Data Mining как совокупность большого числа различных методов обнаружения знаний
Data Mining — это методология и процесс обнаружения в больших массивах данных, накапливающихся в информационных системах компаний, ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Data Mining является одним из этапов более масштабной методологии Knowledge Discovery in Databases.
Знания, обнаруженные в процессе Data Mining, должны быть нетривиальными и ранее неизвестными. Нетривиальность предполагает, что такие знания не могут быть обнаружены путем простого визуального анализа. Они должны описывать связи между свойствами бизнес-объектов, предсказывать значения одних признаков на основе других и т. д. Найденные знания должны быть применимы и к новым объектам.
Практическая полезность знаний обусловлена возможностью их использования в процессе поддержки принятия управленческих решений и совершенствовании деятельности компании.
Знания должны быть представлены в виде, понятном для пользователей, которые не имеют специальной математической подготовки.
Data Mining — это не один, а совокупность большого числа различных методов обнаружения знаний. Все задачи, решаемые методами Data Mining, можно условно разбить на шесть видов:
- классификация;
- регрессия;
- кластеризация;
- ассоциация;
- последовательные шаблоны;
- анализ отклонений.
Data Mining носит мультидисциплинарный характер, поскольку включает в себя элементы численных методов, математической статистики и теории вероятностей, теории информации и математической логики, искусственного интеллекта и машинного обучения.
Задачи бизнес-анализа формулируются по-разному, но решение большинства из них сводится к той или иной задаче Data Mining или к их комбинации. Например, оценка рисков — это решение задачи регрессии или классификации, сегментация рынка — кластеризация, стимулирование спроса — ассоциативные правила. Фактически задачи Data Mining являются элементами, из которых можно собрать решение большинства реальных бизнес-задач.
Для решения вышеописанных задач используются различные методы и алгоритмы Data Mining. Большую популярность получили следующие методы: нейронные сети, деревья решений, алгоритмы кластеризации, в том числе и масштабируемые, алгоритмы обнаружения ассоциативных связей между событиями и т. д.
Основателем и одним из идеологов Data Mining считается Пятецкий-Шапиро. Впервые термин был введен в 1989 году на одном из семинаров, посвященных технологиям поиска знаний в базах данных, проводимых в рамках Международной конференции по искусственному интеллекту (International Joint Conference on Artificial Intelligence) IJCAI-89.
1. Линейная регрессия
Линейная регрессия представляет собой модель зависимости между входными и выходными переменными c линейной функцией связи.
Линейная регрессия является одним из наиболее часто используемых алгоритмов в машинном обучении. Этот алгоритм зачастую дает хороший результат даже на небольших наборах данных.
Широкое применение линейной регрессии обусловлено тем, что большое количество реальных процессов в науке, экономике и бизнесе можно описать линейными моделями. Так, с помощью линейной регрессии можно оценивать объем ожидаемых продаж в зависимости от установленной цены.
Обработчик может использоваться для решения различных задач Data Mining, например таких как прогнозирование и численное предсказание.
Для отбора переменных в модель линейной регрессии могут использоваться несколько методов:
- принудительное включение (Enter) — включение в регрессионную модель всех заданных признаков независимо от того, оказывают ли они значимое влияние или нет;
- пошаговое включение (Forward) — метод, который базируется на принципе: начать с отсутствия признаков и постепенно найти самые лучшие, которые будут добавлены в подмножество;
- пошаговое исключение (Backward) — метод основан на следующем: начать со всех доступных признаков и последовательными итерациями исключить самые худшие;
- пошаговое включение/исключение (Stepwise) — модификация метода Forward с тем отличием, что на каждом шаге после включения новой переменной в модель осуществляется проверка на значимость остальных переменных, которые уже были введены в нее ранее;
- Ridge — один из методов понижения размерности. Применяется для борьбы с переизбыточностью данных, когда независимые переменные коррелируют друг с другом (мультиколлинеарность), вследствие чего проявляется неустойчивость оценок коэффициентов линейной регрессии;
- LASSO — так же как и Ridge, применяется для борьбы с переизбыточностью данных;
- Elastic-Net — модель регрессии с двумя регуляризаторами L1, L2. Частными случаями являются модели LASSO L1 = 0 и Ridge регрессии L2 = 0. Оба регуляризатора помогают улучшить обобщение и ошибки теста, поскольку не допускают переобучения модели из-за шума в данных:
- L1 — реализует это путем отбора наиболее важных факторов, которые сильнее всего влияют на результат;
- L2 — предотвращает переобучения модели путем запрета на непропорционально большие весовые коэффициенты.
Для критерия отбора факторов можно выбрать один из следующих информационных критериев:
- F-тест;
- коэффициент детерминации;
- скорректированный коэффициент детерминации;
- информационный критерий Акаике;
- информационный критерий Акаике скорректированный;
- информационный критерий Байеса;
- информационный критерий Ханнана – Квина;
- порог значимости при добавлении фактора;
- порог значимости при исключении фактора.
Несмотря на свою универсальность, линейная регрессионная модель не всегда пригодна для качественного предсказания зависимой переменной. Например, при нелинейной зависимости. В этом случае нелинейная модель сводится к линейной путем линеаризации переменных.
Кроме того, если выходная переменная является категориальной или бинарной, приходится использовать различные модификации регрессии. Одной из таких модификаций является логистическая регрессия, предназначенная для оценки вероятности того, что зависимая переменная примет значение 0 или 1.
Сферы применения
- Анализ эластичности спроса по цене, характеризующей реакцию потребительского спроса на изменение цены товара. Можно построить модель продаж, где в качестве входной переменной будет использоваться цена, а в качестве выходной — объем продаж.
- Прогнозирования объема продаж. Регрессия строится на основе временного ряда продаж за репрезентативный период. Данная модель является базисом для формирования оптимального плана закупок и товарно-финансовых планов.
- Прогнозирование стоимости ценных бумаг. Регрессионная модель строится на основе таких показателей, как чистая прибыль компании, доход, рентабельность выручки компании, балансовой стоимости и прочее.
- Прогнозирование загруженности веб-сервиса. Резкие всплески интереса могут повысить нагрузку на серверы и отрицательно сказаться на качестве работы веб-сервиса. Эта задача особенно актуальная, если вычислительные ресурсы арендуются в облаке, где имеется возможность гибко управлять мощностями доступных серверов.
Пример применения в Loginom Community
Имеются данные имеются данные об объеме услуг связи, оказанных населению, и о тех факторах, которые могут влиять на них (рис. 1).
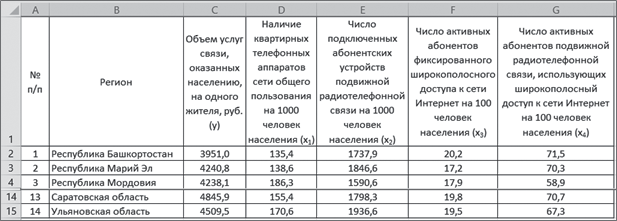
Рис. 1
Требуется установить зависимость объема услуг связи от перечисленных факторов.
Разработанный сценарий расчетов имеет вид (рис. 2).
Рис. 2
После завершения работы Мастера обработки выводятся данные визуализаторов Выход регрессии, Коэффициенты регрессионной модели и Отчет по регрессии.
В визуализаторе Выход регрессии представлены расчетные значения результативного признака (рис. 3).
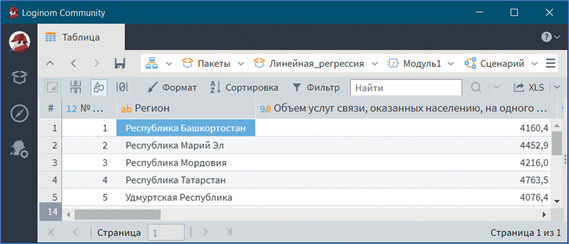
Рис. 3
В визуализаторе Коэффициенты регрессионной модели приведены регрессионные коэффициенты, их интервальная оценка и уровень статистической значимости (рис. 4).
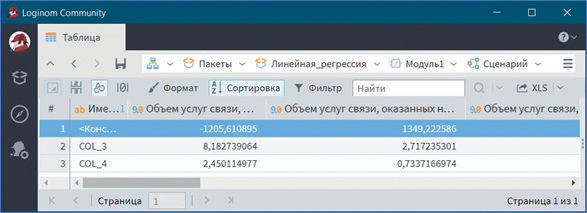
Рис. 4
Визуализатор Отчет по регрессии отображает параметры и результаты статистических тестов для анализа регрессионных моделей. Откроем данный визуализатор (см. рис. 5).
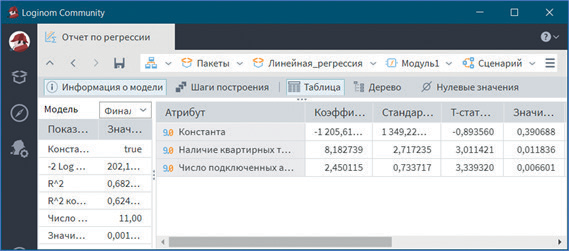
Рис. 5
Общее качество регрессионной модели определяется с помощью коэффициента детерминации R2. В отчете по регрессии Информация о модели его величина составляет 0,682. Поскольку максимальное значение R2 = 1, то можно утверждать, что качество регрессионной модели весьма высокое (предлагаемая модель объясняет около 68,2 % дисперсии результативной переменной). Здесь же представлены данные дисперсионного анализа, из которых следует статистическая значимость модели в целом при уровне значимости 0,05.
В отчете по регрессии Таблица приведены регрессионные коэффициенты и уровень их статистической значимости.
Как следует из отчета, построенная регрессионная модель имеет вид:
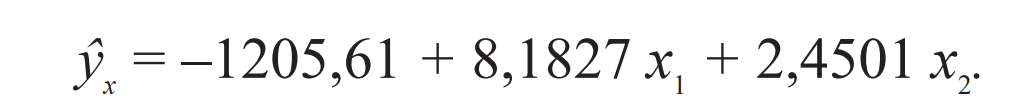
Все параметры уравнения значимы при заданном уровне значимости 0,05.
Таким образом на объем услуг связи, оказанных населению, на одного жителя оказывают существенное влияние наличие квартирных телефонных аппаратов сети общего пользования и число подключенных абонентских устройств подвижной радиотелефонной связи на 1000 человек населения. Так, увеличение количества квартирных телефонных аппаратов сети общего пользования на 1000 человек населения на 1 шт. позволяет повысить объем услуг связи, оказанных населению, на одного жителя на 8,18 руб., а числа подключенных абонентских устройств подвижной радиотелефонной связи на 1000 человек населения на 1 шт. — на 2,45 руб.
Полученное уравнение регрессии, кроме оценки влияния отдельных факторов на объем услуг связи, оказанных населению, на одного жителя позволяет прогнозировать их в зависимости от величины данных факторов. При этом факторы, влияющие на объем услуг связи, оказанных населению, должны находиться в пределах их изменения в исходной выборочной совокупности.
2. Логистическая регрессия
Логистическая регрессия — это разновидность множественной регрессии, общее назначение которой состоит в анализе связи между несколькими независимыми переменными и зависимой переменной. С помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (больной/здоровый, возврат кредита/дефолт и т. д.).
Для построения модели логистической регрессии готовится обучающая выборка. Для это множество разделяется на обучающее и тестовое:
- обучающее множество — cтруктурированный набор данных, применяемый для обучения аналитических моделей. Каждая запись обучающего множества представляет собой обучающий пример, содержащий заданное входное воздействие и соответствующий ему правильный выходной (целевой) результат;
- тестовое множество — подмножество обучающей выборки, содержащее тестовые примеры, то есть примеры, использующиеся не для обучения модели, а для проверки его результатов.
Под обучением понимается расчет коэффициентов регрессионной модели. В Loginom строится бинарная логистическая регрессия путем решения нелинейного уравнения итерационным методом Ньютона. Параметры обучения логистической модели следующие:
- точность решения — критерий остановки итераций. Настройка, которая позволяет определить точность нахождения минимума функции ошибки. Значение вещественного типа от 0 до 1. Представляет собой редактор с шагом изменения значения 0,000001;
- порог отсечения — определяет расчетное значение уравнения регрессии. Значение вещественного типа от 0 до 1. Представляет собой редактор с шагом изменения значения 0,1;
- включить в модель константу — добавляет в модель зависимую переменную.
Для критерия отбора факторов можно выбрать один из следующих информационных критериев:
- отношение правдоподобия;
- информационный критерий Акаике;
- информационный критерий Акаике скорректированный;
- информационный критерий Байеса;
- информационный критерий Ханнана-Квина.
Сферы применения
- Кредитный скоринг. С помощью данного алгоритма решается одна из ключевых задач управления кредитными рисками в банковской сфере — оценка кредитоспособности заемщиков. Согласно опросам риск-аналитиков, 99 % моделей анкетного скоринга сегодня строится на базе логистической регрессии.
- Оценка диагностических тестов. С помощью алгоритма можно подобрать оптимальные пороги диагностических показателей, оценить чувствительность и специфичность модели, рассчитать ложноположительные и ложноотрицательные результаты. Это позволяет сделать тесты более эффективными в сравнении с традиционными методиками.
- Диагностика финансового состояния. Алгоритм оценивает зависимость состояния предприятия от показателей финансовой устойчивости, ликвидности, рентабельности, деловой активности. Это позволяет предупреждать возможности возникновения кризисной ситуации, сохранить устойчивое финансовое состояние и повысить эффективность предпринимательской деятельности.
Пример применения в Loginom Community
Имеются данные о кредитных историях 700 клиентов банка и 150 клиентов, которые намерены обратиться в банк за кредитом. Информация о клиентах банка содержит такие данные: возраст, образование, стаж коммерческой деятельности, число полных лет постоянного места проживания, годовой доход (тыс. долларов США), долги (% к годовому доходу), долги по кредитной карте (тыс. долларов США), другие долги (тыс. долларов США), для клиентов, уже бравших кредит, являлся ли он должником банка (рис. 6).
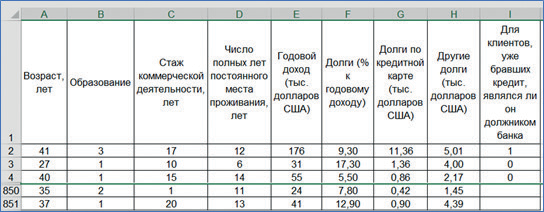
Рис. 6
Требуется, используя 70 % случайную выборку клиентов, уже бравших кредит в банке, создать регрессионную логистическую модель, позволяющую предсказать невозвращение кредита клиентом. Используя оставшиеся 30 % клиентов (проверочная совокупность), выяснить степень пригодности построенной модели для предсказания случаев невозвращения кредита клиентами банка. Определить, какие переменные могут быть без ущерба исключены из модели.
Разработанный сценарий расчетов имеет вид (см. рис. 7).
После завершения работы Мастера обработки выводятся данные визуализатора Отчет по регрессии, в котором представлена информация для анализа статистической значимости как всей модели, так и отдельных ее компонент (см. рис. 8).
Рис. 7
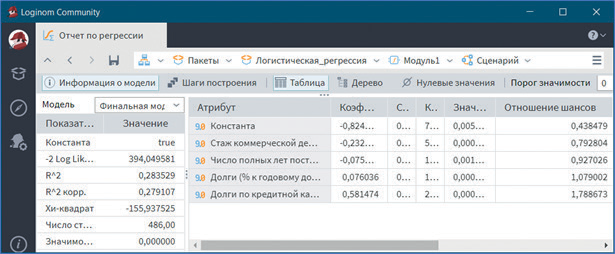
Рис. 8
Исходя из данных отчета значимость всей модели меньше заданного уровня 0,05, практически равна 0. Значимость большинства коэффициентов регрессии менее 0,006.
В целом делаем вывод, что модель статистически значима, и ее можно использовать для прогноза.
Данный визуализатор выводит помимо коэффициента для каждой регрессионной переменной отношение шансов (odds ratio). Здесь представлена, по сути, скоринговая карта.
Отношение шансов OR — это отношение вероятности того, что событие произойдет к вероятности того, что событие не произойдет:
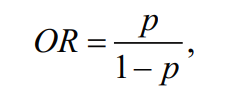
где p — вероятность успеха.
В логистической регрессии коэффициенты xi дают не только веса признаков, но и обладают полезным свойством. Рассчитав exp(xi) для конкретной переменной, получим отношение шансов для этой переменной.
Визуализатор Качество бинарной классификации выводит ROC-кривую (рис. 9) и основные метрики бинарных классификаторов (см. рис. 10).
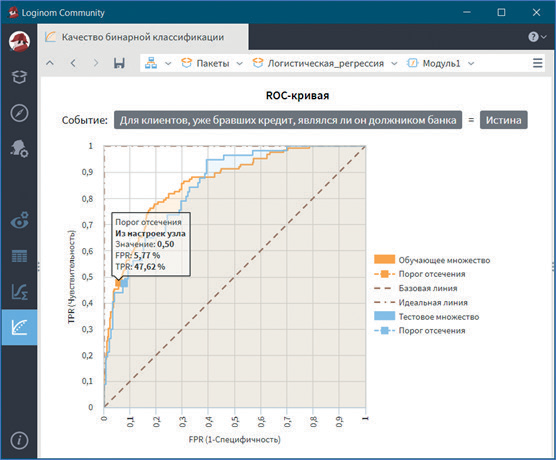
Рис. 9
ROC-кривая позволяет оценить качество бинарной классификации путем соотношения между долей объектов от общего количества носителей признака, верно классифицированных как несущие признак TPR и долей объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак FPR при варьировании порога решающего правила. При пороге отсечения 0,5 FRP равно 5,77 %, а TRP — 47,62 %, что свидетельствует о высоком качестве классификации, поэтому предсказательную способность модели можно охарактеризовать как очень хорошую (см. рис. 9).
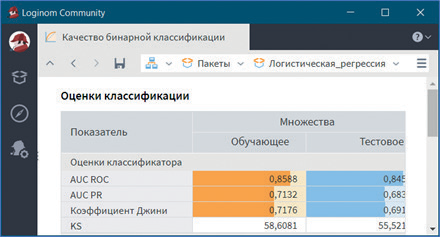
Рис. 10
ROC-кривая имеет площадь под кривой равной 0,86 (см. рис. 10).
Для оценки качества классификации разработана экспертная шкала для значений AUC ROC:
- 0,9–1,0 — отличное;
- 0,8–0,9 — очень хорошее;
- 0,7–0,8 — хорошее;
- 0,6–0,7 — среднее;
- 0,5–0,6 — неудовлетворительное.
Можно сдать вывод, что скоринговая карта отклика имеет очень хорошую предсказательную силу.
В таблице по обучающему и тестовому множествам приведены следующие показатели:
- AUC ROC — численное значение площади под ROC-кривой;
- AUC PR — численное значение площади под PR-кривой;
- Коэффициент Джини — численное значение индекса Джини;
- KS — процентное значение статистики Колмогорова Смирнова.
Все метрики мало отличаются друг от друга; следовательно, с высокой степенью вероятности можно утверждать о пригодности построенной модели для предсказания случаев невозвращения кредита клиентами банка.
3. Факторный анализ
Обработчик применяется с целью понижения размерности пространства факторов. Это необходимо в случаях, когда входные факторы коррелированы друг с другом, то есть взаимозависимы. В факторном анализе речь идет о выделении из множества измеряемых характеристик объекта факторов, более емко отражающих свойства объекта.
Первым этапом факторного анализа является выбор новых признаков, которые являются линейными комбинациями прежних и вбирают в себя большую часть общей изменчивости входных факторов. Поэтому они содержат большую часть информации, заключенной в первоначальных данных.
В обработчике Факторный анализ это осуществляется с помощью метода главных компонент. Он сводится к выбору новой ортогональной системы координат в пространстве наблюдений. В качестве первой главной компоненты избирают направление, вдоль которого массив данных имеет наибольший разброс, а выбор каждой последующей происходит так, чтобы разброс данных вдоль нее был максимальным, и, чтобы она была ортогональна другим главным компонентам, выбранным прежде.
При проведении факторного анализа используются следующие критерии значимости факторов:
- по собственному значению — отбираются только факторы с собственными значениями, равными или большими 1. Считается, что те факторы, у которых этот показатель меньше 1, не вносят значительного вклада в объяснение результата;
- по дисперсии — факторы отбираются по доле объясняемой дисперсии. В этом случае выбирают столько факторов, чтобы в сумме они объясняли не менее 70–75 % дисперсии. В отдельных вариантах порог дисперсии может достигать 85–90 %;
- задать число факторов — количество значимых факторов выбирается аналитиком самостоятельно.
Для получения окончательного решения используются следующие методы:
- без вращения — исходные факторы, полученные методом главных компонент, остаются без изменений;
- варимакс — критерием является упрощение описания каждого фактора. в результате максимизируется нагрузка на каждый фактор относительно небольшого числа переменных, а факторные нагрузки остальных переменных минимизируются. рекомендуется выбирать, когда требуется обеспечить высокую интерпретируемость результатов факторного анализа.
- квартимакс — данный критерий упрощает описание каждой переменной, то есть уменьшает число факторов, связанных с этой переменной.
Можно также ограничить число выходных факторов.
Сферы применения
- Сегментация клиентской базы. Для каждого клиента известно, сколько покупок в той или иной группе товаров он сделал. Каждая группа — это отдельный признак. Таким образом, получаются сотни факторов. Для повышения качества кластеризации необходимо сократить размерность признакового пространства, для чего используется метод главных компонент.
- Прогнозирование распространения инфекционного заболевания. В качестве исторических данных нередко используются исторические сведения о погоде (температура воздуха, влажность). Данная информация позволяет учесть факторы, благоприятно влияющие на размножение переносчиков заболевания. Поэтому каждый объект в выборке описывается десятками признаков. Так как изменения погодных условий, как правило, происходят постепенно, это приводит к наличию мультиколлинеарности в указанных данных. Для решения указанной проблемы в данной задаче может быть использован метод главных компонент.
Пример применения в Loginom Community
Имеются данные распределения областей Центрального федерального округа РФ по профессионально-квалификационной структуре руководителей и специалистов сельскохозяйственных предприятий. Для характеристики профессионально-квалификационной структуры было отобрано девять показателей (рис. 11).
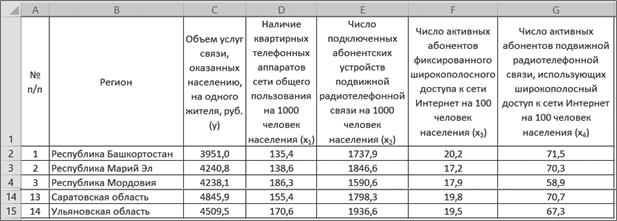
Рис. 11
Требуется:
- построить матрицу факторных нагрузок, используя метод главных компонент;
- выделить главные факторы, определяющие уровень обеспеченности кадрами;
- найти численные значения главных компонент для всех объектов наблюдения.
Разработанный сценарий расчетов имеет вид (рис. 12).
Рис. 12
После завершения работы Мастера обработки выводятся данные визуализаторов Факторные нагрузки и Факторы.
В визуализаторе Факторные нагрузки представлена матрица факторных нагрузок (рис. 13), а в визуализаторе Факторы — численные значения выделенных факторов (рис. 14). Всего выделено три фактора.
Из таблицы на рисунке 13 видно, что первый фактор наиболее тесно связан с такими показателями, как: обеспеченность руководителями и специалистами от штатной потребности, в том числе с высшим и средним образованием; доля руководителей и специалистов с высшим и средним образованием в общей численности, в том числе с высшим образованием; доля практиков в общей численности. Причем связь его с таким показателем, как доля практиков в общей численности руководителей и специалистов, является отрицательной. Данные показатели характеризуют как обеспеченность кадрами в целом, так и их квалификацию (наличие высшего и среднего образования), поэтому первый фактор целесообразно назвать Обеспеченность кадрами.
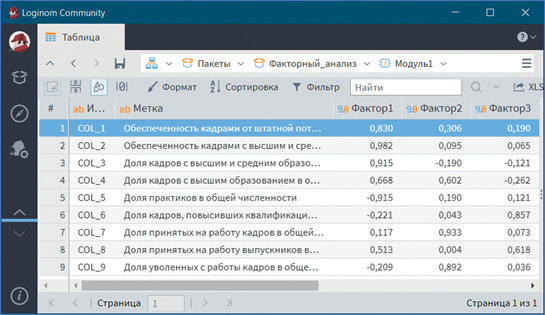
Рис. 13
Второй фактор можно определить как Текучесть кадров, поскольку он имеет наибольшие положительные нагрузки на показатели доли руководителей и специалистов, принятых на работу и уволенных с работы в общей их численности.
Третий фактор характеризует рост образовательного уровня кадров, так как определяется долей руководителей и специалистов, повысивших квалификацию, и долей принятых на работу выпускников высших и средних учебных заведений. Поэтому данный фактор можно назвать Подготовка кадров.
Таким образом, девять исходных показателей были сведены к трем факторам, которые характеризуют основные стороны профессионально-квалификационной структуры кадров управления АПК.
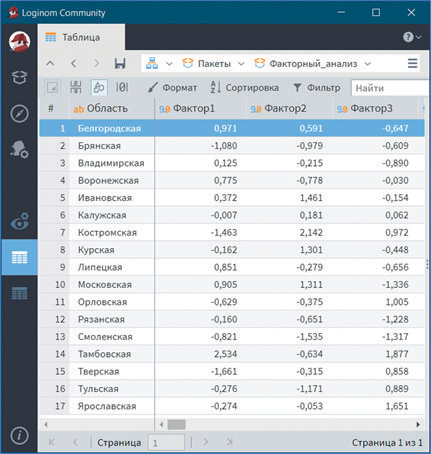
Данные таблицы на рисунке 2.37 позволяют определить, какое место занимают исследуемые области по уровню обеспеченности кадрами руководителей и специалистов сельскохозяйственных предприятий, текучести кадров и их подготовке.
Так, более высокий уровень обеспеченности руководителями и специалистами в Тамбовской области. В ней наиболее высокая обеспеченность кадрами от штатной потребности, в том числе с высшим и средним образованием, самый большой удельный вес руководителей и специалистов с высшим и средним образованием и самая низкая доля практиков (рис. 15). Также данной области принадлежит первое место по уровню подготовки кадров (рис. 16), а по уровню текучести кадров она занимает лишь двенадцатое место (рис. 17). Наиболее высокий уровень текучести кадров в Костромской области, по значениям таких показателей, как доля принятых на работу и уволенных с работы, она занимает соответственно первое и третье места.
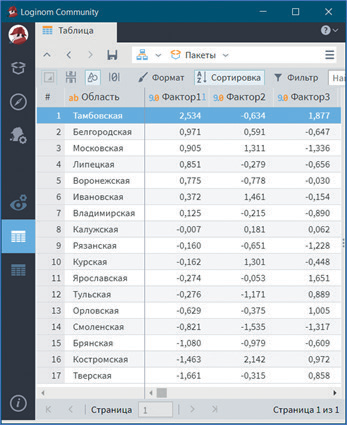
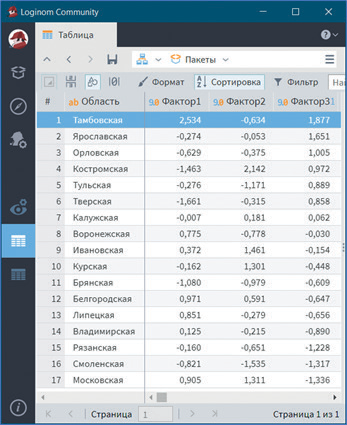
Рис. 16
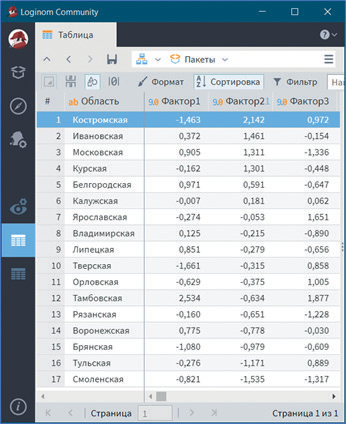
Рис. 17
4. Кластеризация
Кластеризация (сегментация) — это объединение объектов или наблюдений в непересекающиеся группы, называемые кластерами, на основе близости значений их признаков. В результате в каждом кластере будут находиться объекты, похожие по своим свойствам друг на друга и отличающиеся от объектов, которые содержатся в других кластерах. При этом чем больше подобие объектов внутри кластера и чем сильнее их отличие от объектов в других кластерах, тем лучше кластеризация.
Кластеризация позволяет добиться следующих целей:
- улучшает понимание данных за счет выявления структурных групп;
- разбиение набора данных на группы схожих объектов позволяет упростить дальнейшую обработку и принятие решений, применяя к каждому кластеру свой метод анализа;
- позволяет компактно представлять и хранить данные. Для этого вместо хранения всех данных можно оставить по одному типичному наблюдению из каждого кластера;
- поиск новизны — обнаружение нетипичных объектов, которые не попали ни в один кластер.
Обработчик Кластеризация производит кластеризацию объектов на основе алгоритмов k-means и g-means. Основное отличие одного алгоритма от другого в том, известно ли заранее количество кластеров. Если количество кластеров известно, то применяется алгоритм k-means, в противном случае — g-means, который определяет это количество автоматически в рамках заданного интервала.
Сферы применения
- Сегментация и построение профилей клиентов. С помощью кластеризации можно выделить сегменты с группами похожих объектов. Данный алгоритм дает возможность выделить характерные признаки и персональные предпочтения клиентов, оценить наиболее и наименее доходные или активные сегменты. Это позволяет решить задачи разработки маркетинговых акций, направленных на определенные сегменты клиентов, повышает эффективность работы с ними.
- Выявление целевой аудитории — наиболее ценной, перспективной, влиятельной группы потребителей, на которую в первую очередь будет направлена маркетинговая стратегия. Позволяет решить задачи разработки рекламного сообщения и подбора медиаканалов для его размещения, позиционирования, выбора товарного ассортимента и каналов дистрибуции. Концентрация усилий на целевой аудитории обеспечит максимизацию прибыли в сегменте.
- Каннибализация товаров: продукты, находящиеся в одной рыночной нише, «поедают» друг друга, то есть конкурируют за потребителя между собой. Алгоритм дает возможность выделять товары, находящиеся в зоне риска, прогнозировать эффект каннибализации и управлять им.
- Анализ миграции клиентов — перемещение клиентов между поставщиками товаров и услуг, причиной которой является изменение их запросов со временем. Рассматриваемые алгоритмы позволяют прогнозировать миграцию клиентов, визуализировать ее, оценить изменение их ценности для компании, определить причину миграции. В результате происходит укрепление отношений с ценными клиентами и противодействие оттоку.
Пример применения в Deductor Studio
Имеются данные о обеспеченности населения лечебными учреждениями регионов Российской Федерации в 2018 г. (см. рис. 18).
Требуется провести кластерный анализ регионов, используя алгоритм k-means, и выяснить, существуют ли заметные различия в их обеспеченности населения лечебными учреждениями.
Разработанный сценарий расчетов имеет вид (см. рис. 19).
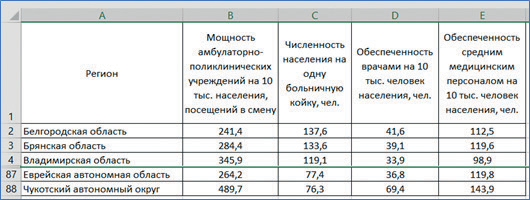
Рис. 18
Рис. 19
После завершения работы Мастера обработки выводятся данные визуализаторов Центры кластеров, Профили кластеров и Разбиение на кластеры.
Вначале откроем визуализатор Центры кластеров (рис. 20).
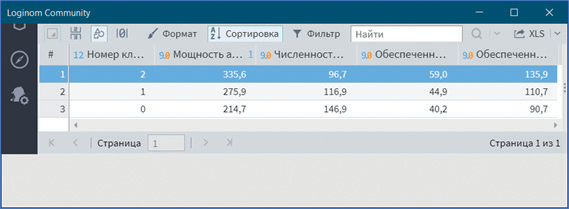
Рис. 20
Видно, что регионы, входящие в кластер 2, относятся к группе лучших по обеспеченности населения лечебными учреждениями, в кластер 1 — к группе средних и в кластер 0 — к группе худших. Об этом можно судить по средним значениям мощности амбулаторно-поликлинических учреждений, численности населения на одну больничную койку, обеспеченность врачами и средним медицинским персоналом.
В визуализаторе Профили кластеров можно посмотреть общую структуру сформированных кластеров (см. рис. 21–23).
В нем отображаются все рассматриваемые показатели вместе с характером влияния их на состав кластера. Основным определяющим состав кластера фактором является значимость свойств, выраженная в процентах. Общая значимость рассматриваемого поля определяется вариабельностью ее рассматриваемых параметров. Значимость для непрерывных и дискретных полей определяется по-разному. Для непрерывных полей она устанавливается в зависимости от отклонения среднего значения рассматриваемой группы кластеров от общего среднего всей выборки. Чем больше выражено данное отклонение, тем больше его значимость. Значимость для дискретных полей определяется наличием индивидуальных различий, между рассматриваемыми группами, чем больше выражены различия, тем больше значимость. Для каждого рассматриваемого свойства в кластере вычисляется: среднее, стандартное отклонение, стандартная ошибка и др. Приводится накопительная диаграмма.
Визуализатор Разбиение на кластеры позволяет определить принадлежность регионов к соответствующим кластерам (см. рис. 24).
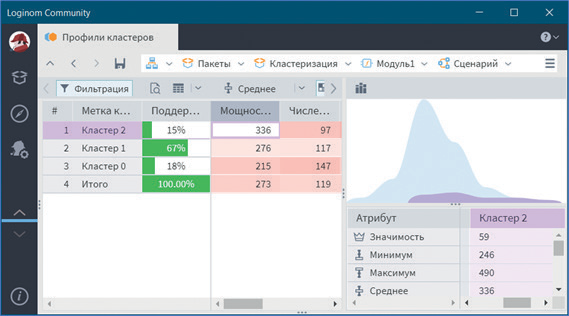
Рис. 21
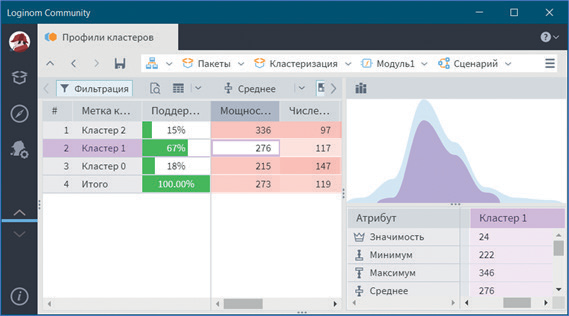
Рис. 22
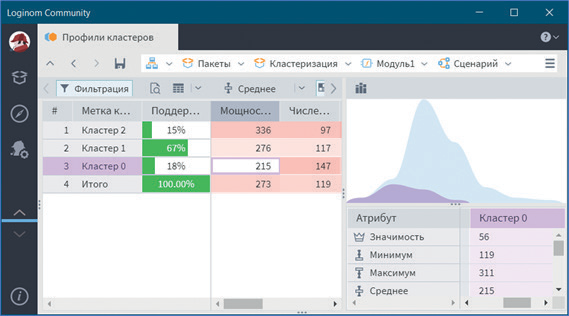
Рис. 23
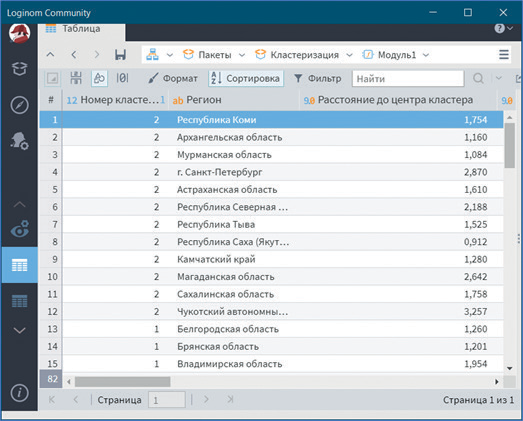
Рис. 24
5. Ассоциативные правила
Ассоциативные правила представляют собой метод анализа взаимосвязей между переменными в больших базах данных.
Обработчик Ассоциативные правила выявляет ассоциативные правила в транзакционных данных. Примером такого правила служит утверждение, что покупатель, приобретающий «Хлеб» (условие правила), купит и «Молоко» (следствие правила) с вероятностью 75 %. Транзакцией в данном примере является чек продажи, содержащий список приобретенных товаров, а каждый товар в чеке является элементом транзакции. При поиске ассоциативных правил применяется алгоритм FP-Growth.
Наряду с анализом основных данных транзакций возможно учитывать и вспомогательные. Например, если транзакцией является чек, а элементами — товары, то в качестве вспомогательных данных могут быть использованы: пол покупателя, возраст, регион, сезон и т. д. Фактически вспомогательные данные рассматриваются алгоритмом как еще одни элементы транзакций, и обозначение «вспомогательные» они имеют лишь в контексте аналитической задачи. Поскольку вспомогательные данные чаще представляются в источниках данных как дополнительные атрибуты транзакций, обработчик имеет отдельный вход для их приема. При выявлении ассоциативных правил задаются условия, по которым определяются частые предметные наборы — наборы элементов, наиболее часто встречающиеся в транзакциях. В дальнейшем только эти наборы участвуют в формировании правил:
- минимальная поддержка, % — минимальная частота, с которой набор встречается в транзакциях (значение 0 до 100);
- исключать элементы с поддержкой, больше максимальной — элементы, которые слишком часто встречаются в транзакциях, как правило, не несут информации о закономерностях сочетания с ними других элементов. Для их определения и исключения из частых наборов задается максимальная поддержка, % — максимальная частота, с которой элемент встречается в транзакциях (значение от 0 до 100);
- содержащие выбранные элементы — задает поля вспомогательного набора данных, содержащие дополнительные элементы транзакций;
- исключать одиночные наборы — исключает наборы из одного элемента;
- максимальное число элементов — задает максимальное количество элементов в наборе (максимальная мощность набора).
В результирующий набор попадают правила, удовлетворяющие следующим условиям:
- минимальная достоверность правила, % — позволяет отсеять наименее точные правила (значение от 0 до 100);
- минимальный лифт правила — значение лифта > 1 косвенно подтверждает значимость правила, поскольку говорит о положительной связи двух предметных наборов (условия и следствия правила). Значение лифта, равное или меньшее 1, говорит об отсутствии или отрицательной связи. Задавая минимальную величину лифта, можно отсеять наименее значимые правила;
- максимальное число следствий — максимальное количество элементов в наборе, представляющем следствие правила.
Сферы применения
- Анализ рыночной корзины (market basket analysis). Алгоритм выявляет типичные шаблоны покупок и совместно приобретаемых товаров. Полученные результаты позволяют оптимизировать ассортимент и его размещение в торговых залах, улучшить управление запасами, увеличить объемы продаж за счет предложения клиентам сопутствующих товаров.
- Кросс-продажи (cross-sell) и продажи с повышением цены (up-selling). Алгоритм позволяет на основании шаблонов потребительского поведения выявить клиентов, склонных к откликам на персональные предложения и кросс-продажам. Это дает возможность формировать предложения товаров и услуг эффективнее; обеспечивается индивидуальный подход к обслуживанию клиентов.
- Директ мейл (direct mail) — прямая адресная рассылка рекламных предложений потенциальным и существующим покупателям — является высокоэффективным, простым и дешевым маркетинговым инструментом. Для увеличения количества откликов на письма необходимо производить тщательный отбор объектов для рассылки посланий, чему способствует рассматриваемый алгоритм.
Пример применения в Loginom Community
Имеются данные для анализа потребительской корзины розничной сети, занимающейся продажей бытовой химии (рис. 25). Набор данных насчитывает 5000 чеков.

Рис. 25
Требуется для выявления совместно приобретаемых товаров в супермаркетах осуществить анализ потребительской корзины с помощью поиска ассоциативных правил.
Разработанный сценарий расчетов имеет вид (рис. 26).
Рис. 26
После завершения работы Мастера обработки выводятся данные визуализаторов Ассоциативные правила, Популярные наборы и Применение правил.
Сначала откроем визуализатор Ассоциативные правила (рис. 27). В нем представлен набор полученных простых правил, указаны значения поддержки, достоверности и лифта.
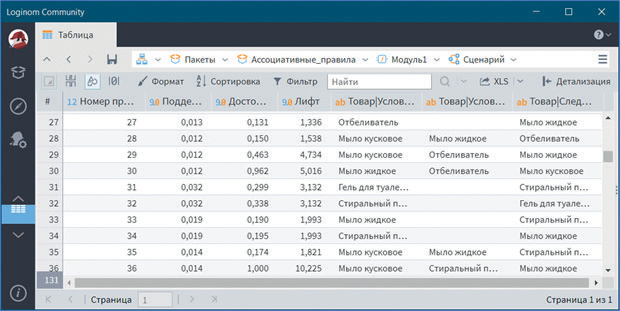
Рис. 27
Аналитику необходимо проанализировать каждое полученное правило и выбрать из них по-настоящему ценные. Например, правило под номером 30 показывает, что если покупается мыло жидкое, то будут куплены отбеливатель и мыло кусковое с достоверностью 96,2 %. Аналогично интерпретируются и остальные правила.
В визуализаторе Популярные наборы представлены наборы наиболее часто приобретаемых товаров, указаны значения поддержки и мощности (см. рис. 28).
В визуализаторе Применение правил по каждой транзакции описана ассоциативная связь между отдельными товарами и их наборами (см. рис. 29).
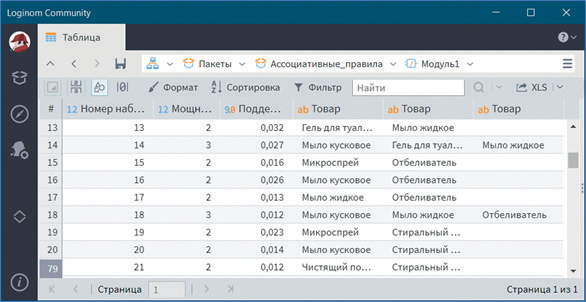
Рис. 28
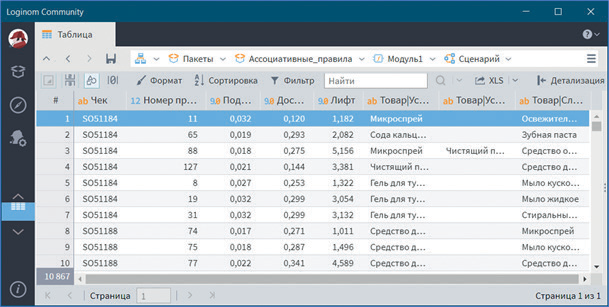
Рис. 29
6. Кластеризация транзакций
Кластеризация транзакций используется для обработки огромных массивов транзакционных данных, разбивая их таким образом, чтобы похожие операции оказались в одном кластере, а отличающиеся друг от друга — в разных.
В основе кластеризации транзакций лежит алгоритм CLOPE, применение которого позволяет обрабатывать огромные массивы транзакционных данных: чеки в супермаркетах, логи посещений веб-ресурсов и др. Задача состоит в получении такого разбиения всего множества транзакций, чтобы похожие транзакции оказались в одном кластере, а отличающиеся друг от друга — в разных кластерах.
Алгоритм автоматически подбирает количество кластеров. Аналитик может повлиять на результат с помощью коэффициента отталкивания, и назначения максимального числа кластеров или итераций.
Входными данными являются транзакции. Любые категориальные данные можно привести к транзакционным путем несложных преобразований. Требуемый вид данных представляет собой 2 поля, одно из которых является транзакцией, а второй — их элементами. Например, первый — код покупателя, второй — список его покупок.
С помощью коэффициента отталкивания регулируется уровень сходства транзакций внутри кластера, и, как следствие, финальное количество кластеров. Чем больше коэффициент, тем ниже уровень сходства и тем больше кластеров будет сгенерировано. По умолчанию значение коэффициента отталкивания установлено 2,6. Диапазон изменения значений — от 1 до 4.
При этом можно ограничить число кластеров, то есть вручную задать наибольшее количество кластеров, которые может выдать в результате алгоритм. Этим можно воспользоваться в случае, если задача требует определенного числа кластеров, например не больше 15.
Кроме того, можно ограничить число итераций, то есть прекратить работу алгоритма в случае, если количество итераций алгоритма превышает заданное максимальное число итераций. В алгоритме первый проход по таблице транзакций служит для построения начального разбиения, определяемого функцией стоимости, после чего для повышения качества кластеризации и оптимизации функции дополнительно сканируются таблицы несколько раз, пока изменения в разбиении не прекратятся. Ограничивать максимальное количество итераций следует в случае большого количества данных для предварительной оценки качества кластеризации.
Сферы применения
- Кластеризация клиентов на основании их поведенческих характеристик. Алгоритм позволяет выявить часто встречающиеся профили клиентов, обнаружить сходство в их рыночных корзинах. Это дает возможность строить эффективные программы лояльности, учитывающие особенности каждой группы покупателей, а не сводящиеся к банальному предоставлению скидок.
- Поведенческий таргетинг — использование информации о действии пользователя в интернете (просмотренных сайтах, поисковых запросах, покупках в интернет-магазинах и т. д.). Алгоритм позволяет четко представлять портрет объекта, узнать его привычки и пристрастия, на основании чего происходит выбор целевой аудитории, заинтересованной в предлагаемом товаре или услуге. Это дает возможность реализовывать более эффективные маркетинговые кампании, повышать эффективность взаимодействия с клиентами.
- Противодействие мошенничеству. Алгоритм позволяет выделить подозрительные транзакции, выполнить кластеризацию по группам и степени рисков. Эта информация является основой для построения риск-профиля компании и системы противодействия мошенничеству.
Пример применения в Loginom Community
Имеются данные для анализа потребительской корзины розничной сети, занимающейся продажей бытовой химии (рис. 30). Набор данных насчитывает 5000 чеков.
Требуется для выявления совместно приобретаемых товаров в супермаркетах осуществить анализ потребительской корзины с помощью кластеризации транзакций.
Разработанный сценарий расчетов имеет вид (рис. 31).

Рис. 30
Рис. 31
После завершения работы Мастера обработки выводятся данные визуализаторов Параметры кластеров, Мощность кластера и Разбиение на кластеры.
Сначала откроем визуализатор Параметры кластеров (см. рис. 32).
Видно, что в результате работы алгоритма получен 261 кластер, которые подробно описаны данным визуализатором. В визуализаторе отображено разбиение транзакций на кластеры и показаны характеристики каждого кластера: количество транзакций (N), ширина кластера (W) и мощность кластера (S). Например, кластер 0 имеют ширину 6, то есть в него вошел набор из 6 товаров. Количество транзакций данного кластера показывает, что 152 покупателя приобретали данный набор продуктов.
К тому же это самый мощный кластер, что наглядно показывает сортировка по столбцу Мощность кластера (см. рис. 33).
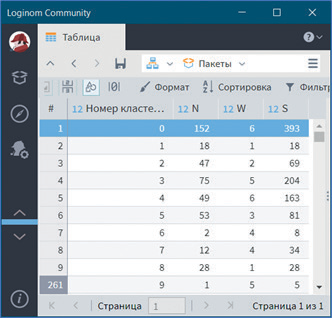
Рис. 32
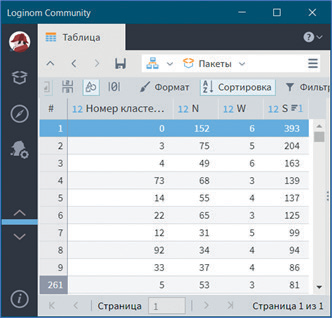
Рис. 33
В визуализаторе Разбиение на кластеры по каждой транзакции указано, к какому кластеру она относится (рис. 34).
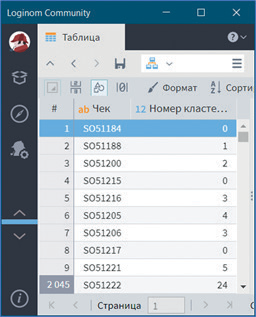
Рис. 34
В результате работы алгоритма выяснилось, что количество кластеров и итераций относительно невелико, то есть алгоритм быстро и качественно отработал. В данном примере можно было продолжить анализ с помощью алгоритма k-means, подавая на вход доли покупок клиентов.
Однако наибольший интерес в проведенном анализе представляют кластеры, содержащие тех клиентов, которые предпочитают только один вид товаров (см. рис. 35).
Такие монокластеры часто требуются в бизнес-задачах для принятия решений или построения стратегий, которые можно выявить алгоритмом CLOPE. Не во всех случаях это работает, однако алгоритм масштабируем и обладает высокой скоростью работы из-за нескольких проходов по базе данных, поэтому его можно использовать как предварительный этап кластеризации, не потратив на это много времени даже на огромных массивах данных.
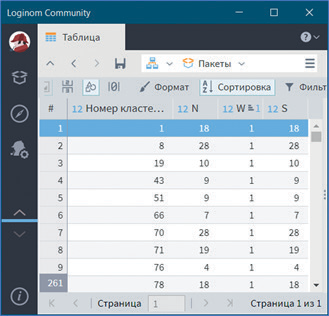
Рис. 35