениями между программными компонентами распределенной системы для их взаимодействия и синхронизации. Кроме того, эта характеристика подразумевает отсутствие единого для всех процессоров физического времени
- Географическое распределение. Вполне естественно, что чем сильнее удалены процессоры друг от друга территориально, тем понятнее, что система будет рассматриваться как распределенная. Однако совсем не обязательно, чтобы компьютеры были объединены в глобальную вычислительную сеть (ГВС). В последнее время кластер из обыкновенных рабочих станций, соединенных с помощью локальной вычислительной сети (ЛВС), также все чаще рассматривается как небольшая распределенная система. При этом все оборудование такой распределенной системы может находиться в одном или нескольких соседних зданиях. Подобные кластеры становятся все популярнее из-за относительно низкой стоимости входящих в нее компонентов с одной стороны и неплохой производительности – с другой.
- Независимость и гетерогенность. Компьютеры, входящие в состав распределенной системы слабо связаны в том смысле, что они могут иметь различный состав и различную производительность и, следовательно, обеспечивать различное время выполнения идентичных задач. Обычно они не являются частями одной специализированной системы, но функционируют совместно, предоставляя свои службы друг другу для выполнения общей задачи. Более того, в общем случае на компьютерах, составляющих распределенную систему, могут выполняться различные операционные системы.
За последние несколько лет распределенные системы становились все более популярными и их роль только возрастала. Среди основных причин роста их значимости можно выделить следующие:
- Географически распределенная вычислительная среда. Сегодня в большинстве случаев сама вычислительная среда по своей природе представляет собой территориально распределенную систему. В качестве примера можно привести банковскую сеть. Каждый банк обслуживает счета своих клиентов и обрабатывает операции с ними. В случае же перевода денег из одного банка в другой требуется осуществление межбанковской транзакции и взаимодействие систем банков друг с другом. Другим примером географически распределенной вычислительной среды является всем хорошо знакомая сеть Интернет.
- Требование увеличения производительности вычислений. Быстродействие традиционных однопроцессорных систем стремительно приближается к своему пределу. Различные архитектуры (такие как суперскалярная архитектура, матричные и векторные процессоры, однокристальные многопроцессорные системы) призваны увеличивать производительность вычислительных систем за счет различных механизмов параллельного исполнения команд. Однако все эти приемы способны повысить производительность максимум в десятки раз по сравнения с классическими последовательными решениями. Кроме того, масштабируемость подобных подходов оставляет желать лучшего. Чтобы повысить производительность в сотни или тысячи раз и при этом обеспечивать хорошую масштабируемость решения необходимо свести воедино многочисленные процессоры и обеспечить их эффективное взаимодействие. Этот принцип реализуется в виде больших многопроцессорных систем и многомашинных комплексов.
- Совместное использование ресурсов. Важной целью создания и использования распределенных систем является предоставление пользователям (и приложениям) доступа к удаленным ресурсам и обеспечение их совместного использования. В данной формулировке термин ресурс относится как к компонентам аппаратного обеспечения вычислительной системы, так и к программным абстракциям, с которыми работает распределенная система. Например, пользователь компьютера 1 может использовать дисковое пространство компьютера 2 для хранения своих файлов. Или приложение А может использовать свободную вычислительную мощность нескольких компьютеров для ускорения собственных расчетов. Распределенные базы данных и распределенные системы объектов могут быть отличным примером совместного использования программных компонентов, когда соответствующие программные абстракции распределены по нескольким компьютерам и согласованно обслуживаются несколькими процессами, образующими распределенную систему.
- Отказоустойчивость. В традиционных «нераспределенных» вычислительных системах, построенных на базе единичного компьютера (возможно высокопроизводительного), выход из строя одного из его компонентов обычно приводит к неработоспособности всей системы. Такой сбой в одном или нескольких компонентах системы называют частичным отказом, если он не затрагивает другие компоненты. Характерной чертой распределенных систем, которая отличает их от единичных компьютеров, является устойчивость к частичным отказам, т.е. система продолжает функционировать после частичных отказов, правда, незначительно снижая при этом общую производительность. Подобная возможность достигается за счет избыточности, когда в систему добавляется дополнительное оборудование (аппаратная избыточность) или процессы (программная избыточность), которые делают возможной правильное функционирование системы при неработоспособности или некорректной работе некоторых из ее компонентов. В этом случае распределенная система пытается скрывать факты отказов или ошибок в одних процессах от других процессов.
Эффективная распределенная система должна обладать следующими свойствами: прозрачность, открытость, безопасность, масштабирование. Однако стоит отметить, что, несмотря на кажущуюся простоту и очевидность перечисленных свойств, их реализация на практике часто представляет собой непростую задачу.
Прозрачность
Под прозрачностью распределенной системы понимают ее способность скрывать свою распределенную природу, а именно, распределение процессов и ресурсов по множеству компьютеров, и представляться для пользователей и разработчиков приложений в виде единой централизованной компьютерной системы. Стандарты эталонной модели для распределенной обработки в открытых системах Reference Model for Open Distributed Processing
(RM-ODP) определяют несколько типов прозрачности. Наиболее важные из них перечислены ниже.
- Прозрачность доступа. Вне зависимости от способов доступа к ресурсам и их внутреннего представления, обращения к локальным и удаленным ресурсам осуществляется одинаковым образом. На базовом уровне скрывается разница архитектур вычислительных платформ, но, что более важно, достигается соглашение о том, как ресурсы разнородных машин, будут представляться пользователям распределенной системы единым образом. В качестве примера можно привести прикладной программный интерфейс (англ. application programming interface, API) для работы с файлами, хранящимися на множестве компьютеров различных архитектур, который предоставляет одинаковые вызовы операций как с локальными, так и с удаленными файлами.
- Прозрачность местоположения. Позволяет обращаться к ресурсам без знания их физического местоположения. В этом случае имя запрашиваемого ресурса не должно давать никакого представления о том, где ресурс расположен. Поэтому важную роль для обеспечения прозрачности местоположения играет именование ресурсов. Например, чтобы отправить электронное сообщение на адрес user@company.com не требуется знать физического местоположения получателя, его почтового ящика или почтового сервера. В свою очередь обращение к файлу \\server\foo подразумевает знание имени сервера, на котором он расположен, а значит, не является полностью прозрачным с точки зрения местоположения.
- Прозрачность перемещения. Перемещение ресурса или процесса в другое физическое местоположение остается незаметным для пользователя распределенной системы. Здесь стоит отметить, что выполнение требования прозрачности местоположения не гарантирует прозрачности перемещения. Другими словами, если распределенная система скрывает местоположение ресурса, это не означает, что его можно сменить незаметно для пользователя. Например, распределенные файловые системы позволяют монтировать файловые системы удаленных компьютеров в локальное пространство имен клиента, предоставляя единое дерево каталогов и тем самым обеспечивая прозрачность местоположения. Однако если файлы на удаленных компьютерах будут перемещены в другое место, в большей части распределенных файловых систем они станут недоступны для пользователя.
- Прозрачность смены местоположения. Более строгое по отношению к предыдущему требование скрыть факт перемещения ресурса вовремя его использования. Примером могут служить мобильные пользователи, использующие сотовые телефоны. В этом случае, если рассматривать вызывающего абонента в качестве пользователя распределенной системы, а вызываемого – в качестве ее ресурса, то система будет прозрачной с точки зрения смены местоположения. Действительно, перемещение «ресурса» из соты в соту в процессе разговора остается незаметным для звонящего.
- Прозрачность репликации. Если для повышения доступности или увеличения производительности используется несколько копий ресурса (реплик), этот факт остается скрытым от пользователя, и он полагает, что в системе присутствует только один экземпляр ресурса. Для обеспечения прозрачности репликации необходимо, чтобы все реплики имели одно и то же имя, очевидно, не зависящее от местоположения копии ресурса. Таким образом, системы, которые обеспечивают прозрачность репликации, также должны поддерживать и прозрачность местоположения.
- Прозрачность одновременного доступа. Позволяет нескольким пользователям (конкурирующим процессам) одновременно выполнять операции над общим, совместно используемым ресурсом без взаимного влияния друг на друга. Иначе говоря, скрывается факт использования ресурса другими пользователями (процессами). Стоит отметить, что сам ресурс должен оставаться в непротиворечивом состоянии, что может достигаться, например, с помощью механизма блокировок, когда пользователи (процессы) по очереди получают исключительные права на запрашиваемый ресурс.
- Прозрачность отказов. Подразумевается, что система должна пытаться скрывать частичные отказы, позволяя пользователям и приложениям выполнить свою работу вне зависимости от сбоев в аппаратных или программных компонентах распределенной системы, а также скрывать факт их последующего восстановления. В связи с тем, что любой процесс, компьютер или сетевое соединение могут отказывать независимо от других в произвольные моменты времени, каждый компонент распределенной системы должен быть готов к сбоям в других компонентах и обрабатывать подобные ситуации соответствующим образом.
- Прозрачность сохранности, маскирующая реальную (диск) или виртуальную (оперативная память) сохранность ресурсов. Так, например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохраненных объектов. За сценой в этот момент происходит следующее: сервер баз данных сначала копирует состояние объекта с диска в оперативную память, затем выполняет операцию и, наконец, записывает состояние на устройство длительного хранения. Пользователь, однако, остается в неведении о том, что сервер перемещает данные между оперативной памятью и диском. Сохранность играет важную роль в распределенных системах, однако не менее важна она и для обычных (не распределенных) систем.
Степень прозрачности. Важно отметить, что степень, до которой каждое из перечисленных выше свойств должно быть выполнено, может сильно варьироваться в зависимости от задач построения распределенной системы. Действительно, полностью скрыть распределение процессов и ресурсов вряд ли удастся. Из-за ограничения в скорости передачи сигнала, задержка на обращение к ресурсам, территориально удаленным от клиента, всегда будет больше, чем к ресурсам, расположенным поблизости. Поэтому не каждая система в состоянии или даже должна пытаться скрывать все свои особенности от пользователя. Обычно, это утверждение выражается в поиске компромисса между прозрачностью распределенной системы и ее производительностью.
Например, если для повышения отказоустойчивости в системе присутствуют географически распределенные копии ресурса, то поддержка их идентичного состояния для обеспечения прозрачности репликации потребует гораздо большего времени выполнения каждой операции обновления. Другими словами, каждая операция обновления должна будет распространиться на все реплики до того, как будет разрешена следующая операция с данным ресурсом. Или, например, многие приложения предпринимают несколько последовательных попыток связаться с сервером, пытаясь скрыть его временную недоступность, тем самым замедляя работу системы. Однако, в некоторых случаях, например, если на самом деле сервер вышел из строя, было бы разумнее сразу уведомить пользователя о недоступности ресурса.
Открытость
Согласно определению, принятому комитетом IEEE POSIX 1003.0, открытая система – это система, реализующая открытые спецификации (стандарты) на интерфейсы, службы и поддерживаемые форматы данных, достаточные для того, чтобы обеспечить:
- Возможность переноса разработанного прикладного программного обеспечения на широкий диапазон систем с минимальными изменениями (мобильность приложений, переносимость);
- совместную работу (взаимодействие) с другими прикладными приложениями на локальных и удаленных платформах (интероперабельность, способность к взаимодействию);
- взаимодействие с пользователями в стиле, облегчающим последним переход от системы к системе (мобильность пользователя).
Ключевой момент в этом определении – использование понятия открытая спецификация, которое, в свою очередь, определяется как общедоступная спецификация, которая поддерживается открытым, гласным согласительным процессом, направленным на постоянную адаптацию к новым технологиям, и соответствует стандартам.
Согласно этому определению открытая спецификация не зависит от конкретной технологии, т.е. не зависит от конкретных технических и программных средств или продуктов отдельных производителей.
Открытая спецификация одинаково доступна любой заинтересованной стороне. Более того, открытая спецификация находится под контролем общественного мнения, поэтому заинтересованные стороны могут принимать участие в ее развитии.
В контексте распределенных систем приведенное выше определение означает, что свойство открытости не может быть достигнуто, если спецификация и описание ключевых интерфейсов программных компонентов системы не доступны для разработчиков. Одним словом, ключевые интерфейсы должны быть описаны и опубликованы. Важно отметить, что здесь в первую очередь подразумеваются интерфейсы внутренних компонентов системы, а не только интерфейсы верхнего уровня, с которыми работают пользователи и приложения. При этом синтаксис интерфейсов, т.е. Имена доступных функций, типы передаваемых параметров, возвращаемых значений и т.п., обычно описывается посредством языка определения интерфейсов. В свою очередь семантика интерфейсов, т.е. то, что на самом деле делают службы, предоставляющие эти интерфейсы, обычно задается неформально, с помощью естественного языка.
Подобное описание позволяет произвольному процессу, нуждающемуся в определенной службе, обратиться к другому процессу, реализующему эту службу, через соответствующий интерфейс. Кроме того, такой подход позволяет создавать несколько различных реализаций одной и той же службы, которые с точки зрения внешних процессов будут работать абсолютно одинаково. Как следствие, несколько реализаций программных компонентов (возможно, от различных производителей) могут взаимодействовать и работать совместно, образуя единую распределенную систему. Таким образом, достигается свойство интероперабельности или, другими словами, способности к взаимодействию. Более того, в этом случае прикладное приложение, разработанное для распределенной системы A, может без изменений выполняться в распределенной системе B, реализующей те же интерфейсы, что и А. То есть достигается свойство переносимости.
Еще одно важное преимущество заключается в том, что открытая распределенная система потенциально может быть образована из разнородного аппаратного и программного обеспечения (опять-таки, возможно, от разных производителей). При этом добавление новых компонентов или замена существующих может осуществляться относительно легко, не затрагивая других компонентов. На аппаратном уровне это выражается в способности простого подключения к системе дополнительных компьютеров или замены существующих на более мощные. На программном – в возможности простого внедрения новых служб или новых реализаций уже существующих. Другими словами, важным свойством открытой распределенной системы является расширяемость.
Масштабируемость
В общем случае масштабируемость определяют, как способность вычислительной системы эффективно справляться с увеличением числа пользователей или поддерживаемых ресурсов без потери производительности и без увеличения административной нагрузки на ее управление. При этом систему называют масштабируемой, если она способна увеличивать свою производительность при добавлении новых аппаратных средств. Другими словами, под масштабируемостью понимают способность системы расти вместе с ростом нагрузки на нее.
Масштабируемость является важным свойством вычислительных систем, если им может потребоваться работать под большой нагрузкой, поскольку означает, что вам не придется начинать с нуля и создавать абсолютно новую информационную систему. Если у вас есть масштабируемая система, то, скорее всего, вам удастся сохранить то же самое программное обеспечение, попросту нарастив аппаратную часть.
Для распределенных систем обычно выделяют несколько параметров, характеризующих их масштаб: количество пользователей и количество компонентов, составляющих систему, степень территориальной отдаленности сетевых компьютеров системы друг от друга и количество административных организаций, обслуживающих части распределенной системы. Поэтому масштабируемость распределенных систем также определяют по соответствующим направлениям:
- Нагрузочная масштабируемость. Способность системы увеличивать свою производительность при увеличении нагрузки путем замены существующих аппаратных компонентов на более мощные или путем добавления новых аппаратных средств. При этом первый случай увеличения производительности каждого компонента системы с целью повышения общей производительности называют вертикальным масштабированием, а второй, выражающийся в увеличении количества сетевых компьютеров (серверов) распределенной системы – горизонтальным масштабированием.
- Географическая масштабируемость. Способность системы сохранять свои основные характеристики, такие как производительность, простота и удобство использования, при территориальном разнесении ее компонентов от более локального взаимного расположения до более распределенного.
- Административная масштабируемость. Характеризует простоту управления системой при увеличении количества административно независимых организаций, обслуживающих части одной распределенной системы.
Построение масштабируемых систем подразумевает решение широкого круга задач и часто сталкивается с ограничениями реализованных в вычислительных системах централизованных служб, данных и алгоритмов. А именно, многие службы централизованы в том смысле, что они реализованы в виде единственного процесса и могут выполняться только на одном компьютере (сервере). Проблема такого подхода заключается в том, что при увеличении числа пользователей или приложений, использующих эту службу, сервер, на котором она выполняется, станет узким местом и будет ограничивать общую производительность. Если даже предположить возможность неограниченного увеличения мощности такого сервера (вертикальное масштабирование), то тогда ограничивающим фактором станет пропускная способность линий связи, соединяющих его с остальными компонентами распределенной системы. Аналогично, централизация данных требует централизованной обработки, приводя к тем же самым ограничениям.
В качестве примера преимуществ децентрализованного подхода можно привести службу доменных имен, которая на сегодняшний день является одной из самых больших распределенных систем именования. Служба DNS используется в первую очередь для поиска IPадресов по доменному имени и обрабатывает миллионы запросов с компьютеров по всему миру. При этом распределенная база данных DNS поддерживается с помощью иерархии DNS-серверов, взаимодействующих по определенному протоколу. Если бы все данные DNS централизовано хранились бы на единственном сервере, и каждый запрос на интерпретацию доменного имени передавался бы на этот сервер, воспользоваться такой системой в масштабах всего мира было бы невозможно.
Отдельно стоит отметить ограничения, создаваемые применением централизованных алгоритмов. Дело в том, что централизованные алгоритмы для своей работы требуют получения всех входных данных и только после этого производят соответствующие операции над ними, а уже затем распространяют результаты всем заинтересованным сторонам. С этой точки зрения проблемы использования централизованных алгоритмов эквивалентны рассмотренным выше проблемам централизации служб и данных. Поэтому для достижения хорошей масштабируемости следует применять распределенные алгоритмы, предусматривающие параллельное выполнение частей одного и того же алгоритма независимыми процессами.
В отличие от централизованных алгоритмов, распределенные алгоритмы обладают следующими свойствами, которые на самом деле значительно усложняют их проектирование и реализацию:
- Отсутствие знания глобального состояния. Как уже было сказано, централизованные алгоритмы обладают полной информацией о состоянии всей системы и определяют следующие действия, исходя из ее текущего состояния. В свою очередь, каждый процесс, реализующий часть распределенного алгоритма, имеет непосредственный доступ только к своему состоянию, но не к глобальному состоянию всей системы. Соответственно, процессы принимают решения только на основе своей локальной информации. Следует отметить, что информацию о состоянии других процессов в распределенной системе каждый процесс может получить только из пришедших сообщений, и эта информация может оказаться устаревшей на момент получения. Аналогичная ситуация имеет место в астрономии: знания об изучаемом объекте (звезде / галактике) формируются на основании светового и прочего электромагнитного излучения, и это излучение дает представление о состоянии объекта в прошлом. Например, знания об объекте, находящемся на расстоянии пяти тысяч световых лет, являются устаревшими на пять тысяч лет.
- Отсутствие общего единого времени. События, составляющие ход выполнения централизованного алгоритма полностью упорядочены: для любой пары событий можно с уверенностью утверждать, что одно из них произошло раньше другого. При выполнении распределенного алгоритма вследствие отсутствия единого для всех процессов времени, события нельзя считать полностью упорядоченными: для некоторых пар событий мы можем утверждать, какое из них произошло раньше другого, для других – нет.
- Отсутствие детерминизма. Централизованный алгоритм чаще всего определяется как строго детерминированная последовательность действий, описывающая процесс преобразования объекта из начального состояния в конечное. Таким образом, если мы будем запускать централизованный алгоритм на выполнение с одним и тем же набором входных данных, мы будем получать один и тот же результат и одинаковую последовательность переходов из состояния в состояние. В свою очередь выполнение распределенного алгоритма носит недетерминированный характер из-за независимого исполнения процессов с различной и неизвестной скоростью, а также из-за случайных задержек передачи сообщений между ними. Поэтому, несмотря на то, что для распределенных систем может быть определено понятие глобального состояния, выполнение распределенного алгоритма может лишь ограниченно рассматриваться как переход из одного глобального состояния в другое, т.к. для этого же алгоритма выполнение может быть описано другой последовательностью глобальных состояний. Такие альтернативные последовательности обычно состоят из других глобальных состояний, и поэтому нет особого смысла говорить о том, что то или иное состояние достигается по ходу выполнения распределенного алгоритма.
- Устойчивость к отказам. Сбой в любом из процессов или каналов связи не должен вызывать нарушения работы распределенного алгоритма.
Для обеспечения географической масштабируемости требуются свои подходы. Одна из основных причин плохой географической масштабируемости многих распределенных систем, разработанных для локальных сетей, заключается в том, что в их основе лежит принцип синхронной связи. В этом виде связи клиент, вызывающий какую-либо службу сервера, блокируется до получения ответа. Это неплохо работает, когда взаимодействие между процессами происходит быстро и незаметно для пользователя. Однако при увеличении задержки на обращение к удаленной службе в глобальной системе подобный подход становится все менее привлекательным и, очень часто, абсолютно неприемлемым.
Другая сложность обеспечения географической масштабируемости состоит в том, что связь в глобальных сетях по своей природе ненадежна и взаимодействие процессов практически всегда является двухточечным. В свою очередь, связь в локальных сетях является высоконадежной и подразумевает использование широковещательных сообщений, что значительно упрощает разработку распределенных приложений.
Например, если процессу требуется обнаружить адрес другого процесса, предоставляющего определенную службу, в локальных сетях ему достаточно разослать широковещательное сообщение с просьбой для искомого процесса откликнуться на него. Все процессы получают и обрабатывают это сообщение. Но только процесс, предоставляющий требуемую службу, отвечает на полученную просьбу, указывая свой адрес в ответном сообщении. Очевидно, подобное взаимодействие перегружает сеть, и использовать его в глобальных сетях нереально.
Технологии масштабирования.
В большинстве случаев сложности масштабирования проявляются в проблемах с эффективностью функционирования распределенных систем, вызванных ограниченной производительностью ее отдельных компонентов: серверов и сетевых соединений. Существуют несколько основных технологий, позволяющих уменьшить нагрузку на каждый компонент распределенной системы. К таким технологиям обычно относят распространение, репликацию и кэширование.
Распространение предполагает разбиение множества поддерживаемых ресурсов на части с последующим разнесением этих частей по компонентам системы. Простым примером распространения может служить распределенная файловая система при условии, что каждый файловый сервер обслуживает свой набор файлов из общего адресного пространства. Другим примером может являться уже упоминавшаяся служба доменных имен DNS, в которой все пространство DNS-имен разбивается на зоны, и имена каждой зоны обслуживаются отдельным DNS-сервером.
Важную роль для обеспечения масштабируемости играют репликация и кэширование. Репликация не только повышает доступность ресурсов в случае возникновения частичного отказа, но и помогает балансировать нагрузку между компонентами системы, тем самым увеличивая производительность. Кэширование представляет собой особую форму репликации, когда копия ресурса создается в непосредственной близости от пользователя, использующего этот ресурс. Разница заключается лишь в том, что репликация инициируется владельцем ресурса, а кэширование – пользователем при обращении к этому ресурсу.
Однако стоит отметить, что наличие нескольких копий ресурса приводит к другим сложностям, а именно к необходимости обеспечивать их непротиворечивость (англ. consistency), что, в свою очередь, может отрицательно сказаться на масштабируемости системы. Таким образом, распространение и репликация позволяют распределить поступающие в систему запросы по нескольким ее компонентам, в то время как кэширование уменьшает количество повторных обращений к одному и тому же ресурсу.
Кэширование призвано не только снижать нагрузку на компоненты распределенной системы, но и позволяет скрывать от пользователя задержки коммуникации при обращении к удаленным ресурсам. Подобные технологии, скрывающие задержки коммуникации, важны для достижения географической масштабируемости системы. К ним, в частности, еще можно отнести механизмы асинхронной связи, в которых клиент не блокируется при обращении к удаленной службе, а получает возможность продолжить свою работу сразу после обращения. Позже, когда будет получен ответ, клиентский процесс сможет прерваться и вызвать специальный обработчик для завершения операции.
Сложности разработки распределенных систем
Реализация перечисленных выше свойств распределенных систем на практике представляет непростую задачу. Основные сложности вытекают именно из того факта, что компоненты распределенной системы территориально удалены друг от друга и выполняются на независимых компьютерах в сети. Игнорирование этого обстоятельства на этапе проектирования и разработки соответствующего программного обеспечения часто приводит к существенным проблемам в функционировании распределенной системы.
В этой связи еще в 90-х годах прошлого века сотрудник компании Sun Microsystems Питер Дейч в своей статье «Восемь заблуждений относительно распределенных вычислений» сформулировал основные ошибки, которые допускают при создании распределенных приложений. Он писал: «По существу, каждый, кто впервые создает распределенное приложение, делает следующие предположения. Все они, в конце концов, оказываются ложными, и все вызывают большие неприятности. Вот эти восемь заблуждений:
- Сеть является надежной.
- Задержки передачи сообщений равны нулю.
- Полоса пропускания не ограничена.
- Сеть является безопасной.
- Сетевая топология неизменна.
- Систему обслуживает только один администратор.
- Издержки на транспортную инфраструктуру равны нулю.
- Сеть является однородной».
Важно отметить, что перечисленные предположения как раз и отличают разработку традиционных локальных приложений и систем от распределенных в том смысле, что для нераспределенных приложений большинство из этих допущений остается верным, а проблемы, возникающие при нарушении любого из них, скорее всего, не будут проявляться. Большая же часть принципов, лежащих в основе распределенных систем, имеет непосредственное отношение к перечисленным предположениям.
Поэтому в области распределенных вычислений рассматриваются методы и алгоритмы, позволяющие реализовывать распределенные системы, при условии того, что хотя бы одно из представленных допущений является ложным. Например, понятно, что надежных сетей не существует, что, в свою очередь, приводит к невозможности достижения абсолютной прозрачности отказов. Другим примером может являться необходимость принимать во внимание доступную полосу пропускания и ненулевую задержку обмена сообщениями в сети при реализации и использовании механизмов репликации.
2. Базовая модель и метод «клиент-сервер»
Современная информационная сеть — это сложная распределенная в пространстве техническая система, представляющая собой функционально связанную совокупность программно-технических средств обработки и обмена информацией и состоящая из территориально распределенных информационных узлов (подсистем обработки информации) и физических каналов передачи информации их соединяющих. Такая система в совокупности определяет физическую структуру ИС.
Физическая структура ИС характеризует физическую организацию технических средств ИС и описывает множество пространственно (территориально) распределенных подсистем (информационных узлов), реализующих ту или иную совокупность информационных процессов и оснащенных программно-аппаратными средствами их реализации, соединенных физическими каналами передачи информации (каналами связи), обеспечивающими взаимодействие этих подсистем.
Информационная структура ИС — определяется потребностями отдельных ИП в обмене информацией и представляется совокупностью пространственно распределенных информационных узлов, испытывающих потребность взаимосвязи, и путей доставки информации между ними.
Маршрутная структура ИС описывает множество адресуемых элементов сети (информационных узлов, информационных процессов) и множество реализованных путей доставки информации между этими элементами.
Примером маршрутной структуры для сети передачи данных (ПД) может служить план распределения сообщений (ПРС), представляющий собой совокупность таблиц маршрутов всех узлов сети ПД и определяющий для множества узлов сети множество реализованных маршрутов доставки пакетов.
Архитектура ИС абстрагируясь от конкретной физической реализации элементов сети и конкретной физической структуры, обобщает информационную, логическую, маршрутную структуры, определяет модель ИС, основные компоненты данной модели и функции выполняемые ими. Определяют также понятие функциональной архитектуры сети как часть общей архитектуры, которая для конкретной модели в целом и ее компонент в частности, определяет их функциональную наполненность и принципы функционирования. Физическая структура в свою очередь конкретизирует архитектуру для конкретной информационной сети, построенной с применением конкретных комплексов технических средств и заданных вариантов реализации программно — технических средств.
Примером хорошо проработанной и стандартизованной международной организацией стандартов (МОС) функциональной архитектуры ИС, описывающей правила реализации только подмножества функций взаимосвязи (функций телекоммуникационной сети) при взаимодействии ИП, выполняющих функции содержательной обработки информации в территориально распределенных узлах информационной сети, является семиуровневая архитектура эталонной модели взаимосвязи открытых систем (ЭМВОС).
Последние десятилетия информационные системы строятся по сетевой технологии и на концепции баз данных. Как показывает мировой опыт, это направление останется доминирующим и в ближайшей перспективе, а изменения возможны лишь в подходах к его реализации. Наиболее передовой технологией построения баз данных является технология «клиент-сервер» (рис. 1). Клиент-сервер — это не только архитектура, это – новая парадигма, пришедшая на смену устаревшим концепциям.
Суть ее заключается в том, что клиент (исполняемый модуль) запрашивает те или иные сервисы в соответствии с определенным протоколом обмена данными. При этом нет необходимости в использовании прямых путей операционной системы: клиент их «не знает», ему «известны» лишь имя источника данных и дру гие специальные сведения, используемые для авторизации клиента на сервере. Сервер, который физически может находиться на том же компьютере, а может – на другом конце земного шара, обрабатывает запрос клиента и, произведя соответствующие манипуляции с данными, передает клиенту запрашиваемую порцию данных.
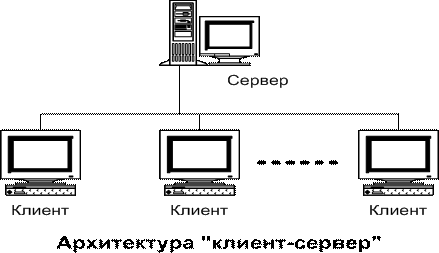
Рис. 1. Архитектура технологии «клиент-сервер»
Эволюционно сложилось несколько моделей и методов данной технологии:
- модель и метод файлового сервера (File Server — FS);
- модель и метод доступа к удаленным данным (Remote Data Access — RDA);
- модель и метод сервера базы данных (DataBase Server — DBS);
- модель и метод сервера приложений (Application Server — AS).
Модель файлового сервера (FS-модель) является базовой для локальных сетей персональных компьютеров (рис. 2). Исторически – это первая архитектура информационных систем. Как исполняемые модули, так и данные размещаются в отдельных файлах операционной системы. Доступ к данным осуществляется путем указания пути (path) и использования файловых операций (открыть, считать, записать). Для хранения данных используется выделенный сервер (отдельный компьютер), который и является файловым сервером. Исполняемые модули хранятся либо на рабочих станциях, либо на файловом сервере. В последнем случае упрощается процедура их администрирования, но при этом возрастают требования к надежности сети.
Суть модели заключена в следующем. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Файловый сервер работает под управлением сетевой операционной системы и осуществляет доступ к информационным ресурсам (то есть к файлам).
На других компьютерах в сети функционирует приложение. Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере. FS-модель послужила фундаментом для расширения возможностей персональных систем управления базами данных (СУБД) в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере.
Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипуляции с данными, отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д.
3. Модификации модели и метода «клиент-сервер»
Модель и метод доступа к удаленным данным
Более технологичные метод и модель доступа к удаленным данным (RDA-модель) (рис. 2) существенно отличаются от FS модели характером доступа к информационным ресурсам. Это обеспечивается операторами специального языка (например, SQL-Structured Query Language). Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру.
На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия, и возвращает клиенту результат, оформленный как блок данных. При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерахклиентах, в то время как ядру СУБД отводится пассивная роль – обслуживание запросов и обработка данных. Такое распределение обязанностей между клиентами и сервером базы данных не догма – сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на вводвывод (как в системах с файловым сервером), а запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели – унификация интерфейса «клиент-сервер» в виде языка SQL.
Модель и метод сервера базы данных
Наряду с RDA-моделью все большую популярность приобретает перспективная модель и метод сервера базы данных (DBS — модель) (рис. 2). Ее основу составляет механизм хранимых процедур – средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД.
Достоинства DBS-модели очевидны: это возможность централизованного администрирования прикладных функций, снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), возможность разделения процедуры между несколькими приложениями, экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры.
К недостаткам модели можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по средствам и функциональным возможностям с языками третьего поколения, такими как C, С++ или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBSмодель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель).
Модель и метод сервера приложений
В модели сервера приложений (AS-модели) процесс, выполняющийся на компьютере-клиенте, как обычно отвечает за интерфейс с пользователем. Прикладные функции выполняются сервером приложения. Все операции над информационными ресурсами выполняются сервером баз данных. RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения (рис. 2).
С развитием интранет — интернет технологий появилась разновидность трехслойной архитектуры на основании использования webтехнологий. В этой разновидности роль сервера приложений играет web-сервер, а в качестве клиента используется стандартный webбраузер. Достоинства – в пониженных требованиях к клиенту и в легкой встраиваемости данной архитектуры в мировые информационные сети. Основной недостаток – известные ограничения, накладываемые на интерфейс пользователя web-браузерами.
Эволюция моделей взаимодействия клиента и сервера показывает, что их совершенствование направлено на снижение трафика в сети, что повышает производительность системы. Однако реализация перечисленных моделей технологии «клиент-сервер» для построения баз данных в распределенных системах с использованием мобильных каналов связи вызывает значительные трудности.
Дело в том, что в отличие от высокоскоростных и надежных локальных сетей, телефонные и особенно радиоканалы имеют намного более низкую пропускную способность при более высоких уровнях помех. Даже в современных системах «клиент — сервер», где минимизируется количество данных, передаваемых между клиентским приложением и сервером БД, применяемые протоколы взаимодействия клиента и сервера оказываются для этих каналов слишком ресурсоемкими, что в итоге приводит к значительному времени отклика при выполнении транзакций. К тому же снижается вероятность их успешного завершения из-за возможного обрыва сеанса. Для примера, только время установления сеанса с сервером может составлять от одной до нескольких минут.
Для разрешения проблемы большого времени отклика, возникающей при работе мобильных пользователей в режиме клиентсервер по медленным каналам связи, используются мобильные агенты (рис. 3). С целью уменьшения обмена по низкоскоростным каналам уже известная модель «клиент-сервер» трансформирована в новую — «клиент-агент-сервер».
4. Программы-агенты и модель «клиент-агент-сервер»
Правильная ориентация в современной компьютерной сети становится чрезвычайно трудной. Решение этой задачи видится учеными и инженерами на пути использования технологии агентов. Предполагается, что по мере развития технологии агентов на узлах сети будет автоматически появляться подобранная с учетом индивидуальных потребностей пользователя информация. Процесс индивидуализации будет происходить с использованием агентов незаметно для пользователя.
Лучшие из агентов смогут самостоятельно обучаться, подражая примеру пользователя. В них будет заложена способность отслеживать последовательность действий, выполняемых во время сеанса просмотра, и накапливать информацию об интересующих вопросах, внося соответствующие коррективы в свое поведение.
В соответствии с определением, данным Э. Таненбаумом, программный агент– это автономный процесс, способный реагировать на среду исполнения и вызывать изменения в среде исполнения, возможно, в кооперации с пользователями или другими агентами.
Агент должен обладать следующими свойствами:
- реактивность;
- автономность;
- целенаправленность;
- коммуникативность.
Свойство реактивности означает, что агент временами отвечает на изменения в окружении. Агент имеет сенсоры, с помощью которых получает информацию от окружения. Сенсоры могут быть самыми различными. Это могут быть микрофоны, воспринимающие акустические сигналы и преобразующие их в электрические, видеокарты захвата изображений, клавиатура компьютера или общая область памяти, в которую окружение помещает данные и из которой программный агент берет данные для вычислений.
Не все изменения окружения становятся известными (доступными) сенсорам агента. Это вполне естественно. Ведь и человек не воспринимает звуки сверхвысокой частоты, радиоволны и т.д. Таким образом, окружение не является полностью наблюдаемым для агента. Аналогично, агент воздействует на окружение, путем разнообразных исполнительных механизмов, включая общую память. Разумеется, степень воздействия, как и степень восприятия, является ограниченной. Агент может перевести окружение из некоторого состояния в некоторое другое, но не из любого в любое.
Свойство автономности означает, что агент является самоуправляющимся, сам контролирует свои действия. Программный агент, находящийся на некотором сервере, обладает возможностью «самозапуска». Он не требует от пользователя каких-либо специальных действий по обеспечению его старта (подобно тому, как мы «кликаем» два раза по иконке некоторого файла).
Свойство целенаправленности означает, что у агента имеется определенная цель и его поведение (воздействие на окружение) подчинено этой цели, а не является простым откликом на сигналы из окружения. Иначе говоря, агент является управляющей системой, а не управляемым объектом.
Свойство коммуникативности означает, что агент общается с другими агентами (включая людей), используя для этого некоторый язык. Это не обязательно единый язык для всех агентов. Достаточно, чтобы у пары общающихся агентов был общий язык. Язык может быть сложным как, например, естественный язык. Но может быть и примитивным: обмен числами или короткими словами. Если многословные фразы сложного языка несут всю информацию, как правило, в себе, то слова простого языка предполагают «умолчание»: обе стороны диалога «знают», о чем идет речь.
В отдельную категорию интеллектуальных агентов выделяют автономные агенты, обладающие свойством обучаемости. Свойство обучаемости означает, что агент может корректировать свое поведение, основываясь на предыдущем опыте. Это не просто накопление в памяти параметров окружения, т.е. Использование исторических данных, но сопоставление истории собственных действий с историей их влияния на окружение, и изменение в связи с этим своей программы действий.
Одна из главнейших особенностей агента – это интеллектуальность. Интеллектуальный агент владеет определенными знаниями о себе и об окружающей среде, и на основе этих знаний он способен определять свое поведение. Интеллектуальные агенты являются основной сферой интересов агентной технологии. Важна также среда существования агента: это может быть, как реальный мир, так и виртуальный, что становится важным в связи с широким распространением сети Интернет. От агентов требуется способность к обучению и даже самообучению.
Способность планировать свои действия делит агентов на регулирующие и планирующие. Если умение планировать не предусмотрено (регулирующий тип), то агент будет постоянно переоценивать ситуацию и возобновлять свое воздействие на окружающую среду. Планирующий агент может запланировать несколько действий на разные промежутки времени. При этом агент может моделировать развитие ситуации, что дает возможность более адекватно реагировать на текущие ситуации. При этом агент должен принимать во внимание не только свои действия и реакцию на них, но и сохранять модели объектов и агентов окружающей среды для прогнозирования их возможных действий и реакций.
Агенты разделяются на две группы, исходя из того, где они находятся и функционируют. Стационарные агенты работают в основном на стороне клиента или на стороне сервера. Эти программы функционируют во взаимодействии с браузером программой просмотра сети и автоматизируют сеансы просмотра. Мобильные агенты относятся к более совершенной и многообещающей категории программных продуктов.
Такие агенты способны самостоятельно перемещаться от сервера к серверу в поисках нужной информации. Это выполняющиеся программы, несущие в себе информацию о собственном состоянии, т. е. вполне автономные. Сегодня концепция программ, извлекающих ресурсы из удаленных точек сети, представляется естественной, однако идея программ, перемещающихся от сервера к серверу, отличается новизной.
Особенность мобильных агентов – в их автономности. Перемещаясь по сети, они несут информацию о своем состоянии (все, что необходимо для их функционирования). Обнаружив необходимые данные, они могут послать сообщение исходному клиенту или серверу. Безусловно, в таком случае важной задачей становится обеспечение информационной безопасности. Разработчики агентов всячески стараются исключить возможность превращения их в информационное оружие.
В модели «клиент-агент-сервер» работы каждое приложение разбивается на две взаимодействующие части. Первая — «клиент», находится на мобильном ПК, обеспечивая пользовательский интерфейс для ввода данных и представления результатов и, возможно, некоторую локальную обработку. Вторая — «агент», располагается на компьютере в локальной сети и, выступая там представителем первой, выполняет по ее запросам доступ к серверам БД, другим источникам данных, различного рода сервису типа электронной почты, печати, передачи факсов и т.п.
В отличие от клиент-серверной модели «клиент-сервер» здесь не организуется сеанс работы пользователя с БД. Вместо этого «клиент» посылает своему «агенту» короткие сообщения-запросы. Получив сообщение, «агент» работает самостоятельно и выполняет запрошенные действия, по окончании которых возвращает «клиенту» сообщение-ответ, содержащее требуемые данные или же просто информацию об успешном завершении операции. В новой модели работа мобильных клиентов по низкоскоростным линиям сводится к минимуму с переносом основного трафика в компьютерную сеть.
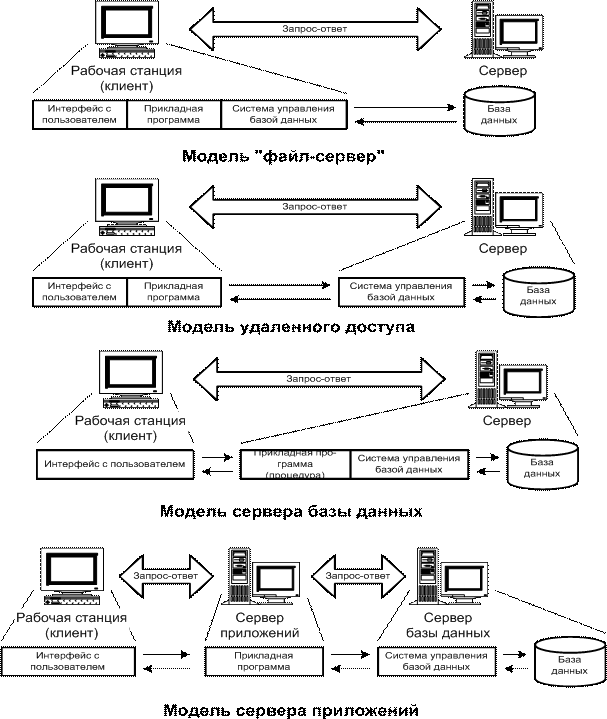
Рис. 2. Модели доступа в современных информационных системах
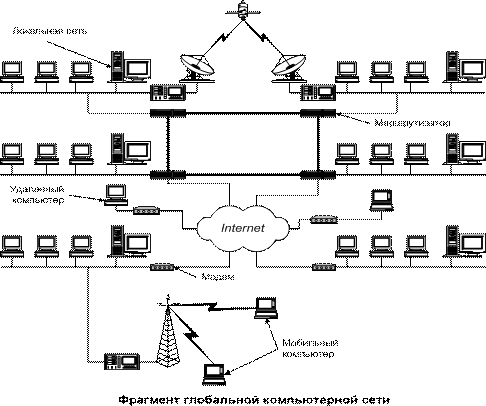
Рис. 3. Примеры доступа компьютеров в глобальную сеть
5. Технологии одноранговых сетей
Технология одноранговых сетей (или P2P-сетей от анг, peer-topeer – равный-к-равному) обеспечивает формирование распределенных систем на базе принципа децентрализации, где разделение вычислительных ресурсов и сервисов производится напрямую посредством прямого взаимодействия между участниками сети друг с другом, без участия центрального сервера. Одноранговые вычислительные сети, в какой-то степени, являются противоположностью клиентсерверным архитектурам.
В отличие от традиционной клиент-серверной архитектуры в P2P-сетях каждый узел, входящий в вычислительную сеть, может являться как клиентом, так и сервером, предоставляя или используя ресурсы сети. На рис. 4 представлены связи в сетях с P2P и с централизованной архитектурой.
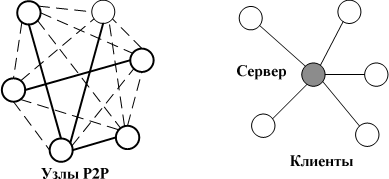
Рис. 4. Сравнение вида связей P2P и централизованной (клиент-серверной) архитектур
Можно выделить следующие проблемы клиент-серверной архитектуры, связанные с наличием централизованного сервера, обеспечивающего обработку запросов от множества клиентов:
- Проблемы масштабируемости. При увеличении количества клиентов растут требования к мощности сервера и пропускной способности канала. Единственным вариантом решения данной задачи является наращивание пропускной способности канала до сервера и использование более высокопроизводительных решений для аппаратной платформы сервера;
- Зависимость. Стабильная работа всех клиентов зависит от загруженности и функционирования одного сервера. При выходе из строя или отключении сервера, клиенты не смогут выполнять функциональные обязанности.
Этим проблемам можно противопоставить следующие преимущества P2P:
- Отсутствие зависимости от централизованных сервисов и ресурсов;
- Система может пережить серьезное изменение в структуре сети;
- Высокая масштабируемость модели одноранговых вычислений.
Можно выделить следующие основные задачи, которые с легкостью решают P2P сети:
- Уменьшение/распределение затрат. Серверы централизованных систем, которые обслуживают большое количество клиентов, обычно несут на себе основной объем затрат ресурсов (денежных, вычислительных и др.) на поддержание вычислительной системы. P2P архитектура может помочь распределить эти затраты между узлами сети. Так как узлы, как правило, автономны, важно, чтобы затраты были распределены справедливо.
- Объединение ресурсов. Каждый узел в P2P-системе обладает определенными ресурсами (вычислительные мощности, объем памяти). Приложения, которым необходимо большое количество ресурсов, например ресурсозатратные задачи моделирования или распределенные файловые системы, используют возможность объединения ресурсов всей сети для решения своей задачи. При этом важны как объем дискового пространства для хранения данных, так и пропускная способность сети.
- Повышенная масштабируемость. Поскольку в сетях Р2Р отсутствует сильный центральный механизм, важной задачей является повышение масштабируемости и надежности системы. Масштабируемость определяет количество систем, которые могут быть достигнуты из одного узла, сколько систем могут функционировать одновременно, сколько пользователей может пользоваться сетью, сколько памяти может быть использовано. Надежность сети определяется такими параметрами как количество сбоев в работе сети, отношение времени простоя к общему времени работы, доступностью ресурсов и т.д. Таким образом, основной проблемой становится разработка новых алгоритмов обнаружения ресурсов, на которых базируются новые P2P платформы.
- Анонимность. Бывает, пользователь не желает, чтобы другие пользователи или поставщики услуг знали о его нахождении в сети. При использовании центрального сервера трудно обеспечить анонимность, так как серверу, как правило, необходимо идентифицировать клиента, по крайней мере через интернет адрес. При использования P2P-сети пользователи могут избежать предоставления любой информацию о себе.
Основные элементы P2P сетей
Пир(Peer)– это фундаментальный составляющий блок любой одноранговой сети:
- Каждый пир имеет уникальный идентификатор;
- Каждый пир принадлежит одной или нескольким группам;
- Каждый пир может взаимодействовать с другими пирами, как в своей так и в других группах.
Можно выделить следующие виды пиров:
- Простой пир: обеспечивает работу конечного пользователя, предоставляя ему сервисы других пиров и обеспечивая предоставление ресурсов пользовательского компьютера другим участникам сети;
- Роутер: обеспечивает механизм взаимодействия между пирами, отделенными от сети брандмауэрами или NAT-системами.
Группа пиров– это набор пиров, сформированный для решения общей задачи или достижения общей цели. Группы пиров могут предоставлять членам своей группы такие наборы сервисов, которые недоступны пирам, входящим в другие группы.
Сервисы – это функциональные возможности, которые может привлекать отдельный пир для полноценной работы с удаленными пирами. В качестве примера сервисов, которые может предоставлять отдельный пир можно указать сервисы передачи файлов, предоставления информации о статусе, проведения вычислений и др. Сервисы пира– это такие сервисы, которые может предоставить конкретный узел P2P. Каждый узел в сети P2P предоставляет определенные функциональные возможности, которыми могут воспользоваться другие узлы.
Эти возможности зависят от конкретного узла и доступны только тогда, когда узел подключен к сети. Как только узел отключается, его сервисы становятся недоступны. Сервисы группы– это функциональные возможности, предоставляемые группой входящим в нее узлам. Возможности могут предоставляться несколькими узлами в группе, для обеспечения избыточного доступа к этим возможностям. Как только к группе подключается узел, обеспечивающий необходимый сервис, он становиться доступной для всей группы.
P2P — это не только сети, но еще и сетевой протокол, обеспечивающий возможность создания и функционирования сети равноправных узлов, их взаимодействия. Множество узлов, объединенных в единую систему и взаимодействующих в соответствии с протоколом P2P, образуют пиринговую сеть. P2P относятся к прикладному уровню сетевых протоколов и являются наложенной сетью, использующей существующие транспортные протоколы стека TCP/IP. Протоколы сети P2P обеспечивают:
- поиск узлов в сети;
- получение списка служб отдельного узла;
- получение информации о статусе узла;
- использование службы на отдельном узле;
- создание, объединение и выход из групп;
- создание соединений с узлами;
- маршрутизацию сообщений другим узлам.
Можно выделить следующие основные преимущества одноранговых сетей:
- высокая масштабируемость, связанная с равномерным распределением вычислительной нагрузки на всех участников сети;
- стабильность работы сети, обусловленная отсутствием «узкого места» – выделенного сервера, обрабатывающего все сетевые запросы;
- возможность объединения ресурсов отдельных участников сети, и их предоставление другим участникам;
- распределение совокупных затрат на предоставление ресурсов между участниками сети.
С другой стороны, отдельно стоит упомянуть о следующих недостатках и особенностях функционированияP2P-сетей:
- в одноранговых сетях не может быть обеспечено гарантированное качество обслуживания: любой узел, предоставляющий те или иные сервисы, может быть отключен от сети в любой момент;
- индивидуальные технические характеристики узла могут не позволить полностью использовать ресурсы P2P сети (каждый из узлов обладает индивидуальными техническими характеристиками что, возможно, будет ограничивать его роль в P2P-сети и не позволят полностью использовать ее ресурсы: низкий рейтинг в torrent-сетях, LowID в eDonkey могут значительно ограничить ресурсы сети, доступные пользователю);
- при работе того или иного узла через брандмауэр может быть значительно снижена пропускная способность передачи данных в связи с необходимостью использования специальных механизмов обхода
- участниками одноранговых сетей в основном являются индивидуальные пользователи, а не организации, в связи с чем возникают вопросы безопасности предоставления ресурсов: владельцы узлов P2P-сети, скорее всего, не знакомы друг с другом лично, предоставление ресурсов происходит без предварительной договоренности;
- при увеличении числа участников P2P сети может возникнуть ситуация значительного возрастания нагрузки на сеть (как с централизованной, так и с децентрализованной структурой);
- в случае применения сети типа P2P приходится направлять значительные усилия на поддержку стабильного уровня ее производительности, резервное копирование данных, антивирусную защиту, защиту от информационного шума и других злонамеренных действий пользователей.
6. Архитектура грид
Термин «грид» был введен в обращение Яном Фостером в начале 1998 года публикацией книги «Грид. Новая инфраструктура вычислений»:
Грид – это система, которая координирует распределенные ресурсы посредством стандартных, открытых, универсальных протоколов и интерфейсов для обеспечения нетривиального качества обслуживания.
Основной идеей, заложенной в концепции грид-вычислений, является централизованное удаленное предоставление ресурсов, необходимых для решения различного рода вычислительных задач. В идеологии грид: мы можем запустить любую задачу с любого компьютера или мобильного устройств на вычисление, ресурсы же для этого вычисления должны быть автоматически предоставлены на удаленных высокопроизводительных серверах, независимо от типа нашей задачи.
С более практической точки зрения, основная задача, лежащая в основе концепции грид, это согласованное распределение ресурсов и решение задач в условиях динамических, многопрофильных виртуальных организаций. Распределение ресурсов, в котором заинтересованы разработчики грид, это не обмен файлами, а прямой доступ к компьютерам, программному обеспечению, данным и другим ресурсам, которые требуются для совместного решения задач и стратегий управления ресурсами, возникающих в промышленности, науке и технике.
Технологии грид включают в себя:
- решения по безопасности, поддерживающие управление сертификацией и политиками безопасности, когда вычисления производятся несколькими организациями;
- протоколы управления ресурсами и сервисами, поддерживающие безопасный удаленный доступ к вычислительным ресурсам и ресурсам данных, а также перераспределение различных ресурсов;
- протоколы запроса информации и сервисы, обеспечивающие настройку и мониторинг состояния ресурсов, организаций и сервисов;
- сервисы обработки данных, обеспечивающие поиск и передачу наборов данных между системами хранения данных и приложениями.
Выделяют следующие уровни архитектуры грид:
- Базовый уровень (Fabric) – содержит различные ресурсы, такие как компьютеры, устройства хранения, сети, сенсоры и др.
- Связывающий уровень(Connectivity)– определяет коммуникационные протоколы и протоколы аутентификации.
- Ресурсный уровень(Resource)– реализует протоколы взаимодействия с ресурсами РВС и их управления.
- Коллективный уровень(Collective)– управление каталогами ресурсов, диагностика, мониторинг;
- Прикладной уровень (Applications)– инструментарий для работы с грид и пользовательские приложения.
На базовом уровне определяются службы, обеспечивающие непосредственный доступ к ресурсам, использование которых распределено посредством протоколов грид.
- Вычислительные ресурсы предоставляют пользователю грид-системы (точнее говоря, задаче пользователя) процессорные мощности. Вычислительными ресурсами могут быть как кластеры, так и отдельные рабочие станции. При всем разнообразии архитектур любая вычислительная система может рассматриваться как потенциальный вычислительный ресурс грид-системы.
- Ресурсы памяти представляют собой пространство для хранения данных. Для доступа к ресурсам памяти также используется программное обеспечение промежуточного уровня, реализующее унифицированный интерфейс
- Управления и передачи данных.
- Информационные ресурсы и каталоги являются особым видом ресурсов памяти. Они служат для хранения и предоставления метаданных и информации о других ресурсах грид-системы.
- Сетевой ресурс является связующим звеном между распределенными ресурсами грид-системы. Основной характеристикой сетевого ресурса является скорость передачи данных.
Связывающий уровень определяет коммуникационные протоколы и протоколы аутентификации, обеспечивая передачу данных между ресурсами базового уровня. Связывающий уровень грид основан на стеке протоколов TCP/IP:
- Интернет (IP, ICMP);
- Транспортные протоколы (TCP, UDP);
- Прикладные протоколы (DNS, OSRF…).
Ресурсный уровень реализует протоколы, обеспечивающие выполнение следующих функций:
- Согласование политик безопасности использования ресурса;
- Процедура инициации ресурса;
- Мониторинг состояния ресурса;
- Контроль над ресурсом;
- Учет использования ресурса.
Отдельно выделяются 2 типа протоколов ресурсного уровня:
- Информационные протоколы – используются для получения информации о структуре и состоянии ресурса.
- Протоколы управления – используются для согласования доступа к разделяемым ресурсам, определяя требований и допустимых действий по отношению к ресурсу (например, поддержка резервирования, возможность создания процессов, доступ к данным).
Коллективный уровень отвечает за глобальную интеграцию различных наборов ресурсов и может включать в себя службы каталогов; службы совместного выделения, планирования и распределения ресурсов; службы мониторинга и диагностики ресурсов; службы репликации данных. На прикладном уровне располагаются пользовательские приложения, исполняемые в среде ВО. Они могут использовать ресурсы, находящиеся на любых нижних слоях архитектуры грид.
Стандарты Грид
Ключевым моментом в разработке грид приложений является стандартизация, позволяющая организовать поиск, использование, размещение и мониторинг различных компонентов, составляющих единую виртуальную систему, даже если они предоставляются различными поставщиками услуг или управляются различными организациями.
В 2001 году в качестве базы для создания стандарта архитектуры грид приложений была выбрана технология веб-сервисов. Данный выбор был обусловлен двумя основными достоинствами данной технологии.
Во-первых, язык описания интерфейсов веб-сервисов WSDL (Web Service Definition Language) поддерживает стандартные механизмы для определения интерфейсов отдельно от их реализации, что в совокупности со специальными механизмами связывания (транспортным протоколом и форматом кодирования данных) обеспечивает возможность динамического поиска и компоновки сервисов в гетерогенных средах.
Во-вторых, широко распространенная адаптация механизмов веб-сервисов означает, что инфраструктура, построенная на базе веб-сервисов, может использовать различные утилиты и другие существующие сервисы, такие как различные процессоры WSDL, системы планирования потоков задач и среды для размещения вебсервисов.
Разработанный стандарт архитектуры грид получил название OGSA (Open Grid Services Architecture – Открытая архитектура гридсервисов). Он основывается на понятии грид-сервиса. Грид-сервисом называется сервис, поддерживающий предоставление полной информации о текущем состоянии (потенциально временного) экземпляра сервиса, а также поддерживающий возможность надежного и безопасного исполнения, управления временем жизни, рассылки уведомлений об изменении состояния экземпляра сервиса, управления политикой доступа к ресурсам, управления сертификатами доступа и виртуализации. Грид-сервис поддерживает следующие стандартные интерфейсы.
- Поиск. Грид — приложениям необходимы механизмы для поиска доступных сервисов и определения их характеристик.
- Динамическое создание сервисов. Возможность динамического создания и управления сервисами – это один из базовых принципов OGSA, требующий наличия сервисов создания новых сервисов.
- Управление временем жизни. Распределенная система должна обеспечивать возможность уничтожения экземпляра грид-сервиса.
- Уведомление. Для обеспечения работы грид приложения наборы грид сервисов должны иметь возможность асинхронно уведомлять друг друга о изменениях в их состоянии.
7. Облачные вычисления
Облачные вычисления привлекают много внимания в последнее время. В средствах массовой информации, в интернете, даже на телевидении можно встретить восторженные материалы, описывающие все прекрасные возможности, которые может предоставить данная технология.
Термин «Облачные вычисления» появился на свет совсем недавно. Согласно результатам анализа поисковой системы Google, термин «Облачные вычисления» («Cloud Computing») начал набирать вес в конце 2007 – начале 2008 года. На сегодняшний день уже можно говорить о том, что облачные вычисления прочно вошли в повседневную жизнь каждого пользователя Интернета (хотя многие об этом и не подозревают). По некоторым экспертным оценкам, технология облачных вычислений может в три-пять раз сократить стоимость бизнес-приложений и более чем в пять раз стоимость приложений для конечных потребителей.
Определение облачных вычислений
С одной стороны, у термина «Облачные вычисления» нет устоявшегося стандартного определения. С другой стороны множество различных корпораций, ученых и аналитиков дают собственные определения этому термину.
Например, в лаборатории Беркли дают следующее определение облачных вычислений:
«Облачные вычисления– это не только приложения, поставляемые в качестве услуг через Интернет, но и аппаратные средства и программные системы в центрах обработки данных, которые обеспечивают предоставление этих услуг. Услуги сами по себе уже давно называют «предоставление программного обеспечения как услуги» (Software-as-a-Service или SaaS). Облаком называется аппаратное и программное обеспечение центра обработки данных.
Общественное облако предоставляет ресурсы облака широкому кругу пользователей по принципу «оплата по мере использования» (pay-as-you-go – принцип предоставления услуг, при котором пользователь оплачивает только те ресурсы, которые были по факту затрачены на решение поставленной задачи).
Частное облако – это внутренние центры обработки данных, в коммерческой или иной организации, которые не доступны широкому кругу пользователей. Таким образом, облачные вычисления являются суммой SaaS и «коммунальных вычислений» (Utility Computing– модель вычислительных систем, в которой предоставление данных и процессорных мощностей организовано по принципам коммунальных услуг). Люди могут быть пользователями или провайдерами SaaS, либо пользователями или поставщиками коммунальных вычислений».
Ян Фостер определяет облачные вычисления как «парадигму крупному-штабных распределенных вычислений, основанную на эффекте масштаба, в рамках которой пул абстрактных, виртуализиванных, динамически масштабируемых вычислительных ресурсов, ресурсов хранения, платформ и сервисов предоставляется по запросу внешним пользователям через Интернет».
Еще одно распространенное определение облачных вычислений состоит в следующем.
«Облако – это большой пул легко используемых и легкодоступных виртуализиванных ресурсов (таких как аппаратные комплексы, сервисы и др.). Эти ресурсы могут быть динамически перераспределены (масштабированы) для подстройки под динамически изменяющуюся нагрузку, обеспечивая оптимальное использование ресурсов. Этот пул ресурсов обычно предоставляется по принципу «оплата по мере использования». При этом владелец облака гарантирует качество обслуживания на основе определенных соглашений с пользователем».
Все определения иллюстрируют одну простую мысль: феномен облачных вычислений объединяет несколько различных концепций информационных технологий и представляет собой новую парадигму предоставления информационных ресурсов (аппаратных и программных комплексов). Со стороны владельца вычислительных ресурсов облачные вычисления ориентированы на предоставление информационных ресурсов внешним пользователям.
Со стороны пользователя, облачные вычисления – это получение информационных ресурсов в виде услуги у внешнего поставщика, оплата за которую производится в зависимости от объема потребленных ресурсов согласно установленному тарифу. Ключевыми характеристиками облачных вычислений являются масштабируемость и виртуализация.
Масштабируемость представляет собой возможность динамической настройки информационных ресурсов к изменяющейся нагрузке, например к увеличению или уменьшению количества пользователей, изменению необходимой емкости хранилищ данных или вычислительной мощности. Виртуализация, которая также рассматривается как важнейшая технология всех облачных систем, в основном используется для обеспечения абстракции и инкапсуляции.
Абстракция позволяет унифицировать «сырые» вычислительные, коммуникационные ресурсы и хранилища информации в виде пула ресурсов и выстроить унифицированный слой ресурсов, который содержит те же ресурсы, но в абстрагированном виде. Они представляются пользователям и верхним слоям облачных систем как виртуализиванных серверы, кластеры серверов, файловые системы и СУБД. Инкапсуляция приложений повышает безопасность, управляемость и изолированность. Еще одной важной особенностью облачных платформ является интеграция аппаратных ресурсов и системного ПО с приложениями, которые предоставляются конечному пользователю в виде сервисов.
В соответствии со всем вышесказанным, можно выделить следующие основные черты облачных вычислений:
- Облачные вычисления представляют собой новую парадигму предоставления вычислительных ресурсов;
- Базовые инфраструктурные ресурсы (аппаратные ресурсы, системы хранения данных, системное ПО) и приложения предоставляются в виде сервисов. Данные сервисы могут предоставляться независимым поставщиком для внешних пользователей по принципу «оплата по мере использования»;
- Основными особенностями облачных вычислений являются виртуализация и динамическая масштабируемость;
- Облачные сервисы могут предоставляться конечному пользователю через веб-браузер или посредством определенного программного интерфейса.
Многослойная архитектура облачных приложений
Все возможные методы классификации облаков можно свести к трехслойной архитектуре облачных систем, состоящей из следующих уровней:
- Инфраструктура как сервис (Infrastructure as a Service: IaaS);
- Платформа как сервис (Platform as a Service: PaaS);
- Программное обеспечение как сервис (Software as a Service: SaaS).
Рассмотрим более подробно, что собой представляет каждый из указанных уровней, и каким образом они взаимодействуют друг с другом.
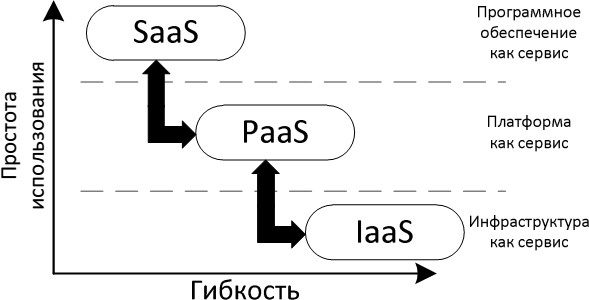
Рис. 5. Три слоя облачных вычислений
Инфраструктура как сервис (IaaS)
IaaS предлагает информационные ресурсы, такие как вычислительные циклы или ресурсы хранения информации, в виде сервиса. Вместо предоставления доступа к «сырым» вычислительным устройствам и системам хранения, поставщики IaaS обычно предоставляют виртуализованную инфраструктуру в виде сервиса. Обычно «сырые» ресурсы (процессорные циклы, сетевое оборудование, системы хранения) располагают на базовом уровне, над которым посредством виртуализации надстраивают слои сервисов, которые и предоставляются конечным пользователям в виде IaaS.
Надо сказать, что еще задолго до появления облачных вычислений инфраструктура была доступна как сервис. Такой подход назывался «коммунальные вычисления», и это словосочетание часто применяется некоторыми авторами при описании инфраструктурного уровня облачных систем.
В сравнении с ранними попытками организации коммунальных вычислений, подход IaaS предоставляет разработчикам понятный интерфейс, к которому легко получить доступ и использовать в собственных приложениях. Данный интерфейс должен легко интегрироваться с инфраструктурой потенциальных пользователей и разработчиков решений SaaS. Давно замечено, что ресурсы поставщиков коммунальных вычислений могут быть эффективно использованы только в том случае, если они используются большим числом потребителей, а этого можно добиться путем организации хорошего программного интерфейса к своим ресурсам.
Платформа как сервис(PaaS)
Платформа – это слой абстракции между программными приложениями (SaaS) и виртуализованной инфраструктурой (IaaS). Основной целевой аудиторией PaaS являются разработчики приложений. Разработчики могут писать собственные приложения на основе спецификаций определенной платформы, не заботясь о том, каким образом организовать взаимодействие с нижележащей инфраструктурой (IaaS).
Разработчики загружают свой программный код на платформу, которая обеспечивает автоматическое масштабирование приложения в зависимости от нагрузки. Слой PaaS основывается на стандартизованном интерфейсе, предоставляемом слоем IaaS, который виртуализует базовые вычислительные ресурсы и предоставляет стандартный интерфейс для разработки приложений, функционирующих на слое SaaS.
Программное обеспечение как сервис(SaaS)
SaaS – это программное обеспечение, которое предоставляется по принципу «оплата по мере использования» и управляется удаленно одним или несколькими поставщиками. SaaS – это наиболее заметный слой облачных вычислений, так как именно он представляет реальную ценность для конечного пользователя и обеспечивает решение его задач.
С точки зрения пользователя, основным достоинством SaaS является цеж-новое преимущество перед «классическим» ПО. Оплата SaaS осуществляется по модели «оплата по мере использования», что означает отсутствие необходимости инвестиций в собственную аппаратную и программную инфраструктуру.
Типичный пользователь SaaS не может контролировать базовую инфраструктуру, будь это программная платформа, на которой SaaS основано (PaaS) или же непосредственно аппаратная инфраструктура(IaaS). Однако поставщик SaaS обязан проработать взаимодействие данных слоев, потому что они необходимы для работы системы.
Например, SaaS-приложение может быть разработано на базе существующей платформы и исполняться на инфраструктуре, предоставленной сторонней компанией. Работа с платформами и/или инфраструктурой как с сервисом является очень привлекательной с точки зрения поставщиков SaaS, так как это может уменьшить в разы отчисления на используемые лицензии или затраты на инфраструктуру. Это также позволяет им сосредоточиться на тех областях, в которых они по-настоящему компетентны. Как можно заметить, это очень похоже на те преимущества, которые мотивируют конечных пользователей ПО переходить к использованию решений SaaS.
Компоненты облачных приложений
На сегодняшний день не существует единой компонентной архитектуры облачных приложений. Это вызвано высокой закрытостью различных аспектов реализации наиболее распространенных облачных систем. Но, не смотря на это, можно выделить основные наиболее важные компоненты, присущие практически всем существующим облачным платформам.
Рис. 6. Компонентная модель облачного решения
Облако можно разбить на основные компоненты, отражающие следующие ключевые особенности облачных решений.
- Платформа: среда и набор утилит, обеспечивающих разработку, интеграцию и предоставление облачных сервисов. Платформа является центральным компонентом модели облака. Платформа с одной стороны, предоставляет набор базовых сервисов, доступных разработчику облачного приложения, а с другой накладывает определенные ограничения на методы разработки и предоставления приложения.
- Представление: интерфейс, через который пользователь производит взаимодействие с облаком. Этот компонент обеспечивает получение входных данных и предоставление информации конечному пользователю. Наиболее типичным методом реализации представления является веб-приложение, обеспечивающее взаимодействие с пользователем посредством веб-браузера. В последнее время все чаще используются все возможности предоставления пользователю удобного интерфейса работы независимо от устройства, с которого он выходит в Интернет. Это влечет за собой разработку отдельных пользовательских интерфейсов для мобильных устройств (смартфонов, планшетов) которые могут представлять собой как отдельные интернет-страницы, так и полноценные мобильные приложения, взаимодействующие с облаком посредством API.
- Информация: источники данных, обеспечивающие распределенное хранение структурированных или неструктурированных, статических или динамически-изменяющихся данных. Пользовательская информация в облачных системах может достигать огромных объемов. Классические SQL базы данных уже не дают удовлетворительных результатов по скорости обработки. Более того, облачным платформам часто приходится обрабатывать связанные структуры данных (графы, деревья) что становится очень тяжело при использовании SQL-подхода и реляционных баз данных. В связи с этим, в последние несколько лет стали активно развиваться альтернативные «NoSQL» системы управления базами данных (колоночные СУБД, такие как Hadoop; документно-ориентированные СУБД, такие как CouchDB и MongoDB) и альтернативные подходы к обработке сверхбольших объемов информации. Наиболее известной реализацией такого подхода является фреймворк MapReduce, представленный компанией Google. Он используется для параллельных вычислений над очень большими (несколько петабайт) наборами данных в компьютерных кластерах.
- Идентификация: информация об основных потребителях облачных ресурсов, используется для оптимизации и подстройки облака под их задачи. Большинству приложений требуется уметь отличать пользователей друг от друга для предоставления релевантной информации. Такая информация имеет первостепенную значимость для облачной платформы, так как на нее завязаны большие объемы пользовательских данных, и при этом необходимо обеспечить ее максимальную доступность в рамках системы, т.к. процедура авторизации должна проходить максимально быстро. Также, необходимо обеспечить прозрачную авторизацию пользователя во всех сервисах одной облачной платформы, чтобы не требовалось каждый раз вводить имя пользователя и пароль заново. В связи с распределенной природой облачных сервисов необходимо обеспечить высочайший уровень безопасности при работе с пользовательской информацией.
- Интеграция: инфраструктура, упрощающая обмен информацией и исполнение задач в распределенной вычислительной среде. Высокая степень декомпозиции сервисов позволяет достичь максимальной эффективности и гибкости выполнения облачных приложений, так как появляется возможность загрузки сразу нескольких вычислительных машин при исполнении одной пользовательской задачи. В связи с этим появляется необходимость организации обмена информацией и исполнения задач в распределенных вычислительных средах. В рамках этого компонента необходимо обеспечить максимальную производительность и безопасность процесса обмена данными между сервисами. Далее, необходимо обеспечить совместимость форматов данных и разработать механизмы синхронного и асинхронного взаимодействия с унаследованным ПО. На более высоком уровне необходимо обеспечить слабосвязанность программных компонентов и убедиться в отсутствии узких мест в программной архитектуре системы.
- Масштабируемость: гибкость методов предоставления ресурсов, обеспечивающая поддержку выделения дополнительных информационных ресурсов при возрастании нагрузки на приложение. При этом необходимо учитывать не только возможность кратковременного увеличения нагрузки на приложение но и планировать долгосрочное увеличение производительности системы в результате постоянного прироста аудитории. В обоих случаях, необходимо обеспечить декомпозицию облачного приложения на отдельные модульные компоненты, которые могут быть распределены на несколько вычислительных устройств.
- Монетизация: учет и биллинг ресурсов, затраченных на исполнение пользовательских задач. Это ключевой компонент множества коммерческих приложений. Для организации качественного биллинга облачных платформ необходимо организовать сбор и предоставление полноценной информации о всевозможных ресурсах, затрачиваемых на решение пользовательских задач. Также, необходимо обеспечить пользователю возможность удобной и быстрой оплаты затраченных ресурсов.
- Внедрение: процесс разработки нового облачного приложения, который включает в себя разработку, тестирования и внедрение в эксплуатацию. На этапе разработки облачного приложения требуется совсем небольшой объем вычислительных ресурсов, который значительно увеличивается при переходе к этапу нагрузочного тестирования и внедрения в эксплуатацию. При этом очевидно, что применение готовой облачной инфраструктуры позволяет значительно сократить издержки на разработку и внедрение высоко масштабируемого приложения, так как оплата использованных информационных ресурсов производится на основе модели коммунальных вычислений и не требует значительных инвестиций в собственную инфраструктуру. Это позволяет минимизировать начальные затраты и сконцентрировать финансирование на всестороннем тестировании приложения. Но, не смотря на все перечисленные достоинства, необходимо оценить все возможные недостатки модели облачных вычислений, как то сложности организации репликации данных между сервисами, сложность отката на предыдущие версии при появлении неожиданных ошибок в процессе внедрения, необходимость аккуратного и всестороннего тестирования разработанных сервисов на совместимость данных и слаженность работы приложения.
- Функционирование: мониторинг и поддержка приложений, находящихся в стадии эксплуатации. Приложение, которое запущено в эксплуатацию, необходимо администрировать, что может оказаться чрезвычайно сложной задачей, если учесть большое число отдельных сервисов, составляющих облачное приложение. В связи с этим необходимо обеспечить интеграцию процессов администрирования и управления сервисами в виде единого «центра управления сервисами». Параллельно, в него можно включить мониторинг нагрузки приложения, панель управления пользовательскими задачами и т.п.
Все вышеперечисленные компоненты облачного приложения должны быть запланированы с самого начала разработки для обеспечения высокого уровня масштабируемости и автоматизации.
Достоинства и недостатки облачных вычислений
Как ранее было описано, облачные вычисления ориентированы на предоставление информационных ресурсов на трех уровнях: уровне инфраструктур (IaaS), уровне платформ (PaaS) и уровне программного обеспечения (SaaS).
Предоставляя интерфейсы ко всем трем различным уровням, облака взаимодействуют с тремя различными типами потребителей.
- Конечные пользователи, которые используют SaaS-решения через веб-браузер, или же какие-либо базовые ресурсы инфраструктурного слоя которые предоставляются посредством слоя.
- Корпоративные потребители, которые могут использовать все три слоя: IaaS – для того, чтобы расширить собственную программно-аппаратную инфраструктуру или получить дополнительные вычислительные ресурсы по требованию; PaaS – для того, чтобы иметь возможность запуска собственных приложений в облаке; SaaS – для получения возможностей тех приложений, которые уже доступны в облаке.
- Разработчики и независимые поставщики программного обеспечения, разрабатывающие приложения, которые предоставляются в виде облачных SaaS-решений. Обычно, эта категория пользователей напрямую взаимодействует со слоем PaaS, и уже через него, опосредованно, со слоем IaaS.
С точки зрения пользователя, основное достоинство облачных вычислений – это модель оплаты ресурсов по мере их использования. Отсутствует необходимость предварительных инвестиций в инфраструктуру: нет необходимости инвестиций в лицензионное ПО, отсутствует необходимость инвестиции в аппаратную инфраструктуру и связанные с этим затраты на обслуживание и персонал. Таким образом, капитальные затраты превращаются в текущие расходы.
Покупатели облачных сервисов используют только тот объем информационных ресурсов, который им на самом деле необходим, и оплачивают только тот объем информационных ресурсов, которыми они реально воспользовались. В то же время, они пользуются такими достоинствами облачных вычислений как масштабируемость и гибкость. Облачные вычисления позволяет легко и быстро предоставить необходимые вычислительные ресурсы по требованию.
Тем не менее, существуют некоторые недостатки модели облачных вычислений, которые вытекают из одной очевидной особенности – облака обслуживают сразу множество различных клиентов. Пользователь облачной платформы не знает, задачи каких пользователей будут исполняться на том или ином сервере, входящем в облачную инфраструктуру. Типичное облако является внешним по отношению к внутренней инфраструктуре любой компании, то есть находится вне зоны ответственности администраторов и служб безопасности компании-потребителя.
В то время как для отдельного потребителя это может быть несущественным, крупные компании уделяют этому вопросу очень большое значение Пользователю приходится полагаться на обещания поставщика облачных решений в вопросах надежности, производительности и качества обслуживания инфраструктуры облака. Использование облаков также сопряжено с высокими рисками безопасности и защиты конфиденциальной информации. Это связано с двумя факторами:
- необходимость загрузки и получения данных из облака;
- хранение данных производится на базе удаленных хранилищ, в связи с чем владельцу информации приходится полагаться на гарантии поставщика облачных решений, что несанкционированного доступа к данным не произойдет.
Более того, использование облаков требует определенных инвестиций в интеграцию собственной инфраструктуры и приложений в облако. В настоящее время нет стандартов для интерфейсов IaaS, PaaS и SaaS. В связи с этим выбор поставщика облачных решений становится довольно рискованным занятием.
В связи с этим, необходимо всегда учитывать риски, связанные с использованием облаков. В каждом отдельном случае необходимо внимательно взвесить все потенциальные выгоды и угрозы при переходе на облачную платформу. Также, необходимо решить какие данные и какая обработка может производиться на базе «облачного аутсорсинга», а какие данные лучше никогда не выводить за рамки локальной сети организации.
8. Особенности управления в распределенных информационных системах
Объединение компьютеров в единые вычислительные системы на основе технологии компьютерных сетей поставило перед разработчиками информационных систем новые задачи и предопределило необходимость реализации принципиально новых подходов к организации информационного процесса в компьютерных сетях. Качественный скачок в этой области возможен благодаря созданию гибких, высокопроизводительных и экономичных распределенных информационных систем.
Распространение концепции баз данных (БД) на новый уровень позволяет определить распределенную информационную систему как комплекс логически интегрированных и территориально рассредоточенных БД, технических, программных, языковых и организационных средств, предназначенных для накопления, ведения и использования информации. В свою очередь, распределенная база данных (РБД) определяется как интегрированная БД, физически размещаемая на нескольких территориально распределенных компьютерах сети.
Для таких систем характерными являются следующие функции:
- Накопление, обновление и хранение данных в географически удаленных узлах сети;
- Логическая интеграция территориально распределенных данных, процессов обработки, обновления и поиска информации;
- Обеспечение автоматического взаимодействия между локальными базами данных в процессе исполнения запросов и решения задач пользователей.
Управление выполнением основных функций ИС осуществляет комплекс программных средств, который включает систему управления распределенными базами данных (СУРБД) в качестве основного компонента, а также сетевую операционную систему, систему разграничения доступа и др.
Под СУРБД понимают систему, реализующую принцип логической интеграции данных, физически распределенных между различными взаимосвязанными компьютерами. К основным функциям СУРБД можно отнести анализ и распределение запросов, а также управление их прохождением.
Следует отметить, что реализация концепции распределенных БД обеспечивает независимость программ по отношению к распределению данных в вычислительной сети. Это означает, что пользователь может иметь доступ к любым данным сети в пределах своих полномочий как к собственной локальной базе данных. В этом контексте существенный интерес представляет рассмотрение различных способов распределения данных по узлам сети для обеспечения эффективного доступа к ним.
Стратегии распределения данных по узлам компьютерной сети могут классифицироваться по различным признакам. К основным из них можно отнести наличие дублирования информации и количество узлов, содержащих копии данных. В соответствии с указанными классификационными признаками представляется возможным выделить четыре альтернативных стратегии распределения:
- Централизация (единственная копия БД, расположенная в одном узле);
- Расчленение (единственная копия БД, непересекающиеся фрагменты которой распределены по нескольким узлам);
- Дублирование (несколько копий БД, в каждом узле располагается полная копия всей базы);
- Смешанная (несколько копий БД, в каждом узле располагается произвольный фрагмент базы).
Ранжирование стратегий по предпочтительности их использования в общем случае не представляется возможным. Определение ситуаций, в которых та или иная стратегия является наиболее подходящей, целесообразно после выявления преимуществ и недостатков каждой из них.
Стратегия централизации. Названная стратегия характеризует предельный случай распределения данных. Строго говоря, БД, построенная по этой стратегии, не является распределенной. Тем не менее системы, реализующие стратегию централизации, могут быть вынесены в класс систем распределенной обработки, в которых рассредоточены вычислительные ресурсы и программное обеспечение.
К несомненным достоинствам централизованной БД следует отнести ее простоту, так как все операции обращения к данным выполняются под управлением одного узла.
В то же время недостатки рассматриваемой стратегии связаны именно с локальным расположением данных. Естественно, что объем базы данных ограничен емкостью запоминающих устройств центрального узла. К тому же запросы на операции над данными должны направляться только в этот узел со всеми вытекающими транспортными издержками. Центральный узел становится узким местом всей сети по следующим причинам: Во-первых, скорость обработки данных ограничивается его быстродействием; во-вторых, БД становится недоступной для других узлов при появлении неисправностей в сети передачи данных и полностью отказывает при выходе из строя центрального узла.
Любая из трех других стратегий помогает преодолеть указанные недостатки ценой определенных затрат.
Стратегия расчленения. При использовании этой стратегии база разделяется на непересекающиеся подмножества данных, называемые логическими фрагментами. Каждый такой фрагмент размещается в отдельном узле. Число узлов, хранящих данные, может быть произвольным, в предельном случае равным общему числу узлов сети.
Преимущества расчленения данных перед централизованным размещением следующие. Размер базы ограничивается объемом запоминающих устройств всей сети (ее части). Снижается чувствительность к узким местам в сети передачи данных, поскольку нагрузка на нее распределяется более равномерно. Повышается доступность данных. Даже если сеть передачи данных полностью или частично выходит из строя, то доступными для пользователей могут оставаться фрагменты БД в отдельных узлах или узлах, остающихся связанными. Это обеспечивает реализацию функций информационной системы, хотя и в сокращенном объеме.
Важную роль при определении потенциальной доступности данных в критических ситуациях играет степень локализации ссылок. Под локализацией ссылок понимают характер расположения данных относительно запросов пользователей. Наивысшая степень локализации ссылок существует в случае, если данные, расположенные в одном узле, запрашиваются исключительно пользователями этого узла.
Напротив, степень локализации ссылок мала, если подобное расчленение базы невозможно. Таким образом, если запрос пользователя может быть исполнен с помощью локально хранимых данных (степень локализации ссылок высока), то неисправности в других узлах или в сети передачи данных не окажут влияния на результат. Если же степень локализации ссылок незначительна или запросы являются сложными, то в большинстве случаев пользователям могут потребоваться данные от других узлов.
Недоступность хотя бы одного узла приведет к неисполнению запроса пользователя. В подобной ситуации доступность данных в расчлененной базе может быть хуже, чем в централизованной, так как вероятность того, что по меньшей мере один узел сети будет недоступен, выше вероятности недоступности единственного конкретного узла.
Следовательно, стратегия расчленения обеспечит меньшую по времени доступность БД, чем стратегия централизации.
Степень локализации ссылок влияет и на временные характеристики расчлененной БД. Так, если большая часть запросов обслуживается локально, уменьшаются затраты времени на передачу данных. С другой стороны, если исполнение запроса требует доступа ко многим узлам, среднее время задержки может превышать аналогичный показатель централизованной базы. Тем не менее, уменьшение времени реакции может быть достигнуто, если в полной мере используется параллелизм в вычислительной сети.
Стратегия дублирования. Реализация этой стратегии предполагает размещение полной копии БД в нескольких узлах сети (в предельном случае в каждом узле). Отсутствует задача определения, какую часть базы должен содержать тот или иной узел.
Однако первоочередное значение приобретают вопросы, связанные с согласованием многочисленных копий данных.
Рассматриваемая стратегия обеспечивает наивысший уровень доступности и надежности данных, но при явных затратах внешней памяти сети. Объем базы данных ограничивается наименьшей емкостью запоминающих устройств в узлах, хранящих данные. Обработка данных большей частью проводится локально, но согласование множества копий требует синхронизации. Способы согласования в конкретных приложениях могут быть различными, а уровень транспортных издержек существенно зависит от степени постоянства данных.
Необходимость согласования копий и сложность управления этим процессом являются причиной того, что стратегия дублирования позволяет реализовать параллельную обработку не столь просто, как стратегия расчленения. В свою очередь, каждый узел может работать асинхронно, а время реакции на запросы может быть небольшим, особенно при исполнении запросов, не требующих согласования копий, например при выполнении поисковых процедур.
Налицо простота замены разрушенной копии или восстановления процесса обработки в случае выхода из строя узла. Согласованная копия может быть получена из любого рабочего узла, после чего обращение к восстановленному узлу может проводиться в полном объеме. Следует заметить, что если часть сети недоступна по какой-либо причине, необходимым становится наложение ограничений на выполнение операций обновления данных для поддержания глобальной согласованности копий базы данных. Действительно, если разрешить две операции обновления в двух узлах при отсутствии согласования, то при возобновлении нормального функционирования сети возможно нарушение согласованности базы данных.
Таким образом, стратегия дублирования наиболее применима в ситуациях, когда объем данных невелик, фактор доступности и надежности обращения к данным играет значительную роль, а интенсивность обновления данных невысока. Последнее обстоятельство наиболее характерно для информационно-поисковых систем.
Смешанная стратегия. Эта стратегия распределения данных объединяет подходы, используемые при расчленении и дублировании, с целью приобретения преимуществ последних. Но в то же время смешанная стратегия не лишена недостатков, присущих своим прототипам.
Использование смешанной стратегии предполагает деление БД на логические фрагменты (расчленение) и наличие в сети произвольного числа их физических копий, называемых хранимыми фрагментами (дублирование). Общность стратегии состоит в том, что любая часть базы может быть дублирована произвольное число раз, при этом в каждом узле может храниться желаемое подмножество данных.
Основным преимуществом смешанной стратегии, несомненно, является гибкость. Это важное свойство позволяет достичь компромисса между объемом памяти, используемой в целом и в каждом узле, с одной стороны, и обеспечиваемым уровнем надежности и оперативности, с другой. Например, архивные данные могут храниться в одном узле, а часто используемые могут быть дублированы. При дублировании логического фрагмента усложняются процедуры обновления хранимых фрагментов, но значительно большее количество данных становится локально доступным, то есть повышается степень локализации ссылок. Последнее ведет к снижению транспортных издержек за счет уменьшения числа пересылок. Стратегия допускает довольно простую организацию параллельной обработки, что ведет к уменьшению времени реакции на запросы. Появляется возможность обхода узких мест в сети передачи данных.
Недостатком смешанной стратегии является необходимость хранения информации о местонахождении данных в сети. Нетрудно заметить, что без наличия такой справочной информации невозможна реализация стратегии расчленения. Однако в последнем случае всегда можно указать однозначное соответствие между логическим фрагментом, с одной стороны, и узлом, в котором расположена его физическая копия, с другой.
В свою очередь, смешанная стратегия характеризуется многозначностью подобного соответствия, что существенно увеличивает объем справочных данных и требует введения процедур оптимизации доступа к хранимым фрагментам. Сложности возникают также при согласовании произвольного числа хранимых фрагментов, связанных с каждым логическим фрагментом. Обработка и оптимизация запросов являются нетривиальными задачами.
Рассматриваемая стратегия может быть рекомендована к реализации тогда, когда ни одна из более простых стратегий не признается удовлетворительной. Например, необходимо обеспечить выполнение высоких требований по надежности, предъявляемых к отдельным частям большой по объему БД. При этом каждый узел может обращаться к некоторым частям базы довольно часто, а к остальным – значительно реже. В этом случае стратегия расчленения не может обеспечить достаточной надежности, а стратегия дублирования может быть неприемлемой из-за требований на объем памяти в узлах.
Подводя итог рассмотрению стратегий, следует заметить, что первоочередные проблемы, связанные с распределением данных в сети, подлежат разрешению на стадии проектирования РБД, которая имеет ряд существенных особенностей по сравнению с проектированием локальных БД.
В распределенной информационной системе логически целостная БД может быть фрагментирована и широко распределена по сети с целью улучшения производительности и надежности ИС. Фрагментация и распределение данных без централизованного планирования часто являются причиной несогласованного использования данных. Поэтому последовательность этапов проектирования РБД должна учитывать этот факт.
Приведем краткую характеристику этапов проектирования РБД.
- Этап анализа предметной области. Его реализация предполагает изучение и описание предметной области, а также анализ пользовательских потребностей в информации.
- Этап концептуального проектирования. По результатам предыдущего этапа разрабатывается инфологическая модель (информационная структура) предметной области.
- Этап логического проектирования (проектирования реализации). Вовремя его проведения осуществляется выбор системы управления РБД и наложение ограничений выбранной СУРБД на информационную структуру. Результатом логического проектирования выступает глобальная структура БД.
- Этап расчленения базы данных. Рассматриваемый этап связан с делением глобальной БД на логические фрагменты. При решении задачи расчленения учитывают требования к обработке данных, характеристики выбранной СУРБД, а также характеристики технических и программных средств в узлах сети. Результатами являются совокупность логических фрагментов и размер каждого из них.
- Этап размещения базы данных. На этом этапе решается задача выбора узлов сети для размещения в них хранимых фрагментов, соответствующих логическим фрагментам БД. Определенные ограничения накладывают требования по обработке данных и разграничению доступа, особенности сети передачи данных (ее топология, пропускная способность каналов), а также характеристики аппаратуры и программного обеспечения узлов вычислительной сети. Решение представляет собой перечень узлов, с каждым из которых связан список фрагментов БД.
- Этап проектирования локальных баз данных. Является заключительным в рассматриваемой последовательности. На нем осуществляется проектирование физических структур локальных БД, образованных в результате выполнения всех процедур предшествующих шагов.
Главное различие процессов проектирования РБД и локальных БД состоит в наличии этапов расчленения и размещения БД, которые поэтому заслуживают более подробного рассмотрения.
При расчленении исходная глобальная база разделяется на множество логических фрагментов, называемых также разделами. Естественно, что должно выполняться требование о сохранении информации, то есть разделы должны содержать все сведения, имеющиеся в исходной глобальной базе. Дополнительно на процесс формирования разделов накладываются ограничения по их допустимому размеру, времени реакции на запрос и надежности обращения.
Вследствие этого в раздел рекомендуется объединять такие часто используемые совместные записи, чтобы он улучшал характеристики времени ответа на запрос. Также следует стремиться к получению требуемого уровня надежности, используя по возможности меньшую кратность дублирования, то есть степень локализации ссылок должна быть высокой при минимальном числе копий хранимых фрагментов. Допустимый размер каждого раздела как неделимой совокупности данных определяется фиксированным объемом памяти в каждом узле сети. И в общем случае ограничения на класс допустимых расчленений накладывает емкость внешних запоминающих устройств в узлах сети.
Задача размещения распределенной базы данных решается сравнительно просто для двух стратегий: централизации и дублирования. Вполне очевидно, что отпадает необходимость в выполнении процедуры расчленения базы данных. Если принята первая стратегия, то перед разработчиком стоит один вопрос: в каком узле следует разместить базу данных? Реализация второй стратегии для каждого узла сети требует решения вопроса: размещать или не размещать полную копию базы? Ответы на поставленные вопросы зачастую предопределены и зависят от структуры сети, объема памяти в ее узлах, перечня альтернатив и здравого смысла.
Значительно сложнее представляется задача размещения при использовании стратегии расчленения, особенно сложной при смешанной стратегии. В случае реализации стратегии расчленения необходимо: во-первых, расчленить базу на логические фрагменты и, вовторых, разместить каждый фрагмент в конкретном узле с учетом ограничений на размещение. Задача является итеративной, и возможно, что расчленение базы данных потребуется проводить неоднократно.
Если же используется смешанная стратегия, решение становится более сложным: каждый логический фрагмент может быть размещен в любом числе узлов. Количество перестановок фрагментов растет очень быстро, и это является одной из причин того, что ограничиваются нахождением не оптимального, а рационального размещения.
Решение задачи оптимального размещения фрагментов по узлам сети методами линейного программирования возможно при довольно жестких допущениях о характере потока запросов к базе, предопределенном числе и неизменности этих запросов, заранее известном числе хранимых фрагментов.
Количество переменных и ограничений прогрессирует с увеличением числа узлов сети, и поэтому получение решения возможно лишь для задач малой размерности. Решение также усложняется при предъявлении менее жестких требований к характеру запросов пользователей. Подходы к решению используют в своей основе метод динамического программирования. Если же типовые запросы первоначально неизвестны, то используются статистические методы для определения этих запросов, а результаты их определения служат входными данными для решения задачи размещения.
В целом процесс разработки распределенных баз данных отличается высокой трудоемкостью и значительными материальными затратами. Задача выбора наилучшего соответствия между характеристиками РБД и методами распределения данных в сети требует всестороннего анализа, так как принятые проектные решения оказывают непосредственное влияние на реализацию и последующее функционирование информационной системы.
Очевидно, что распределенные БД, в отличие от локальных баз, должны потребовать большего числа уровней представления данных для реализации принципа независимости описания структуры баз от данных. Действительно, трехуровневая архитектура в случае РБД расширяется до пяти уровней (рис. 7).
Пользовательский уровень представления данных. Служит для описания части базы данных, доступной одному конкретному пользователю или группе пользователей, рассматриваемых как один. Эта часть многоуровневого представления является, по сути, внешней моделью в концепции ANSI. Каждый пользователь может иметь отличное от других пользователей представление, соответствующее его требованиям и требованиям разграничения доступа.
Глобальный логический уровень представления данных. Этот уровень подобен концептуальному уровню представления концепции ANSI. Используется для описания логической структуры всей распределенной базы данных, то есть в представлении администратора РБД. При описании РБД этому уровню ставится в соответствие глобальная представляющая схема.
Существование третьего и четвертого уровней объясняется распределенной природой РБД.
Фрагментный уровень представления данных. Используя этот уровень, администратор РБД определяет несвязанные подмножества базы данных, то есть логические фрагменты, и описывает их средствами СУБД в виде локальных представляющих схем.
Уровень представления распределения данных. На данном уровне определяется географическое расположение экземпляров каждого логического фрагмента. Уровень допускает существование нескольких физических фрагментов, соответствующих логическому фрагменту. Этому уровню соответствует схема распределения данных.
Уровень локального представления данных. Соответствует описанию той части базы данных, которая существует в конкретном узле.
Несомненно, что эта локальная база может рассматриваться с точки зрения, как логической, так и физической структуры. Однако локальное представление считается описанием логической структуры, при этом физическая структура является скрытой от администратора РБД. Локальная БД как база в полном понимании этого слова имеет несколько уровней представления, но в данном рассмотрении эти уровни не принимают участия.
Рис. 7. Уровни представления данных в РБД
При обращении множества пользователей или прикладных программ к распределенной базе данных на первый план выдвигается проблема управления параллельным выполнением запросов к СУРБД. Обязательным условием является то, что каждый запрос, связанный с корректировкой данных, должен оставлять РБД в непротиворечивом состоянии.
В таком случае по окончании исполнения запроса необходимо установить, что СУРБД завершила выполнение всех подзапросов, изменяющих данные. При подобном подходе исключается возможность использования информации, определяемой переходным состоянием базы данных. Данное условие может выполняться поразному в зависимости от времени проведения операций обновления данных.
Оперативная актуализация проводится в реальном масштабе времени, а периодическая – в некоторые установленные моменты после накопления изменений данных. В последнем случае выполнение запросов на выборку данных при обновлении блокируется. Реализация периодической актуализации представляется довольно простой, однако данный подход не может быть признан удовлетворительным для использования в базах данных, являющихся информационными моделями систем, состояние которых подвержено частым изменениям.
При оперативной актуализации действия над данными, проводимые в соответствии с различными запросами, могут выполняться СУРБД параллельно. При этом возникает несколько ситуаций, когда операция над данными может быть не завершена. Это тупиковые ситуации и циклические рестарты. Тупиковые ситуации характеризуются тем, что операции в нескольких запросах (транзакциях) вынуждены ждать завершения друг друга.
Явление циклического рестарта связано с периодическим попаданием транзакции в такое состояние, когда ее выполнение становится невозможным, после чего она отменяется, а затем производится повторный запуск. Механизм управления параллельным выполнением транзакций должен либо исключать подобные ситуации, либо обеспечивать их разрешение. К основным методам, позволяющим корректно завершать выполнение оперативной актуализации распределенной базы данных и оставлять ее в непротиворечивом состоянии, относят методы: блокировок данных, согласия большинства и предварительного анализа конфликта транзакций.
Метод блокировок данных. Данный метод является наиболее распространенным. На практике применяются две его модификации, различающиеся выбранным способом управления. При централизованной блокировке в сети выделяется главный распределитель ресурсов, которому направляются все требования транзакций по блокировке изменяемых данных. С получением права пользования ресурсом транзакция актуализации осуществляет доступ к данным в любом узле, хранящем копию.
Для обеспечения гарантированного использования непротиворечивых данных транзакции, осуществляющие только операции чтения, должны придерживаться принятой дисциплины доступа к данным. Реализация децентрализованной блокировки устраняет главный недостаток предыдущей модификации – низкую степень параллелизма и малую живучесть системы управления БД, но при этом не исключается возможность образования тупиков.
Метод согласия большинства. При использовании названного метода узлам предоставлено право решать вопрос об изменении данных по конкретному запросу «голосованием». Это позволит разрешить конфликтные ситуации, возникающие при обращении к данным, и полностью исключить тупиковые ситуации. Степень параллельного выполнения транзакций та же, что и при децентрализованной блокировке данных.
Сущность метода согласия большинства состоит в следующем. С каждым компонентом базы данных связывается временная метка, фиксирующая момент его последнего изменения. Операторы изменения данных принимаются к исполнению только в том случае, если они относятся к транзакциям, выполнение которых началось позднее времени, указанного в метке. В операторах изменения указываются: уникальный код транзакции, ее временная метка, список изменяемых ресурсов, новые значения данных, список базовых ресурсов (используемых при формировании изменения), значения их временных меток и т.д. При получении оператора узел обязан выполнить одно из следующих действий:
- Проголосовать отрицательно (отклонить оператор) в случае, если нарушено условие соотношения временных меток, указанное ранее, и временные метки базовых ресурсов, сообщенные в операторе, относятся к более ранним моментам, чем фактически зафиксированные в узле;
- Проголосовать положительно (принять оператор) при условии, что все соотношения временных меток являются удовлетворительными и данный оператор не вступает в конфликт с другим активным оператором. (Конфликт возможен, если активный оператор, то есть не принятый и не отклоненный, пытается изменить базовый ресурс рассматриваемого оператора или модифицируемый рассматриваемым оператором ресурс является базовым для любого активного оператора);
- Воздержаться от голосования, когда соотношение временных меток является удовлетворительным, но имеет место конфликт с другими активными операторами.
Метод предварительного анализа конфликта транзакций. Этот метод предполагает анализ возможности возникновения конфликта и его характера. Каждому виду конфликта ставится в соответствие специализированный протокол синхронизации транзакций, эффективно разрешающий возникшую ситуацию. В основе работы протокола находится техника временных меток.
Предварительный анализ ситуации, проводимый центральным узлом, исключает образование тупиковых ситуаций.
Выбор того или иного метода для его последующей реализации зависит от конкретных приложений. Выработка общих рекомендаций является затруднительной вследствие отсутствия сведений о достигаемых значениях показателей эффективности функционирования различных СУРБД.