Основы программирования на языке MQL5
Введение в основы программирования MQL5
В настоящее время существует огромное количество языков программирования, но все они имеют много общего, а некоторые элементы языка отличаются только синтаксисом.
Практически во всех языках есть средство, обеспечивающее многократное повторение одного и того же участка кода – циклы, но только записываются они по-разному. На MQL5 так:
for(int i=0;i<10;i++){
// какой-нибудь код
}
А, например, на Visual Basic так:
For index As Integer = 0 To 9 ‘ какой-нибудь код
Next
Главный факт в том, что и там и там есть возможность создания цикла.
Если бы компьютерная программа была ограничена только возможностями внутренней манипуляции с данными, от нее было бы мало пользы, каждый язык программирования должен иметь средства взаимодействия с окружающей средой: средства ввода, вывода данных и прочие функции – а это уже специфические возможности языка. Значит, сначала изучим такие основы MQL5, которые относятся к программированию в принципе: переменные, массивы, арифметические функции, выражения, условные операторы, циклы и т.п. Затем, специфические возможности: получение ценовых данных, выполнение торговых запросов, графические объекты и т.п.
Переменные
Переменные в программировании имеют много общего с переменными в математике. Все мы знаем, что площадь прямоугольника можно посчитать по формуле:
S=a*b;
Где a – длина, b – ширина прямоугольника, знак звездочка означает умножение.
Формула всегда одинаковая, но разные прямоугольники имеют разные размеры, соответственно, при расчете в переменные подставляются разные значения. В программировании, переменная представляет собой участок оперативной памяти, к которому можно обращаться по имени. А в самом этом участке памяти, разумеется, хранятся какие-то данные.
В процессе работы программы этим участкам памяти могут присваиваться новые значения, а могут считываться присвоенные ранее. Участки данных, то есть переменные, могут занимать различный размер в памяти и содержать данные различного типа. С одним из типов переменных (со строковым, string) мы уже познакомились при создании скрипта. Другой тип переменных с которыми часто приходится иметь дело – целочисленные int. При объявлении переменной сначала записывается ее тип, затем имя:
int x; // объявление переменной типа int с именем x
Язык MQL5, несмотря на свое удобство для программиста, все же ориентирован на написание быстродействующих программ, поэтому в нем не происходит автоматически то, что программисту может не потребоваться. В частности, при объявлении переменной происходит только выделение участка памяти, но переменной не присваивается никакого значения.
Однако этот участок памяти мог ранее использоваться какой-то другой программой и в нем могли остаться какие-то данные. Вы должны понимать, что объявление переменой не гарантирует, что в ней будет значение 0. Поэтому, в случае необходимости, вы должны сами обеспечить себе эту гарантию – инициализировать переменную:
int x=0; // инициализация при объявлении переменной
Или позже присвоить ей значение:
x=0; // присвоение значения
Минимальное значение переменной int равно -2147483648, максимальное равно 2147483647.
Откуда берутся такие странные числа, разберем при изучении побитовых операций. Еще один целочисленный тип с которым обязательно придется иметь дело – long:
long x; // объявление переменной типа long с именем x
Минимальное значение переменной long равно -9223372036854775808, максимальное равно 9223372036854775807.
Все целочисленные типы имеют соответствующие беззнаковые аналоги: uint и ulong. Буква «u» в начале типа происходит от английского unsign (без знака). Минимальное значение uint равно 0, максимальное равно 4294967295. Минимальное значение ulong равно 0, максимальное равно 18446744073709551615.
Еще один тип с которым придется часто иметь дело, это double (вещественный тип или число с плавающей точкой):
double x; // объявление переменной типа double с именем x
В переменой double число хранится в так называемом научном формате, включающем в себя мантиссу числа и степень числа 10. Итоговое число получается как мантисса, умноженная на 10 в указанной степени. При записи числа между мантиссой и степенью ставится буква «e» или «E»:
x=12; // присвоение переменной x числа 12
x=1.2e1; // присвоение переменной x числа 12, записанного в научном формате
Мантисса представляет собой десятичную дробь с одним знаком до десятичного разделителя и точностью вплоть до 16 знаков после запятой. Максимальное значение double равно 1.7976931348623158e+308. Минимальное положительное значение равно 2.2250738585072014e- 308 (не путать с минимальным числом, которое равно максимальному числу, но с отрицательным знаком).
Еще один тип переменных, с которыми обязательно придется иметь дело, это тип bool – логический тип. Этот тип может принимать только два значения: true (истина) и false (лож).
Вообще в MQL5 существует намного большее количество типов данных, особенно целочисленных, но с ними практически не приходится иметь дело (за редким исключением), поэтому на досуге ознакомьтесь с ними самостоятельно, раздел справки: Основы языка – Типы данных.
Исследуем поведение переменных в некоторых критических случаях. Сначала наведем немного порядка в папке со скриптами. Имейте в виду, для работы с папками (для их создания, перемещения, изменения имени), а так же и с файлами, не обязательно открывать папку данных терминала и пользоваться проводником Windows, все действия можно выполнять в редакторе из навигатора, пользуясь командами контекстного меню.
В папке Scrips создайте папку «Изучение MQL5» и переместите в нее папку «MyFirstScript», затем откройте папку «Изучение MQL5» и переименуйте папку «MyFirstScript» в «001 MyFirstScript» и тут же создайте папку «002 Variables» (переменные). Таким образом, все учебные скрипты будут располагаться в одной общей папке, а скрипты соответствующие разным темам в пронумерованных подпапках, в порядке, соответствующем порядку их создания и изучения. Для того, чтобы все изменения были видны в навигаторе терминала, выполните в нем команду контекстного меню «Обновить».
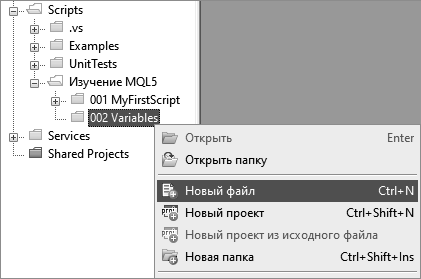
Рис. 20. Создание скрипта из навигатора через контекстное меню
Создайте скрипт с именем «Overflow» (переполнение) и сохраните его в папке «002 Variables». Для того, чтобы создаваемый скрипт сохранялся в заданной папке, создавайте его через контекстного меню навигатора. Щелкните правой кнопкой на имени папки «002 Variables» и выберите команду «Новый файл» (рис. 20).
Исследуем поведение переменной при переполнении. Присвоим переменной int максимальное значение, прибавим к ней единицу и посмотрим на результат. Язык MQL5 обеспечивает множеством средств, повышающих удобство его использования, одно из средств – предопределенные константы. Нет необходимости вводить вручную длинное число «2147483647», достаточно написать INT_MAX. Пишем код в функции OnStart():
int z=INT_MAX; z=z+1; Alert(z);
При выполнении скрипта откроется окно с сообщением «-2147483648», что соответствует минимально возможному значению переменной int. Попробуем прибавить 2. Добавим код в тот же срипт, а что бы отличать разные текстовые сообщения, пронумеруем их. В итоге в функции OnStart() должен быть такой код:
int z=INT_MAX; z=z+1; Alert("1: ",z);
z=INT_MAX;
z=z+2;
Alert("2: ",z);
В результате прибавления 2 получаем -2147483647, что логично и понятно. Теперь также начнем с минимально возможного значения переменной и будем отнимать 1 и 2. Добавляем код:
z=INT_MIN;
z=z-1;
Alert("3: ",z);
z=INT_MAX;
z=z-2;
Alert("4: ",z);
Этот код дает ожидаемый результат: 2147483647 и 2147483646 (INT_MAX и меньше IN_MAX на 1).
Обратите внимание на вызов функции Alert(). Как было изучено ранее, строки можно соединять знаком «+», но здесь используется запятая. Получается не соединение строки, а передача в функцию двух параметров – это особенность функции Alert(), а также Comment() и Print(). Всего в эти функции возможно передать 64 параметра. Использование этой особенности удобно тем, что не требует конвертирования переменных в строку. Сохраните копию скрипта с именем
«Overflow2», оставьте только первую часть кода и, а при вызове функции Alert() замените запятую на знак «+»:
int z=INT_MAX; z=z+1; Alert("1: "+z);
При компиляции этого скрипта получим предупреждение (implicit conversion from ‘number’ to ‘string’ – неявное преобразование из числа в строку). Значит, при использовании знака «+» надо самостоятельно побеспокоиться о конвертации переменной в строку. Для переменной int можно использовать функцию IntegerToString():
Alert("1: "+IntegerToString(z));
Есть еще один способ – перед переменной в круглых скобках указать тип, в который надо выполнить преобразование:
Alert("1: "+(string)z);
Впрочем, можно сделать наоборот – в скобки заключить переменную:
Alert("1: "+string(z));
Еще обратите внимание на строку с прибавление 1. Сейчас выражение записано так, как принято в математике. Но в MQL5 есть более простой способ прибавления к переменной числа или другой переменной:
z+=1;
То есть, сначала записывается имя переменной, потом указывается арифметическое действие (а данном случае «+»), затем знак «=» и прибавляемое число.
Исследуем поведение переменной double. Создайте скрипт с именем «Overflow3», в нем к максимально возможному значению переменной double (к DBL_MAX) прибавим относительно небольшое число, пусть будет 1000. Но теперь, поскольку выводимое число очень длинные (сложно проверить его визуально) выведем не результат вычисления, а результат логического выражения, сравнивающего результат вычисления с константой DBL_MAX:
double z=DBL_MAX; double x=1000; z=z+x;
bool r=(z==DBL_MAX);
Alert("1: ",r);
В итоге получаем сообщение «1: true» – прибавление 1000 никак не повлияло на значение переменной. Число 1000 слишком маленькое по сравнению с максимальным значением переменной double. Теперь прибавим число 1e292 и кроме результата сравнения выведем само значение:
z=DBL_MAX; x=1e292;
z=z+x; r=(z==DBL_MAX);
Alert("2: ",r," ",z);
Теперь получаем «2: false inf», inf – это сокращение от слова infinity (бесконечность).
Попробуем вычесть 1e292 из минимального числа (отрицательного максимального):
z=-DBL_MAX; x=1e292;
z=z-x;
r=(z==-DBL_MAX);
Alert("2: ",r," ",z);
Получаем: «2: false -inf» – отрицательную бесконечность.
Для проверки, не является ли число бесконечностью, и можно ли его использовать в расчетах, используется функция MathIsValidNumber():
Alert("3: ",MathIsValidNumber(x)," ",MathIsValidNumber(z));
Результат: «3: true false» – в переменной x валидное число, в переменной z – отрицательная бесконечность.
Переменные const
Если переменной в процессе работы программы не выполняется присвоения новых значений, а используется только одно значение, которое было присвоено ей при инициализации, то есть переменная используется как константа, то ее целесообразно объявлять с модификатором const. В этом случае обращение к переменной будет происходить немного быстрее. Пример:
const double a=1.5; const int b=2;
Если этой переменной попытаться присвоить новое значение, то при компиляции произойдет ошибка с сообщением «constant cannot be modified» (константа не может быть изменена).
Особенности переменных double
В папке «002 Variables» создайте скрипт «Normalize». Присвоим переменной результат деления числа 3 на 10:
double z=3/10;
Alert("1: ",z);
Получаем неожиданный результат: «0.0». Дело в том, что число 3 интерпретировано как целое. Теперь вместо «3» напишем «3.0»:
z=3.0/10;
Alert("2: ",z);
Получаем правильный результат: «2: 0.3».
Возьмем какое-нибудь число, например, «1.2345», выполним над ним такие действия, после которых будет очевидно, что число снова должно равняться «1.2345»:
z=1.2345;
z/=3; z/=5; z*=3; z*=5;
bool r=(z==1.2345);
Alert("3: ",r," ",z);
Получаем удивительный результат: «3: false 1.2345» – в результате вычислений получаем то же самое число, но почему-то оно не равно само себе. Вот такая странная особенность есть у переменных double. Происходит это из-за ограниченной точности переменной и существования иррациональных дробей. Но не столь важна причина, как понимание, что происходит, а главное – как с этим быть. Во-первых, функция Alert() выводит у переменных double только четыре знака после запятой. Чтобы самостоятельно регулировать точность вывода, необходимо использовать функцию DoubleToString(). Выведем 16 знаков после запятой:
Alert("4: ",r," ",DoubleToString(z,16));
Получаем такой результат: «4: false 1.2345000000000002». Теперь можно понять, почему результат вычислений не соответствует ожиданию. Решается эта проблема тем, что при использовании переменных double, а в частности при их участии в логических выражениях (при сравнении на равенство, больше, меньше и т.п.) нужно определиться с точность, с которой вы хотите выполнить это сравнение и выполнить так называемую нормализацию числа. Для этого используется функция NormalizeDouble(). Функция работает по тому же принципу, что и округление, но не до целого, а до указанного знака. Например, при нормализации числа 1.23 до одного знака получим 1.2, а при нормализации числа 1.25 – 1.3. В рассматриваемом примере у исходного числа стоит четыре знака после запятой, достаточно выполнить нормализация с такой же точностью:
z=NormalizeDouble(z,4); r=(z==1.2345);
Alert("5: ",r," ",DoubleToString(z,16));
Получаем правильный результат: «5: true 1.2345000000000000».
Функция NormalizeDouble() является довольно затратной с точки зрения времени ее выполнения, поэтому нужно стараться использовать ее только когда это действительно необходимо. Выполнять нормализацию следует непосредственно перед сравнением, а не нормализовать все промежуточные результаты (если это, конечно, не требуется в соответствие с задачей). Если есть два ненормализованных числа и нужно их сравнить (допустим, на равенство), не нужно нормализовать оба числа, необходимо вычислить разницу чисел и нормализовать ее:
double z1=1.2345678; double z2=1.2345678;
bool r1=(NormalizeDouble(z1,4)==NormalizeDouble(z2,4)); // не рекомендуется
bool r2=(NormalizeDouble(z1-z2,4)==0); // рекомендуется
В некоторых случая в нормализации нет необходимости, например, при определении положения цены относительно скользящей средней или при сравнении положения одной линии индикатора относительно другой лини индикатора или относительно уровня.
Специальные переменные
Изучим еще несколько других типов переменных. В папке «002 Variables» создайте скрипт с именем «Types». На этапе создания, в окне «Мастер MQL» нажмите на кнопку «Добавить» – в таблице «Параметры» появится переменная с именем Input1. Если щелкнуть на ячейке в столбце
«Тип» откроется довольно обширный список типов переменных, выберите тип «bool». Таким образом создайте переменные всех изученных ранее типов: bool, int, double, string. Остальные типы вряд ли когда понадобятся в окне свойств, за исключением двух: color (цвет) и datetime (дата и время) – добавьте и их. Если щелкнуть на ячейке в столбце «Начальное значение», то можно задать значение, которым переменная будет инициализироваться. Для переменной color откроется цветовая палитра, для datetime – календарь. Обратите внимания на значки перед именами переменных, они очень наглядно показывают тип переменных (рис. 21), такие же значки будут у переменных в окне свойств скрипта.
Если интересно, еще добавьте переменную типа long. Обратите внимание на значок, он такой же, как у переменной int. Установите всем переменным (кроме string) начальные значения и нажмите кнопку «OK».
Обратите внимание, как выглядят переменные в коде:
input bool Input1=false; input int Input2=0; input double Input3=0.0; input string Input4;
input color Input5=clrRed;
input datetime Input6=D'2019.06.07 20:05:14'; input long Input7=0;
Переменную string можно было инициализировать каким-нибудь значения, а хотелось бы использовать пустую строку, что невозможно сделать из окна «Мастер MQL», поэтому придется дописать инициализацию вручную:
input string Input4="";
Конечно, можно было бы оставить переменную как есть, но тут важно знать одну небольшую особенность переменной string.
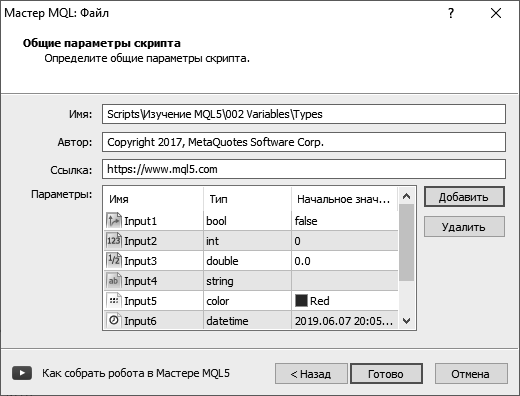
Рис. 21. Параметры в окне «Мастер MQL»
Если она не инициализирована, ее значение равно константе NULL, но константа NULL не ровна пустой строке «». Поэтому, при использовании строк, особенно, если надо будет делать проверку введенного пользователем значения, инициализируйте ее пустой строкой, иначе надо будет делать проверку переменной на равенство пустой строке и NULL.
Убедимся в этом практически. В функции OnStart() объявите строковую переменную с именем str, но не инициализируйте ее. Напишите два логически выражения с проверкой. Не обязательно для каждого выражения объявлять переменную bool, их можно написать прямо при вызове функции Alert():
string str;
Alert("1: ",str==""," ",str==NULL);
Присвоим переменной пустую строку и еще раз проверим:
str="";
Alert("2: ",str==""," ",str==NULL);
После запуска скрипта получаем такие сообщения: «1: false true» и «2: true false» – то есть пустая строка «» не равна NULL.
Переменные color и datetime по сути представляют собой целочисленные переменные long, только оснащенные некоторыми функциональными удобствами, в частности: свой значок в окне свойств, палитра, календарь, удобное представление данных при выводе. Добавим в скрипт строку выводу переменных типа color и datetime:
Alert("3: ",Input5," ",Input6);
В результате работы скрипта получаем: «3: clrRed 2019.06.07 20:05:14». Чтобы вывести числовые значения, переменные надо привести к типу long:
Alert("4: ",(long)Input5," ",(long)Input6);
В результате получаем такое сообщение: «4: 255 1559937914». 255 – это красный цвет. Вообще цвет определяется сочетанием трех компонентов RGB (Red, Green, Blue – красный, зеленый, синий), в некоторых случаях еще используется компонент Альфа – прозрачность. Компоненты меняются в диапазон от 0 до 255 (включительно). Как происходит кодирование цвета, то есть его «упаковка» в одну переменную, будет рассмотрено позже, при изучении побитовых операций. Пока разберем способы задания цвета. В строке с инициализацией переменой Input5 удалите значение clrRed и введите три буквы clr, от этого должен открыться список с цветовыми константами (рис. 22).
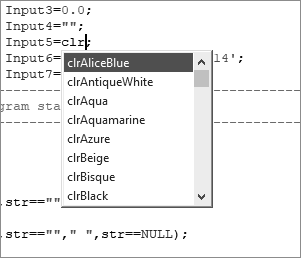
Рис. 22. Список цветовых констант
Все эти константы с образцами цветов можно найти в справочном руководстве: Константы, перечисления и структуры – Константы объектов – Набор Web-цветов.
Числовое значение времени представляет собой количество секунд от 1-го января 1970-го года. Добавьте в скрипт строки:
datetime time=0;
Alert("5: ",time);
Получается такой результат: «5: 1970.01.01 00:00:00».
Максимальное значение времени, которое может храниться в переменной datetime – 31 декабря
3000 года.
В стуках 86400 секунд, если прибавить это число к переменной, получится следующий день:
time+=86400;
Alert("6: ",time);
Результат: «1970.01.02 00:00:00».
Если для какой-то заданной даты необходимо получить дату завтрашнего, послезавтрашнего или вчерашнего дня, удобно выполнять прибавление или вычитание заданного отрезка времени. Но если надо присвоить переменной заданную дату, использование числа неудобно. Обратите внимание, как выполняется инициализация переменной в скрипте: D’2019.06.07 20:05:14′ – сначала ставится буква «D», затем, в одинарных кавычках записывается дата: год из четырех знаков, месяц (от 1 до 12), день месяца (от 1 до 31), пробел и время: часы, минуты, секунды через двоеточие. Секунд не обязательно указывать, можно и вообще время не указывать, тогда это будет время начала суток «00:00». Если значение месяца, дня, часа, минут, секунд меньше 10-ти, ноль вначале можно не писать: D’2019.6.07 20:5:14′.
Вообще работа со временем является довольно обширной и сложной, в дальнейшем подойдем к ней более основательно.
Примерно так же, как и дату, можно задавать цвет: сначала ставится буква «C», затем, в одинарных кавычках значение компонентов RGB через запятую:
input color Input5=C'0,255,0';
Это очень удобный и наглядный способ, тем не менее, для значений по умолчанию рекомендуется использовать константы Web-цветов, в этом случае указанный в переменной цвет будет находиться на цветовой палитре.
Перечисления
Иногда, при установке параметров в окне свойств, бывает необходимо ограничить количество вариантов у какой-нибудь переменной и, при этом сделать выбор более наглядным, то есть дать вариантам выбора понятное имя. Для решения этой задачи используется перечисление. Описание перечисления начинается со слова «enum», затем следует его имя, и между фигурными скобками через запятую перечисляются варианты. В папке «Variables» создайте скрипт с именем
«Enumeration» с одной внешней переменной любого типа (чтобы вручную не задавать свойство script_show_inputs).
Перед внешней переменной опишем перечисление с именем EMyFirstEnum:
enum EMyFirstEnum{ Variant_1=1, Variant_2=2
};
Обратите внимание, после закрывающей фигурной скобки обязательно нужна точка с запятой.
В скрипте должна быть одна внешняя переменная, замените ее тип на только что созданное перечисление:
input EMyFirstEnum Input1;
Для инициализации переменной теперь можно использовать как числовое значение, в данном случае 1 или 2, так и имя варианта – Variant_1 или Variant_2:
input EMyFirstEnum Input1=Variant_1;
Теперь в окне свойств, при попытке установки значения для переменной Input1, будет открываться выпадающий список (рис. 23).
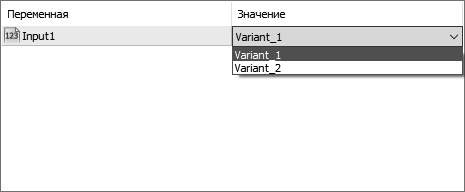
Рис. 23. Перечисление в окне свойств
Так же и в коде, вместо числового значения 1 или 2, можно использовать имя варианта:
if(Input1==Variant_1){ Alert("Выбран вариант 1");
}
else{
Alert("Выбран вариант 2");
}
При использовании перечислений иногда бывает полезна функция EnumToString(). Эта функция преобразует значение из перечисление в его имя, которое потом можно использовать в текстовых сообщениях:
Alert("Выбран вариант: ",EnumToString(Input1));
При описании перечисления не обязательно указывать значения вариантов, в этом случае им автоматически присвоятся значения от ноля:
enum EMyEnum{ var_1, var_2
};
В этом примере вариант var_1 имеет значение 0, а вариант var_2 – 1.
При использовании перечислений настоятельно рекомендуется использовать в коде имена вариантов, но не числовые значения. Дело в том, что когда-нибудь может потребовать добавить в перечисление еще один вариант, но помесить его не в самый конец, а в середину, в этом случае числовые значения вариантов, следующих за новым, сдвинутся.
В языке MQL5 имеется огромное количество различных перечислений. Очень часто придется использовать следующие: ENUM_MA_METHOD (тип скользящей средней), ENUM_APPLIED_PRICE – тип цены (open, close и т.п.), ENUM_APPLIED_VOLUME – объем (реальный или тиковый), ENUM_TIMEFRAMES – выбор таймфрейма. Параметры этих типов можно добавить в окно свойств:
input ENUM_MA_METHOD method=MODE_EMA;
input ENUM_APPLIED_PRICE price=PRICE_CLOSE; input ENUM_APPLIED_VOLUME volume=VOLUME_TICK; input ENUM_TIMEFRAMES timeframe=PERIOD_CURRENT;
Внешние параметры и комментарий
Однострочное комментирование внешних параметров и перечислений имеет свои особенности. Кому-то эти особенности покажутся очень удобными, кому-то наоборот. Комментарий внешнего параметра заменяет собой имя переменной в окне свойств. Сделайте копию скрипта «Types» с именем «Types2», для каждой переменной сделайте комментарий:
input bool Input1=false; // Логическая переменная
input int Input2=0; // Целое число
input double Input3=0.0; // Вещественное число
input string Input4=""; // Строка
input color Input5=C'0,255,0'; // Цвет
input datetime Input6=D'2019.06.07 20:05:14'; // Дата
input long Input7=0; // Длинное целое
Теперь в окне свойств вместо имен переменных отображаются комментарии (рис. 24).
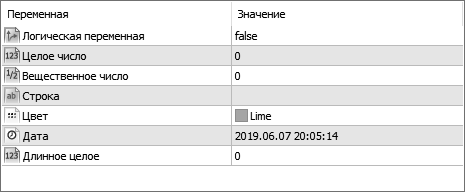
Рис. 24. Комментарии вместо имен переменных
Если кому-то такая особенность не кажется удобной, например, если комментарий является инструкцией по переменной, есть два варианта. Можно перенести комментарий на следующую строку:
input bool Input1=false;
// Пример логической переменной
Второй вариант – перед однострочным комментарием с инструкцией по переменной использовать имя переменной, заключенное в знаки многострочного комментария:
input bool Input1=false; /*Input1*/ // Пример логической переменной
В этом случае, в окне свойств отобразится имя, отделенное знаками многострочного комментария. Недостатком этого метода является то, что при изменении имени переменной, а иногда это бывает, нужно не забыть изменить имя и в комментарии.
Сделайте копию скрипта «Enumeration» с именем «Enumeration2» и добавьте вариантам перечисления однострочные комментарии:
enum EMyFirstEnum{ Variant_1=1, // Вариант-1 Variant_2=2 // Вариант-2
};
Теперь в выпадающем списке имена вариантов будут заменены соответствующими комментариями (рис. 25).
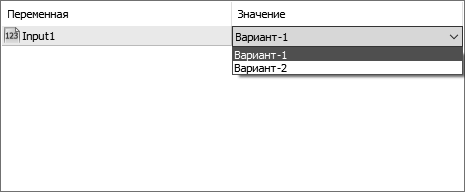
Рис. 25. Перечисление с комментариями в окне свойств
Здесь также, чтобы комментарии не заменяли имена вариантов, их следует перенести на следующие строки:
enum EMyFirstEnum{ Variant_1=1,
// Вариант-1 Variant_2=2
// Вариант-2
};
Арифметика
В папке «Изучение MQL5» создайте папку «003 Math», а в ней скрипт «Аrithmetic», следующие учебные примеры будем писать в нем. Скорее всего, вы уже знаете как программируются все четыре арифметических действия, тем не менее, повторим. Сложение выполняется знаком «+», вычитание выполняется знаком «-», умножение выполняется знаком «*», деление выполняется знаком «/»:
double a=1.5; double b=2.5;
double c=a+b; // сложение double d=a-b; // вычитание double e=a*b; // умножение double f=a/b; // деление
Alert("1: c=",c,", d=",d,", e=",e,", f=",f);
Результат: «1: c=4.0, d=-1.0, e=3.75, f=0.6».
Часто бывает нужно произвести какое-то арифметическое действие с переменой и присвоить результат этой же переменной. Можно произвести вычисления явно:
c=c+a; // сложение d=d-a; // вычитание e=e*a; // умножение
f=f/a; // деление
Alert("2: c=",c,", d=",d,", e=",e,", f=",f);
Результат: «2: c=5.5, d=-2.5, e=5.625, f=0.4».
А можно использовать укороченную запись (совмещение арифметического действия с присваиванием):
c-=a; // вычитание d+=a; // сложение e/=a; // деление f*=a; // умножение
Alert("3: c=",c,", d=",d,", e=",e,", f=",f);
Результат: «3: c=4.0, d=-1.0, e=3.75, f=0.6».
В выражениях могут использоваться не только переменные, но и числовые константы:
double g=2.0*a;
Alert("4: g=",g);
Результат: «4:g=3.0».
Константы не рекомендуется записывать непосредственно числом, лучше объявить переменную, чтобы в дальнейшем иметь возможность быстрой замены значения без необходимости искать в коде нужное место. Для многих известных математических постоянных в языке MQL5 есть предопределенные константы: M_PI – число Пи, M_PI_2 – Пи/2, M_1_PI – 1/Пи, M_E – число e и др. Все константы можно посмотреть в справке: Константы, перечисления и структуры – Именованные константы – Математические константы.
Иногда в одном выражении могут участвовать переменные int и double. В этом случае все переменные автоматически приводятся к типу double, то есть расчет выполняется верно, в отличие от некоторых других языков, в которых на каком-то этапе вычисления может произойти отбрасывание дробной части и получение неверного результата.
int h=3; double i=h*a;
Alert("5: ",i);
Результат: «5: 4.5».
Если же результат присваивается переменной int, происходит отбрасывание дробной части итогового результата, а при компиляции компилятор дает предупреждение «possible loss of data due to type conversion» – возможна потеря данных при конвертации:
int j=h*a;
Alert("6: ",j);
Для устранения предупреждения надо выполнить приведение типа:
int j=int(h*a);
Alert("6: ",j);
Результат: «6: 4» – значит, 3 было умножено на 1.5, получено 4.5, но дробный остаток был отброшен.
В случае необходимости использования в формулах переменны разных типов, уделяйте дополнительное внимание проверке правильности расчетов по этой формуле. Для этого можно вынести формулу в отдельный скрипт и проверить ее там с различными критическими значениями параметров.
Очень серьезно нужно относиться применению действия деления. Дело в том, как известно еще из школьно математики, делить на ноль нельзя. Если же деление на ноль происходит в эксперте или индикаторе, возможна остановка его работы, а это очень серьезная проблема. Поэтому при применении деления надо проводить внимательный анализ, возможно ли в данной ситуации деление на 0 и принимать соответствующие меры. А еще лучше – принимать меры даже без анализа, чтобы и намека на сомнения не оставалось.
Перед вычислением формулы надо проверить знаменатель на равенство нулю, и если он равен нулю, то вместо вычисления надо присвоить переменной для результата какое-то логически обоснованное значение или же вообще не выполнять вычислений. Например, при вычислении по формуле y=1/x, в случае, если x=0, переменой y следует присвоить значение DBL_MAX. С математической точки зрения это не совсем верное решение, потому что при приближении к нулю с отрицательной стороны необходим результат -DBL_MAX, но все же это способ обеспечить бесперебойную работу программы. Практический пример решения данной проблемы будет позже в разделе про функции.
В программировании существует еще одно действие, относящееся к арифметическим, – получения остатка от деления, оно выполняется знаком «%». Данное действие выполняется только над целочисленными переменными:
int k=8; int l=3; int m=k%l;
Alert("7: ",m);
Действие с присваиванием:
k%=l;
Alert("8: ",k);
Результаты: «7: 2», «8: 2».
Инкремент и декремент
Инкрементация, это увеличение значения переменной на 1, декрементация – уменьшение на 1. Обычно инкрементацию и декрементацию применяют к целочисленным переменным, но ничто не мешает применять ее и к переменным типа double. Это очень частая операция при программировании, поэтому существуют простые и удобные средства ее выполнения.
В папке «003 Math» создайте скрипт для экспериментов с именем «Increment». В начале функции OnStart() объявите две переменных типа int с имнами i и j, инициализируйте их значениями 0. Объявление переменных одного типа можно делать в строку, даже вместе с инициализацией:
int i=0,j=0;
Инкрементация выполняется двумя знаками сложения «++»:
i++;
Alert("1: ",i);
Результат: «1: 1».
Декрементация выполняется двумя знаками вычитания «—»:
i--;
Alert("2: ",i);
Результат: «1: 0».
Знаки инкрементации и декрементации могут использоваться в формулах, в этом случае знаки инкрементации/декрементации могут стоять как после переменной, так и после. Если знаки стоят после переменой, то сначала выполняется вычисление по формуле, а потом выполняется инкрементация/декрементация:
i=1; j=2;
int k=i+(j++);
Alert("3: i=",i,", j=",j,", k=",k);
Результат: «3: i=1, j=3, k=3» – k=3, то есть это сумма начальных значений переменных i и j, но j
равно 3, то есть ее увеличение выполнено после вычисления суммы i и j.
Если знаки стоят перед переменной, то сначала выполняется инкрементация/декрементация, а затем выполняются вычисления по формуле с новыми значениями.
i=1; j=2;
k=i+(++j);
Alert("4: i=",i,", j=",j,", k=",k);
Результат: «4: i=1, j=3, k=4» – теперь k=3, то есть сначала переменная j была увеличена на 1, потом произведено сложение.
Что интересно, выражение можно записать без круглых скобок:
i=1; j=2;
k=i+++j;
Alert("5: i=",i,", j=",j,", k=",k);
Результат: «5: i=2, j=2, k=3». Как видим, сначала проведена конкатенация переменной i, потом выполнено сложение. Однако практически не стоит писать такой не очевидно понятный код.
Математика
В языке MQL5 существует огромное количество математических функций. Все они начинаются с префикса «Math», стоит только набрать три первых буквы, как тут же открывается список всех математических функций (рис. 26).
Большинство из них вам должно быть знакомо еще со школьного курса математики: MathSin() – синус, MathArctan() – арктангенс и пр. Их не будем рассматривать. Но рассмотрим те функции, которые, скорее всего, вам придется использовать, а если когда возникнет необходимость в использовании других функции, можно воспользоваться справкой для их изучения.
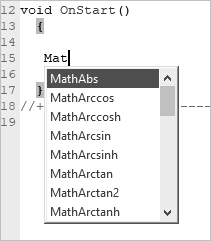
Рис. 26. Список математических функций
Для экспериментов с функциями в папке «003 Math» создайте скрипт с именем «Mathematics». В начале функции OnStart() объявим несколько переменных, к которым будем применять математические функции:
double a=2.1; double b=2.9; double c=3; double d=16; double e=-16;
Рассмотрим следующие функции:
MathMax() – выбор наибольшего из двух вариантов:
Alert("1: ",MathMax(a,b));
Результат: «1: 2.9».
MathMin() – выбор наименьшего из двух вариантов:
Alert("2: ",MathMin(a,b));
Результат: «2: 2.1».
MathPow() – возведение числа в степень:
Alert("3: ",MathPow(a,2));
Результат: «6: 4».
MathSqrt() – извлечение квадратного корня:
Alert("4: ",MathSqrt(d));
Результат: «4: 4.0».
MathRound() – округление:
Alert("5: ",MathRound(a)," ",MathRound(b));
Результат: «5: 2.0 3.0».
MathCeil() – округление в большую сторону. Если число целое, оно не меняется, а любое дробное округляется в большую сторону, например 1.1 преобразуется в 2:
Alert("6: ",MathCeil(a)," ",MathCeil(b));
Результат: «6: 3.0 3.0».
MathFloor() – округление в меньшую сторону. Если число целое, оно не меняется, а любое дробное округляется в меньшую сторону, например 1.9 преобразуется в 1:
Alert("7: ",MathFloor(a)," ",MathFloor(b));
Результат: «7: 2.0 2.0».
MathAbs() – модуль числа. Положительное число не меняется, отрицательное становится положительным:
Alert("8: ",MathAbs(d)," ",MathFloor(e));
Результат: «8: 16.0 16.0».
Случайное число
Для получения случайного числа используется функция MathRand(). В папке «003 Math» создайте скрипт для экспериментов с именем «Random». В начало функции OnStart() добавьте код:
Alert("1: ",MathRand());
Запустите скрипт подряд несколько раз, при каждом запуске будет разный результат. Иногда бывает нужно обеспечить одну и ту же последовательность случайных чисел при каждом запуске программы, для этого используется функция MathSrand() в которую передается параметр – указывается число для инициализации начального положения генератора случайных чисел. Тип параметра uint, то есть можно указать число от 0 до UINT_MAX. Добавим вызов функции MathSrand(), а после нее вызовем MathRand() несколько раз:
MathSrand(25);
Alert("2: ",MathRand()," ",MathRand()," ",MathRand());
Теперь результат 1 будет меняться, как и раньше, а результат 2 будет одним и тем же при каждом запуске скрипта: «2: 9090 14285 120».
Иногда бывает нужно, чтобы функция MathStrand() при каждом запуске программы вызывалась с разным инициирующим параметром, для этого можно использовать значение текущего времени в терминале – TimeCurrent() или время компьютера – TimeLocal():
MathSrand(TimeCurrent());
Имейте в виду, время TimeCurrent() – это последнее известное время изменения котировок, то есть в выходные дни оно не будет меняться.
Минимальное значение случайного числа, генерируемого функцией MathRand() – 0, максимальное — 32767. Если нужно получить случайное число от 0 до 1, надо число, полученное от функции
MathRand(), поделить на 32768:
double rnd=;
Alert("3: ",rnd);
Полученное таким образом число будет располагаться в диапазоне от 0 до 1, но никогда не будет
равно 1. Именно такой генератор случайных чисел бывает нужен на практике, на его основе можно легко получить генерацию случайных числе в любом другом диапазоне. Допустим, требуется получить случайное целое число от 3 до 7 (включительно). Для этого надо получить случайное число от 0 до 4 (включительно). Чтобы получить такое число, нужно случайное число в диапазоне от 0 до 1 (полученное ранее) умножить на 5 и отделить целую часть, потом прибавить 3.
int mn=3; int mx=7;
int rnd2=mn+(int)MathFloor((MathRand()/32768.0)*(mx-mn+1)); Alert("4: ",rnd2);
Данный метод имеет свои недостатки – некоторую неравномерность распределения вариантов,
однако он прост, быстр и вполне может использоваться для задач какой-либо инициализации случайными данными.
Есть и еще более простой способ получения целого случайного числа в заданном диапазоне – через остаток от деления случайного числа. Например, надо получить случайное число 0 или 1, то есть 2 варианта. Для этого берем остаток от деления на 2:
Alert("5: ",MathRand()%2);
Если нужно число от 0 до 2 (три варианта), берем остаток от 3:
Alert("6: ",MathRand()%3);
Но 32768 не делится на 3 без остатка, значит, распределение вариантов будет иметь небольшую погрешность.
Логические выражения
Логические выражения чем-то подобны арифметическим, только результатом их вычисления является не число, а одно из двух состояний: true (истина) или false (лож). Для результатов вычисления логического выражения используется переменная типа bool. Простейшее логическое выражение, это проверка двух чисел, равны ли они, не равны, одно больше другого или меньше другого и т.п. В логических выражениях могут использоваться следующие операции сравнения:
«==» – равенство, «!=» – неравенство, «<» – меньше, «>» – больше, «<=» – меньше или равно, «>=» – больше или равно.
В папке «003 Math» создайте скрипт с именем «Boolean», в начале функции OnStart() объявите две переменных типа int:
int a=3; int b=4;
Затем запишите все выражения с операторами сравнения:
bool exp01=(a==b); bool exp02=(a!=b); bool exp03=(a>b); bool exp04=(a<b); bool exp05=(a>=b); bool exp06=(a<=b);
Вывод результатов:
Alert("a=",a,", b=",b,"; ",exp01," ",exp02," ",exp03," ",exp04," ",exp05," ",exp06);
Параметры a и b можно менять прямо в коде, выполнять компиляцию и смотреть на результаты в окне сообщений. Вот несколько результатов:
- a=3, b=4; false true false true false true;
- a=4, b=3; false true true false true false;
- a=3, b=3; true false false false true true.
В примере выше выражения со сравнением заключены в круглые скобки, но эти скобки не обязательны. В любом случае сначала будет выполнено сравнение, а потом присвоение результата этого сравнения переменной, то есть операции сравнения имеют более высокий приоритет, чем операция присваивания. Однако использование скобок делает код более легким для понимания, поэтому рекомендуется.
На практике логические выражения могут быть значительно сложнее, чем простое сравнение. К результатам сравнений могут применяться операторы, которые уже непосредственно называются логическими: «!» – отрицание, «&&» – логическое «и», «||» – логическое «или». Оператор «!» инвертирует результат – true превращает в false, а false в true. В папке «003 Math» создайте скрипт с именем «Boolean2», дальнейшие эксперименты будем проводить в нем:
bool a,b; a=true; b=!a;
Alert("1: a=",a,", b=",b);
a=false; b=!a;
Alert("2: a=",a,", b=",b);
Результаты: «1: a=true, b=false», « 2: a=false, b=true».
Оператор «&&» соединяет два логических выражения, итоговое выражение будет истинным, если истины оба выражения:
a=true; b=false;
bool c=(a&&b);
Alert("3: a=",a,", b=",b,"; ",c);
Результаты: «3: a=true, b=false; false», «3: a=false, b=true; false», «3: a=false, b=false; false», «3: a=true, b=true; true».
Разумеется, может использоваться несколько операторов «&&»:
bool d=(a&&b&&c);
Оператор «||» тоже соединяет два логических выражения, итоговое выражение будет истинным, если истинно хотя бы одно выражение:
a=true; b=false; c=(a||b);
Alert("4: a=",a,", b=",b,"; ",c);
Результаты: «4: a=true, b=false; true», «4: a=false, b=true; true», «4: a=false, b=false; false», «4: a=true, b=true; true».
Конечно, выражение может включать в себя и оператор «&&» и оператор «||». Оператор «&&» имеет приоритет, то есть сначала выполняется «&&», затем «||». Тем не менее, рекомендуется использовать круглые скобки, что бы приоритет операций был явно определен:
a=true; b=true; c=false;
bool d=((a&&b)||c);
Alert("4: a=",a,", b=",b,", c=",c,"; ",d);
К тому же, при отсутствие скобок, компилятор дает предупреждение «check operator precedence for possible error; use parentheses to clarify precedence» – проверьте приоритет операций, используйте скобки для указания приоритета.
Кроме логических операторов и операторов сравнения, логические выражения могут включать и арифметические действия, в итоге может получиться довольно сильно растянутое выражение, которое от этого становится сложным для прочтения:
int z=2; int x=5; int s=7;
bool e=((z>x && z-x>s) || (z<x && x-z>s) || (z==s && z==s));
Написать такой код не сложно, но спустя некоторое время он может оказаться, что он сложен для понимания. Рекомендуется разбивать такие выражения на несколько более простых:
bool exp1=(z>x && z-x>s); bool exp2=(z<x && x-z>s); bool exp3=(z==s && z==s); e=(exp1 || exp2 || exp3);
Так же и арифметические выражения могут включать в себя логические выражения при помощи условного оператора «?:». В таком операторе перед знаком «?» стоит логическое выражение, если оно истинно, используется значение, стоящее перед знаком «:», иначе используется значение, стоящее после знака «:»:
a=true; int v1=1; int v2=2;
int val=(a?v1:v2); Alert("6: a=",a,"; ",val);
Результаты: «6: a=true; 1», «6: a=false; 2».
Данный оператор может работать с любым типом данных, в том числе со строками:
string sval=(a?"Строка-1":"Строка-2");
Alert("7: a=",a,"; ",sval);
Результат: «Строка-1».
Условные операторы
За счет условных операторов обеспечивается выполнение различных участков кода в зависимости от различных условий (результатов вычисления логических выражений). Наиболее часто используемый условным оператором является оператор «if». Раньше мы уже частично ознакомились с ним. Осталось добавить, что оператор может быть дополнен ответвлением «else» (в переводе с английского «иначе»). Создайте папку «004 Conditional», а в ней скрипт с именем
«if». Конструкция if без else:
bool a=true;
if(a){
Alert("1: if");
}
Конструкция if c else:
if(a){
Alert("2: if");
}
else{
Alert("2: else");
}
Ответвление else может в свою очередь иметь дополнительную проверку условия if. Допустим, имеется какое-то значение и три уровня, если значение выше верхнего уровня, то выполняется один участок кода. Если выше среднего, но не выше верхнего, то выполняется второй участок кода, если значение выше нижнего уровня, но не выше других уровней, то выполняется третий участок кода. А если значение не превышает даже нижний уровень, то выполняется четвертый участок кода:
double val=35.0; if(val>75){
Alert("3 >75");
}
else if(val>50){ Alert("3 >50");
}
else if(val>25){ Alert("3 >25");
}
else{
Alert("3 уровни не достигнуты");
}
Условный оператор if может использоваться и со сложными логическими выражениями.
Оператор switch (переводится с английского как «переключатель») используется, если нужно выполнять различный код в зависимости от значения целочисленной переменной. Для экспериментов с этим оператором создайте скрипт с именем «switch». После оператора switch в круглых скобках указывается имя переменной, по значению которой будет выполняться переключение, затем, между фигурных скобок записываются операторы case со значением варианта (каждый case на своей строке), в конец строки ставится двоеточие. В конце кода каждого варианта должен стоять оператор break:
int a=1; switch(a){
case 1:
Alert("1: 1"); break;
case 2:
Alert("1: 2"); break;
case 3:
Alert("1: 3"); break;
}
Порядок расположения вариантов никак не связан с их значениями. Следующий код будет работать точно так же, как предыдущий:
a=1;
switch(a){
case 2:
Alert("1: 2"); break;
case 1:
Alert("1: 1"); break;
case 3:
Alert("1: 3"); break;
}
Кроме варианта «case» может использоваться вариант «default», этот вариант будет выполняться во всех случаях, для которых не определен вариант case:
a=5;
switch(a){
case 1:
Alert("2: 1"); break;
case 2:
Alert("2: 2"); break;
case 3:
Alert("2: 3"); break;
default:
Alert("3: default");
}
Если для какого-то case в конце не написать break, то при попадании в этот case будет выполняться код своего case и всех последующих, пока не встретится break:
a=2;
switch(a){
case 1:
Alert("3: 1"); break;
case 2:
Alert("3: 2");
case 3:
Alert("3: 3"); break;
}
При выполнении этого кода будет выведено два сообщения: «3: 2» и «3: 3».
Циклы
Операторы цикла используются для повторного выполнения одного и того же участок кода несколько раз. Всего существует три способа организации циклов, то есть три оператора: for, while и do while. Наиболее универсальный и чаще используемый – for. После оператора for в круглых скобках записывается три выражения, определяющих параметры цикла. Друг от друга выражения
отделяются точкой с запятой. Первое выражение – объявление и инициализация счетчика циклов. Второе выражение – проверка условия завершения цикла. Третье выражение выполняется после каждого цикла, в нем обычно выполняется изменения значения счетчика. Наиболее часто используется следующая конструкция:
for(int i=0;i<3;i++){
// повторяемый код
}
В данном примере повторяемый код будет выполняться три раза. Сначала переменная i имеет значение 0, после каждого цикла она увеличивается на 1, все это повторяется пока значение i меньше, чем 3. Таким образом, цикл повторятся 3 раза, на первом проходе I равно 0, затем 1 и на последнем – 2.
Создайте папку «005 Cycles», а в ней скрипт «for». В функцию OnStart() добавьте код:
Alert("=== Начало цикла 1 ==="); for(int i=0;i<3;i++){
Alert(i);
}
В результате работы кода откроется окно с сообщениями 0, 1, 2 (рис. 27).
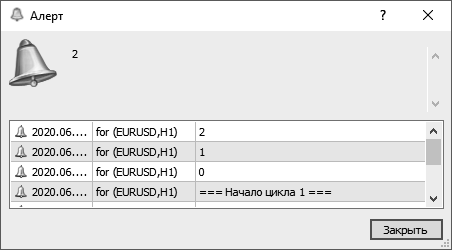
Рис. 27. Результат работы цикла for
Цикл for открывает широкое поле для творчества, существует огромное количество вариантов его использования. Переменная для счетчика может быть объявлена перед циклом:
int i; for(i=0;i<3;i++){
// повторяемый код
}
Также пред циклом может быть и объявление и инициализация, при этом место для инициализирующего выражения остается пустым:
int i=0; for(;i<3;i++){
// повторяемый код
}
Может использоваться два счетчика (например, один из них увеличивается, другой уменьшается):
Alert("=== Начало цикла 2 ==="); for(int i=0,j=2;i<3;i++,j--){
Alert(i," ",j);
}
В результате работы этого кода откроется окно с сообщениями 0 2, 1 1, 2 0.
Также и выражение с проверкой условий завершения цикла может быть более сложным. Воспользуемся функция MathRand() для получения случайных чисел и будем повторять цикл, пока не насчитаем не менее трех четных чисел и не мене трех нечетных:
int i,j;
for(i=0,j=0;i<3 || j<3;){ if(MathRand()%2==0){
i++;
}
else{
j++;
}
}
Alert(«3: i=»,i,», j=»,j);
Заметьте, теперь остается пустым место для третьего выражения. Также можно оставить пустым второе выражение, а проверку на необходимость выхода проводить внутри цикла. Для выхода из цикла используется оператор break:
for(i=0,j=0;i<3 || j<3;){ if(MathRand()%2==0){
i++;
}
else{
j++;
}
if(i>=3 && j>=3){ break;
}
}
Alert("4: i=",i,", j=",j);
Кроме оператора break внутри цикла может использоваться оператор continue. Оператор break указывает на необходимо прервать выполнение цикла и выйти из него, а оператор continue указывает на необходимость прервать выполнение цикла и перейти к следующему повторению (итерации) цикла. В следующем примере выполняется 10 повторений цикл с изменением i от 0. Если i делится на 3 без остатка, итерация пропускается, в остальных случаях значение i выводится в окно сообщений:
Alert("=== Начало цикла 5 ==="); for(i=0;i<10;i++){
if(i%3==0){
continue;
}
Alert("5: ",i);
}
Результат: 1, 2, 4, 5, 7, 8. Числа 0 в ряду нет, оно делится на все числа без остатка.
Пока что во всех примерах счетчик итераций увеличивался на 1, но можно увеличивать его на любое число. В следующем примере показан цикл с шагом 3.
Alert("=== Начало цикла 6 ==="); for(i=0;i<10;i+=3){
Alert("6: ",i);
}
Результат: 0, 3, 6, 9.
При помощи оператора for можно создать бесконечный цикл. Создадим его в отдельном скрипте с именем «for_endless». Можно написать так:
for(;true;){
// какой-то код
}
Однако при выполнении скрипта с таким кодом терминал практически зависнет, его будет очень сложно отсоединить от графика и будет большая нагрузка на процессор. Во-первых, необходимо обеспечить возможность реакции терминала на различные действия пользователя, это осуществляется использованием функции Sleep() – в переводе с английского «пауза», в эту функцию передается параметр, указывающий длительность паузы в миллисекундах, а за эту паузу терминал и операционная система обеспечивают работу других процессов. При таком подходе зацикленный скрипт не будет создавать никаких сложностей для пользователя. Кроме того необходимо обеспечить возможность легкого отсоединения скрипта от графика, в этом поможет функция IsStopped() – эта функция равна true в тот момент, когда пользователь пытается отсоединить скрипт от графика. А чтобы узнать, что скрипт что-то делает, выведем на график текущее время терминала и компьютера. Получаем такой код:
for(;!IsStopped();){ Comment(TimeCurrent()," ",TimeLocal()); Sleep(1);
}
Comment("");
Последняя строка кода – вызов функции Comment() с пустой строкой нужен для очистки комментария на графике. После запуска скрипта в левом верхнем углу графика появится строка со временем и датой. Для отсоединения скрипта от графика, надо щелкнуть правой кнопкой мыши на названии скрипта в правом верхнем углу графика и выбрать команду «Удалить» (рис. 28).
В цикле while используется одно выражением, определяющим необходимость выполнения очередной итерации цикла. Слово while в переводе с английского означает «пока», то есть, до тех пор, пока выполняются указанные условия, циклы повторяются. Для экспериментов с циклом while создайте скрипт с именем «while». Наиболее часто используется примерно следующая конструкция:
int i=0; while(i<5){
// Alert(i); i++;
}
Как видим, принцип организации цикла такой же, как c оператором for: предварительная инициализация счетчика, но выполняемая отдельно от цикла, проверка условий повторения цикла
и увеличение счетчика, которое может быть выполнено в произвольном месте цикла. Впрочем, в цикле for тоже ничто не мешает менять значение счетчика в любом месте кода.
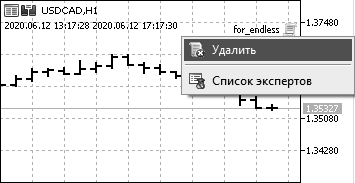
Рис. 28. Удаление скрипта с графика
Оператор while наилучшим образом подходит для организации бесконечного цикла. Код бесконечного цикла напишем в файле «while_endless», только теперь вместо времени выведем результат функции GetTickCount() – функция показывает количество миллисекунд, прошедших от начала запуска скрипта, ее удобно использовать в качестве индикатора того, что скрипт работает:
while(!IsStopped()){ Comment(GetTickCount());
}
Comment("");
Цикл do while отличается от цикла while только тем, что проверка условия повторения цикла выполняется не в начале, а в конце, то есть даже если условия изначально ложны, то все равно будет выполнено хотя бы одно повторение цикла. Пример с циклом do while будем писать в скрипте «do_while»:
int i=5; do{
Alert(i);
}while(i<5);
В результате работы скрипта откроется окно с одним сообщением «5». Если же инициализировать счетчик i значением 0, откроются следующие сообщения: 0, 1, 2, 3, 4. То есть прохода цикла при i равном 5 в этом случае не будет.
Так же как в цикле for, в циклах while и do while могут использоваться операторы break и continue.
Важно знать одну особенность вычисления логических выражений в операторах if, for, while и do while. Они вычисляются не полностью, а только до тех пор, пока результат не станет очевидным. Пример:
int a=1,b=2; if(a>1 && b>5){
//...
}
Первое выражение «a>1» ложно, так что уже понятно, что итоговое выражение никогда не будет истинным, поэтому проверка прерывается, и выражение «b>6» не вычисляется. Так же и с выражением «или»:
if(a==1 || b==5){
//...
}
Первое выражение «a==1» истинно, этого достаточно для проверки, поэтому следующее выражение «b==5» не вычисляется.
Несмотря на то, что предварительное и раздельное вычисления выражений делает код более понятным, знание особенностей выполнения их вычислений позволит писать более быстрый и рациональный код.
Массивы
Массивы, это нумерованные переменные, то есть это набор нескольких переменных одного типа, обращение к которым выполняется посредством указания имени массива и индекса элемента. Чтобы начать пользоваться массивом, его, так же как переменную, нужно объявить. При объявлении массива можно сразу указать его размер:
int a[10];
Скрипты с примерами использования массивов располагаются в папке «006 Arrays».
Вышеприведенная строка кода и последующие примеры располагаются в скрипте «Arrays».
В процессе работы программы размер массива a нельзя изменить, поэтому такой массив называется статическим. Если при объявлении не указать размер массива, то такой массив называется динамическим, в дальнейшем можно произвольно менять его размер при помощи функции ArrayResize():
int b[];
ArrayResize(b,10);
При объявлении массива его можно сразу инициализировать, в этом случае нет необходимости указывать размер массива, он будет определен инициализирующими данными:
int c[]={2,17,9};
Такой массив будет статическим. Динамический массив может быть инициализирован функцией ArrayInitialize(), но только одинаковыми значениями. Эта функция может быть применена и к статическим массивам.
ArrayInitialize(b,0);
ArrayInitialize(a,0);
Обратите внимание на всплывающую подсказку по параметрам этой функции (рис. 29). Заметьте, в левой части подсказки текст «[1 of 8]», в переводе с английского это означает «1-я из 8-и», то есть всего существует 8 вариантов этой функции с одним и тем же именем. Имена функций одинаковые, а отличаются они только типом параметров, такие функции называются перегруженными.

Рис. 29. Подсказка по параметрам перегруженной функции
Нажмите на клавиатуре клавишу со стрелкой вниз или вверх и подсказка изменится. Для данной функции от просмотра различных вариантов подсказки нет особой пользы, все варианты функции отличаются только типом передаваемого в нее массива. Но бывают перегруженные функции с очень сильно отличающимися наборами параметров, в этих случаях просмотр подсказок очень пригодится.
Очень часто бывает нужно узнать размер массива, для этого используется функция ArraySize():
int s=ArraySize(c);
Далее этот размер можно использовать для обхода массива в цикле:
for(int i=0;i<s;i++){ Alert(i);
}
Рекомендуется использовать переменную для размера массива, а не вызывать функцию размера непосредственно в цикле, так цикл будет работать немного быстрее, потому что вызов функции происходит на каждой итерации. Впрочем, это спорное утверждение, поскольку современные компиляторы выполняют очень серьезную оптимизацию кода при компиляции, и возможно, что в данном случае вызов функции будет работать так же быстро, как вызов переменной. Так что рекомендацию использовать переменную, можно считать исторически сложившейся привычкой.
Так же можно проходить цикл в обратном порядке. В этом случае функция размера вызывается только один раз:
for(int i=ArraySize(c)-1;i>=0;i--){ Alert(i);
}
При изучении массивов, а также в дальнейшем, при отладке кода, очень полезной может оказаться функция ArrayPrint(). В функцию кроме массива можно предать большое количество дополнительных параметров, но практически в этом не бывает необходимости, достаточно передать только массив:
ArrayPrint(c);
Вывод эта функция выполняет в окно «Инструменты» во вкладку «Эксперты», весь массив выводится одной строкой, то есть при работе с большими массивами не стоит использовать эту функцию. В данном случае будет выведена такая строка: «2 17 9».
Очень часто при работе с массивами используется функция ArrayCopy() (примеры кода располагаются в скрипте «ArrayCopy»). Функция позволяет копировать данные одного массива в другой массив, а также перемещать данные внутри одного массива. Для изучения этой функции создадим скрипт «ArrayCopy». Объявим статический массив с инициализацией рядом чисел и объявим динамический массив, скопируем данные статического массива в динамический. Первый параметром в функцию передается массив назначения, вторым – массив источник:
int a[]={1,2,3,4,5,6,7};
int b[];
ArrayCopy(b,a);
ArrayPrint(b);
В результате работы этого кода в журнал будет выведена строка: «1 2 3 4 5 6 7». Заметьте, у массива b автоматически увеличился размер. Однако если выполнить копирование меньшего массива в больший, размер не будет уменьшен:
int c[]={11,22,33};
ArrayCopy(b,c);
ArrayPrint(b);
Результат: «11 22 33 4 5 6 7».
В функцию ArrayCopy() можно передавать три дополнительных параметра, обеспечивающих частичное копирование массива. Третьим параметром функции указывается индекс в массиве назначения (в том, в который выполняется копирование), четвертым – индекс в источнике (в массиве из которого выполняется копирование), пятым – количество копируемых элементов. Если пятый параметр не указывать, будут скопированы все элементы, начиная с индекса источника. Объявим массив и инициализируем его рядом чисел от 0 до 9, затем переместим элементы 7, 8 (два элемента) на позицию 3:
int d[]={0,1,2,3,4,5,6,7,8,9};
ArrayCopy(d,d,3,7,2);
ArrayPrint(d);
Результат: «0 1 2 7 8 5 6 7 8 9» – элементы 3 и 4 заменены элементами 7 и 8.
Подобный подход с копированием данных внутри одного массива можно использовать для удаления части массива. Удалим элементы 3, 4. Кроме перемещения данных в массиве еще потребуется уменьшить его размер на два элемента. Поэтому массив d не получится использовать, он статический. Объявим динамический массив e и скопируем в него массив d, все последующие действия будем выполнять с массивом е:
int e[];
ArrayCopy(e,d);
ArrayCopy(e,e,3,5);
ArrayResize(e,ArraySize(e)-2); ArrayPrint(e);
Результат: «0 1 2 5 6 7 8 9».
На практике нет необходимости использовать такой подход для удаления элементов массива, поскольку существует специальная функция ArrayRemove(). Первым параметром в функцию передается массив, второй параметр указывает первый индекс удаляемых элементов, третий параметр указывает количество удаляемых элементов:
ArrayRemove(e,3,2);
ArrayPrint(e);
Результат: «0 1 2 7 8 9».
Функция ArrayInsert() позволяет вставлять один массив в другой. Первым параметром в функцию передается массив назначения, вторым – массив источник. Третий параметр указывает индекс в массиве назначения, с которого выполняется вставка. Четвертый параметр – количество вставляемых элементов. Восстановим массив e, вставим в него из массива a недостающие элементы. В массиве e пропущены элементы 3, 4, 5, 6. В массиве a они начинаются с индекса 2, количество – 4:
ArrayInsert(e,a,3,2,4); ArrayPrint(e);
Результат: «0 1 2 3 4 5 6 7 8 9».
Функция ArrayMaximum() позволяет найти в массиве индекс элемента с максимальным значением. По этому индексу потом можно получить максимальное значение. Соответственно, функция ArrayMinimum() позволяет найти элемент с минимальным значением. Если в массиве несколько элементов с максимальным или минимальным значением, будет получен индекс первого элемента. Примеры для изучения этих функций напишем в скрипте «ArrayMaxMin»:
int a[]={5,1,8,3,2,1,7,8,6};
int maxIndex=ArrayMaximum(a); int maxVal=a[maxIndex];
Alert("maxIndex=",maxIndex,", maxVal=",maxVal);
int minIndex=ArrayMinimum(a); int minVal=a[minIndex];
Alert("minIndex=",minIndex,", minVal=",minVal);
Результаты: maxIndex=2, maxVal=8 » и «minIndex=1, minVal=1».
В функции ArrayMaximum() и ArrayMaximum() можно передавать два дополнительных параметра: индекс, с которого выполняется поиск, и количество элементов, среди которых выполняется поиск. Эти функции с дополнительными параметрами часто используются при создании индикаторов технического анализа.
Функция ArrayBSearch() выполняет бинарный поиск элемента с заданным значением. Особенность алгоритма бинарного поиска в том, что он работает только на упорядоченных (отсортированных) массивах. Суть алгоритма в том, что искомое значение сравнивается со значением в середине массива, таким образом, зона поиска сокращается в два раза, затем сравнивают искомое значение с серединой оставшейся зоны и т.д. Таким образом, искомое значение можно найти значительно быстрее, чем через поиск простым перебором всех элементов массива.
Для сортировки массива используется функция ArraySort():
ArraySort(a);
ArrayPrint(a);
Результат: «1 1 2 3 5 6 7 8 8».
Найдем индекс элемента со значением 3:
int i1=ArrayBsearch(a,3); Alert("i1=",i1);
Результат: «i1=3».
Если в массиве есть несколько элементов с искомым значением, то может быть найден любой из них. Найдет элементы со значением 1 и 8:
int i2=ArrayBsearch(a,1);
Alert("i2=",i2);
int i3=ArrayBsearch(a,8); Alert(«i3=»,i3);
Результат: «i2=0», «i3=8». В одном случае найден первый элемент, в другом случае – второй.
Если стоит задача непременно найти первый или последний элемент, надо довершить работу самостоятельно при помощи цикла.
Существует еще достаточно большое количество функций по работе с массивами, но они почти не используются, поэтому, если вам интересно, изучите их по справке самостоятельно: Справочник MQL5 – Операции с массивами.
Многомерные массивы
Пока что были рассмотрены одномерные массивы, однако существуют еще массивы многомерные, в MQL5 вплоть до четырех измерений. Многомерный массив, также как и одномерный, может быть статическим и динамическим. Но динамическим он может быть только по первому измерению. Размеры по остальным измерения указываются при объявлении и не могут меняться в дальнейшем:
int a[][2][2][2];
Код этого и последующих примеров располагается в файле «MultidimensionalArrays».
Чтобы установить размер массива по первому измерению, используется функция ArrayResize(), в которую передается массив и число, указывающее размер по первому измерению:
ArrayResize(a,3);
Функция ArraySize() для многомерных массивов возвращает обще количество элементов:
int size=ArraySize(a);
Alert("size=",size);
Результат: «1: 24» – на один индекс по первого измерения приходится всего 8 элементов (2*2*2).
Длина по первому измерению 3, соответственно всего имеем 24 элемента.
Для определения размера по одному измерению используется функция ArrayRange(). В функцию передается имя массива и индекс измерения, размер которого надо узнать. Значит, чтобы узнать размер первого измерения, надо передать значение 0:
int size1=ArrayRange(a,0); Alert("size1=",size1);
Результат: «size1=3».
Определим размеры остальных измерений:
int size2=ArrayRange(a,1); int size3=ArrayRange(a,2); int size4=ArrayRange(a,3);
Alert("size2=",size2,", size3=",size3,", size4=",size4);
Результат: «size2=2, size3=2, size4=2».
Теперь по массиву можно пройти в цикле и заполнить его значениями:
int n=0;
for(int i1=0;i1<size1;i1++){ for(int i2=0;i2<size2;i2++){
for(int i3=0;i3<size3;i3++){ for(int i4=0;i4<size4;i4++){
a[i1][i2][i3][i4]=n++;
}
}
}
}
К сожалению, функция ArrayPrint() применима только к простым массивам, поэтому, чтобы посмотреть содержимое массива a придется написать свою функцию:
string str="";
for(int i1=0;i1<size1;i1++){ str+=(i1==0?"":",")+"{";
for(int i2=0;i2<size2;i2++){ str+=(i2==0?"":",")+"{";
for(int i3=0;i3<size3;i3++){ str+=(i3==0?"":",")+"{";
for(int i4=0;i4<size4;i4++){ str+=(i4==0?"":",")+(string)a[i1][i2][i3][i4];
}
str+="}";
}
str+="}";
}
str+="}";
}
Alert(str);
Результат:
«{{{0,1},{2,3}},{{4,5},{6,7}}},{{{8,9},{10,11}},{{12,13},{14,15}}},{{{16,17},{18,19}},{{20,21},{22,23}}}».
Точно также формируются данные для инициализации многомерного массива при его объявлении. Объявим и инициализируем двухмерный массив с двумя элементами во втором измерении:
int b[][2]={{1,2},{3,4},{5,6}};
Содержимое такого массива можно посмотреть функцией ArrayPrint():
ArrayPrint(b);
Результат работы этой части кода показан на рис. 30.
К многомерным массивам применимы все функции языка MQL5, которые применимы к одномерным массивам, но с некоторыми нюансами. Практически, при решении общих задач создания экспертов и индикаторов, какой либо сложной работы с многомерными массивами обычно не выполняется. Поэтому, в случае необходимости, можно ознакомиться с особенностями применения той или иной функции по справочному руководству.

Рис. 30. Вывод двухмерного массива функцией ArrayPrint()
Разберем один случай применения двухмерных массивов, который может пригодиться при создании экспертов. Иногда бывает нужно получить тикеты ордеров в том порядке, в каком ордера расположены на графике, то есть упорядоченные по цене. В этом случае используется двухмерный массив. В элементах второго измерения с индексом ноль располагается цена, в элементах с индексом 1 – тикеты. Применение к такому массиву функции ArraySort() упорядочивает массив по элементам второго измерение с индексом 0.
double list[][2];
ArrayResize(list,3);
list[0][0]=1.03; list[0][1]=33333; list[1][0]=1.01; list[1][1]=11111; list[2][0]=1.02; list[2][1]=22222;
ArrayPrint(list);
ArraySort(list);
ArrayPrint(list);
Результат работы этого кода показан на рис. 31.
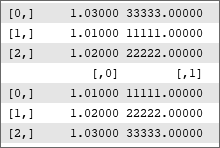
Рис. 31. Двухмерный массив до сортировки и после
Теперь по массиву можно пройти в цикле и обработать ордера в нужном порядке.
Не исключено, что у вас остались какие-нибудь вопросы, касающиеся массивов, сформулируйте их для себя, придумайте примеры для их исследования и понимания, поэкспериментируйте самостоятельно, если, конечно, вам интересно.
Макроподстановки
Ранее в разделе «Арифметика» рекомендовалось, когда где-то в коде используется числовая константа, не писать ее непосредственно, а объявлять переменную и использовать ее. Потом, в случае необходимости изменить значение, переменную очень легко найти в коде, чем самом место, в котором она используется. Однако использование переменных для этих целей не совсем рационально, к тому же не везде их получится использовать, в частности не получится для
указания размеров массива (как статического, так и размеров измерений динамического). На этот случай в языке MQL5 существует возможность выполнения макроподстановок. По сути, макроподстановка подобна замене текста – одно слово заменятся на другое или на несколько других. Выполняется эта замена непосредственно перед компиляцией. Сам файл с кодом при этом остается без изменений.
Обычно макроподстановки определяются в верхней части файла, но могут находиться в любом месте файла, но в начале строки. Начинается макроподстановка с директивы «#define», после нее идет имя макроса и замена. Имя макроса принято писать заглавными буквами с подчеркиваниями. Эксперименты с макросами выполняются в файле «006 Arrays/DefineSimple». Определим несколько макроподстановок:
#define SIZE_1 10
#define DIM_1_1 2
#define DIM_1_2 2
#define SIZE_2 5
#define DIM_2_1 3
#define DIM_2_2 3
Точка с запятой в конце строки с макроподстановкой не ставится. В функции OnStart() объявим два массива:
int ar1[SIZE_1][DIM_1_1][DIM_1_2]; double ar2[SIZE_2][DIM_2_1][DIM_2_2];
Макроподстановки могут использоваться не только для чисел, но и для строк:
#define HELLO "Здравствуй, Мир!"
Его использование:
Alert(HELLO);
Результат: «Здравствуй, Мир!».
На этом возможности макроподстановок далеко не исчерпываются. В дальнейшем, по мере необходимости, будут рассматриваться их остальные возможности.
Строки
Обработка строк не такая частая задача при программировании на MQL5, но иногда приходится иметь с ними дело. Чаще всего работа со строками выполняется при обработке внешних параметров. Строковые переменные позволяют создавать универсальные внешние параметры экспертов и индикаторов. Например, иногда может использоваться не стандартный ряд возрастания лота – ни арифметическая прогрессия, ни геометрическая, а совершенно произвольная. Использование строковой переменой дает в этом случае полную свободу, вопервых, на каждом уровне можно задать произвольный лот, во-вторых, тут же, по количеству введенных значений определяется длина прогрессии. Конечно, это не единственная задача, таким образом можно вводить любые другие параметры: стоплосс, текйпроифт и пр. Вторая задача, при решении корой приходится иметь дело со строками, это создание информационных панелей, попросту говоря – вывод данных на экран. Также иногда приходится работать с фйлами – читать строки и выбирать из них необходимые данные.
Разберем те функции, с которыми вам обязательно придется иметь когда-нибудь дело. С остальными функция сможете разобраться самостоятельно по справочному руководству, если в этом возникнет необходимость. Для выполнения учебных примеров создайте папку «007 String», а в ней скрипт с именем «String».
С функция StringTrimLeft() и StringTrimRight() вы уже знакомы, они выполняют удаление пробелов соответственно с левой стороны и с правой стороны строки. Кроме пробелов удаляются символы табуляции и новой строки, в общем – то, что не является текстом. Функции возвращают количество уделенных символов, а обрабатываемая строка перелается в функцию как параметр по ссылке:
string str=" строка "; // 2 пробела слева и 3 справа
int fromLeft=StringTrimLeft(str); int fromRigh=StringTrimRight(str);
Alert("fromLeft=",fromLeft,", fromRigh=",fromRigh,", |",str,"|");
Результат: «fromLeft=2, fromRigh=3, |строка|».
Функция StringFind() находит в строке позицию подстроки. Первым параметром в функцию передается строка, в которой выполняется поиск, вторым параметром передается искомая строка, третьим параметром передается позиция с которой выполнятся поиск. Отсчет позиции ведется с нуля. Допустим, есть строка с названиями параметров и их значениями в скобках:
str="StopLoss(35), TakeProfit(55), Lot(0.1)";
Нужно извлечь значение параметра TakeProfit.
Надо иметь в виду, что функция StringFind() работает с учетом регистра (различает строчные и заглавные буквы). Если в строке вместо «TakeProfit» будет написано «Takeprofit», а мы будем искать именно «TakeProfit», ничего не получится. Поэтому, прежде чем применять эту функцию, не помешает преобразовать строку так, чтобы она состояла только из строчных букв, также надо будет преобразовать искомую строку или уже в коде писать ее в соответствующем регистре. Значит, для преобразования строки к нижнему регистру (строчные буквы), используется функция StringToLower(), для преобразования к верхнему регистру – StringToUpper(). Преобразуем строку к нижнему регистру:
StringToLower(str);
Результат: «str=stoploss(35), takeprofit(55), lot(0.1)».
Найдем подстроку «takeprofit»:
int p1=StringFind(str,"takeprofit",0);
Начиная от этой позиции, найдем позицию открывающей скобки:
int p2=StringFind(str,"(",p1);
Начиная от позиции открывающей скобки, найдет позицию закрывающей скобки:
int p3=StringFind(str,")",p2);
Остается извлечь текст между позициями p2 и p3. Для этого используется функция StringSubstr(), в функцию передается три параметра: первый – строка из которой выполняется извлечение подстроки, второй – позиция с которой начинается извлечение, третий – количество извлекаемых
символов. В переменной p2 находится позиция открывающей скобки, значит, ее надо увеличить на
1. Соответственно, количество извлекаемых символов будет рассчитано как разность p3 и p2,
уменьшенная на 1:
string val=StringSubstr(str,p2+1,p3-p2-1); Alert("val=",val);
Результат: «val=55».
Конечно, на практике было бы желательно или даже необходимо проверять промежуточные значения p1, p2, p3. Ведь в реальности данные вводит человек, какие-то символы могут быть пропущены по ошибке, тогда будет невозможно извлечь нужные данные. Если искомая строка не найдена, функция StringFind() дает значение -1, в этом случае пользователя надо уведомить окном сообщения.
Пока в примере кода значение числового параметра находится в строковой переменной val, поэтому далее его надо будет присвоить целочисленной переменной. Это можно сделать двумя способами. Так:
int val1=(int)val;
А можно при помощи функции StringToInteger(), но результатом функции является переменная long, поэтому ее надо преобразовать в int:
int val2=(int)StringToInteger(val);
Впрочем, переменную val2 можно было объявить как long.
Для преобразования строки в число double используется функция StringToDouble(). При вводе числа с десятичным разделителем, пользователь обычно не задумывается о том, какой знак нужно использовать, он может ввести как точку, так и запятую, а правильным десятичным разделителем в MQL5 является точка. Поэтому, прежде чем преобразовывать строку в число, желательно выполнить замену запятой на точку, для этого подойдет функция StringReplace(). Первым параметром в функцию передается обрабатываемая строка, вторым параметром – подстрока, которую надо заменить, третьим – подстрока на которую надо сделать замену. Допустим, есть строка со значением лота, выполним замену и преобразуем строку в double. Для эксперимента выполним преобразование с заменой запятой и без:
string lot="0,1";
double lotVal01=StringToDouble(lot); StringReplace(lot,",",".");
double lotVal02=StringToDouble(lot); Alert("lotVal01=",lotVal01,", lotVal02=",lotVal02);
Результат: «lotVal01=0.0, lotVal02=0.1» – первый результат равен нулю, поскольку не выполнялась замена запятой на точку.
Функция StringSplit() используется для разбиения строки в массив по указанному разделителю. Первым параметром в функцию передается разбиваемая строка, вторым параметром указывается код символа, являющегося разделителем. Получить этот код очень просто, достаточно записать нужный символ в одинарных кавычках:
int code=';';
Alert("code=",code);
Результат: «code=59».
Третьим параметром в функцию передается строковый массив, который будет заполнен отрезками разбитой строки. Допустим, есть строка с последовательностью лотов, одно значение отделяется от другого точкой с запятой:
string lots="0.1; 0,3; 0.7"; string tmp[]; StringSplit(lots,';',tmp); ArrayPrint(tmp);
Результат: «»0.1″ » 0,3″ » 0.7″».
Далее копируем строковый массив в массив double (с заменой запятых на точки):
double dlots[]; ArrayResize(dlots,ArraySize(tmp)); for(int i=ArraySize(tmp)-1;i>=0;i--){
StringReplace(tmp[i],",","."); dlots[i]=StringToDouble(tmp[i]);
}
ArrayPrint(dlots);
Результат: «0.10000 0.30000 0.70000».
Иногда бывает нужно обработать строку посимвольно, для этого используется цикл. А для цикла нужен размер строки, он определяется функцией StringLen():
int len=StringLen(str);
Напишем код, преобразующий начальные буквы всех слов в строке str в верхний регистр. Для этого потребуется две вспомогательные переменные. В одну, по мере обхода обрабатываемой строки в цикле, будем добавлять по одному символу, во второй будем хранить предыдущий символ. Чтобы первое слово строки было обработано, второй вспомогательной переменой сразу присвоим значение » » (пробел). На каждой итерации цикла будем извлекать из строки по одному символу. Если предыдущий символ является пробелом, то у текущего символа будет менять регистр, а если не является пробелом, то будем добавлять его к временной строке без изменения. После цикла значение временной переменной присвоим исходной переменой:
int len=StringLen(str); string pch=" ";
string tstr="";
for(int i=0;i<len;i++){
string ch=StringSubstr(str,i,1); if(pch==" "){
StringToUpper(ch);
}
tstr+=ch; pch=ch;
}
str=tstr;
Alert("str=",str);
Результат: «str=Stoploss(35), Takeprofit(55), Lot(0.1)».
Вернемся немного к коду символа. Существует два основных типа кодировки текстовых символов: ANSI (American national standards institute – Американский национальный институт стандартов) и UTF (Unicode Transformation Format – формат преобразования уникод). В кодировке ANSI существует 256 кодов (от 0 до 255), существует различные наборы кодов для разных языков, но во все наборы входит латинский алфавит и знаки препинания, они занимают коды от 0 до 127. Далее, с кода 128 идут коды какого-то другого языка.
В уникоде существуют тысячи кодов для символов огромного количества различных языков, есть даже китайские иероглифы и различные экзотические алфавиты. В уникоде тоже начальные символы отведены под латинский алфавит и знаки препинания. В языке MQL5 используются строки UTF. Таким образом, полученный ранее код 59 – это код UTF, но не ANSI. Попробуем получить код русской буквы «а»:
Alert("а code=",'а');
Результат: «а code=1072».
Функция StringSetCharacter() позволяет получить символ по его коду. На практике, при создании экспертов и индикаторов эта функция, скорее всего не пригодится, но она интересно для знакомства с уникодом. Вставим в строку символ с кодом 27704 – это код китайского иероглифа «вечность»:
string s; StringSetCharacter(s,0,27704); Alert(s);
Результат: «71».
Как известно, при присвоении строковой переменной значения (текста), оно заключается в двойные кавычки. Иногда бывает нужно, чтобы в самом тексте слово или фраза были заключены в кавычки. Для того чтобы компилятор отличил кавычку в тексте от кавычки начала или окончания текста, перед ней надо поставить обратный слеш. Следующие примеры располагаются в файле
«String2»:
string str="В этом тексте одно \"слово\" в кавычках"; Alert(str);
Результат: «В этом тексте одно «слово» в кавычках». Одинарные кавычки выводятся как есть:
str="и в этом тексте одно 'слово' в кавычках"; Alert(str);
Результат: «и в этом тексте одно ‘слово’ в кавычках».
Имеется возможность обеспечить вывод текста в несколько строк. Для переноса текста на следующую строку используется сочетание символов «\n».
str="Строка-1\nСтрока-2\nСтрока-3"; Comment(str);
Alert(str);
Print(str);
Следует иметь в виду, что при выводе многострочного текста функцией Alert(), текст виден полностью, только пока сообщение является последним (рис. 32).
Затем, при появлении новых сообщений, в истории сообщений видна только первая строка. Вывод многострочного текста функцией Print() идентичен нескольким вызовам функции Print() для каждой отдельной строки.
Рис. 32. Многострочный текст в комментарии графика, в окне сообщения и во вкладке «Эксперты»
С функцией Comment() перенос строки работает нормально.
Знаки табуляции «\t» работают только при выводе функцией Alert(), но только пока сообщение является последним:
str="Колонка-1\tКолонка-2\tКолонка-3\t"; Comment(str);
Alert(str);
Print(str);
Еще может потребоваться вывод обратного слеша (бывает нужен для указания файлового пути), пред ним нужно поставить еще один обратный слеш:
str="D:\\Новая папка"; Alert(str);
Результат: «D:\Новая папка».
Существует еще несколько других знаков, требующих перед ними установки обратного слеша, но практически с ними не приходится иметь дела. Если возникнет необходимость, ознакомьтесь со справочным руководством: Основы языка – Типы данных – Целые типы – Символьные константы.
Функция StringSplit() позволят разбить строку на части по разделителю из одного символа. Рассмотрим, как можно разбить строку на части, если разделитель представляет собой последовательность символов. Создаем скрипт с именем «Split», следующий код пишем в нем. Допусти, в качестве разделителя используется последовательность из двух прямых слешей:
string delimiter="//";
Есть строка с данными, которую надо разделить:
string str="строка-1//строка-2//строка-3";
Первое, что понадобится, это функция поиска подстроки StringFind(), в функцию третьим параметром передается позиция, с которой выполняется поиск. Значит, найдя одну позицию, надо передвинуть позицию начала поиска и снова вызвать функцию StringFind(). Поскольку заранее количество разделителей неизвестно, надо использовать цикл while до тех пор, пока функция StringFind() находит разделитель. Получается, что перед циклом надо вызвать функцию StringFind(), затем повторять ее вызов в цикле:
int p,s=0; p=StringFind(str,delimiter,s); while(p!=-1){
Alert(StringSubstr(str,s,p-s)); s=p+StringLen(delimiter); p=StringFind(str,delimiter,s);
}
Alert(StringSubstr(str,s,StringLen(str)-s));
В результате работы этого скрипта открывается окно с сообщениями: «строка-1», «строка-2», «строка-3».
Однако есть более простой способ. Дело в том, что операция присвоения сама возвращает значение, это значение равно тому же значение, которое присваивается переменной. Таким образом, в круглых скобках цикла while получаем позицию следующего вхождения разделителя и тут же проверяем, действительно ли разделитель найден или пора заканчивать цикл:
int p,s=0; while((p=StringFind(str,delimiter,s))!=-1){
Alert(StringSubstr(str,s,p-s)); s=p+StringLen(delimiter);
}
Alert(StringSubstr(str,s,StringLen(str)-s));
Обратите внимание, после цикла еще раз вызывается функция StringSubstring() чтобы вывести последний участок разделяемой строки или всю строку, если в ней нет ни одного разделителя. Также обратите внимание, как перемещается позиция начала поиска – к позиции вхождения последнего найденного разделителя прибавляется его длина, это нужно, что бы не найти тот же самый разделитель и не войти в бесконечный цикл.
Форматирование чисел
Язык MQL5 имеет очень мощные средства для форматирования чисел, то есть для их преобразования в строки, – это функции PrintFormat(), printf() и StringFormat(). Функции PrintFormat() и printf() абсолютно идентичны, они выполняет вывод во вкладку «Эксперты», как функция Print(). В остальном функции идентичны. Функция StringFormat() выполняет вывод в строковую переменную.
Ранее были рассмотрены функции IntegerToString() и DoubleToString(), которые могут использоваться для вывода значений числовых переменных. Однако функции PrintFormat(), printf() и StringFormat() дают больше возможности для подготовки текстовых сообщений. Возможности этих функций огромны, здесь же разберем только то, что действительно пригодится, но в объеме, которого будет достаточно для создания индикаторов и экспертов.
Основные задачи при формировании текстовых сообщений: вывод содержимого строковой переменной, вывод значения целочисленной переменной и вывод переменной double. С выводом строковых переменных нет никаких особенностей, они выводятся как есть. При выводе целочисленных переменных иногда бывает нужно выровнять их в столбик, для этого в начало чисел добавляются нули (ведущие нули), за счет которых все числа будут иметь одинаковую длину. Основной задачей при выводе переменных double является ограничение количества знаков после запятой, но иногда тоже может возникнуть задача добавления ведущих нулей.
Принцип применения функций такой: в функцию передается строка, в которой указаны места для вывода значений переменных, а после строки через запятую передаются все эти переменные. В строке сообщения, кроме указания места вывода переменной, указываются и правила их вывода (количество ведущих нулей, количество знаков после запятой). Следующие примеры располагаются в скрипте с именем «PrintFormat».
Указание места вывода строковой переменной выполняется символами «%s»:
string name="Вася";
string str=StringFormat("Здравствуй, %s! Как дела?",name); Alert("1: ",str);
Результат: «1: Здравствуй, Вася! Как дела?».
Для вывода переменой типа int используются знаки «%d»:
int ival1=INT_MIN; int ival2=INT_MAX;
str=StringFormat("ival1=%d, ival2=%d",ival1,ival2); Alert("2: ",str);
Результат: «2: ival1=-2147483648, ival2=2147483647».
Заметьте, насколько проще и лаконичней использование такого подхода по сравнению с формированием строки функциями конвертации:
str="ival1="+IntegerToString(ival1)+", ival2="+IntegerToString(ival2); Alert("3: ",str);
Результат: «3: ival1=-2147483648, ival2=2147483647».
Для вывода переменой типа uint используются знаки «%u»:
int uival=UINT_MAX; str=StringFormat("uival=%u",uival); Alert("4: ",str);
Результат: «4: 4294967295».
Для вывода переменных long используются знаки «%I64d»:
long lval1=LONG_MAX; long lval2=LONG_MIN;
str=StringFormat("lval1=%I64d, lval2=%I64d",lval1,lval2); Alert("5: ",str);
Результат: «lval1=9223372036854775807, lval2=-9223372036854775808».
Для вывода переменных ulong используются знаки «%I64u»:
ulong ulval=ULONG_MAX; str=StringFormat("ulval=%I64u",ulval); Alert("6: ",str);
Результат: «ulval=18446744073709551615».
Для добавления ведущих нулей надо после знака «%» указать знак, который будет ведущим (если ведущим должен быть пробел, то ничего не указывать) и число, определяющее минимальную длину числа. В примере ниже для переменных int и uint указано 3 знака, для long и ulong – 7.
int iv=1; uint uiv=1; long lv=1; ulong ulv=1;
str=StringFormat("iv=%03d, uiv=%03u, lv=%07I64d, ulv=%07I64u",iv,uiv,lv,ulv); Alert("7: ",str);
Результат: «7: iv=001, uiv=001, lv=0000001, ulv=0000001».
Если выводимое число длиннее указанной минимальной длины, оно выводится полностью:
iv=12345;
str=StringFormat("iv=%03d",iv); Alert("8: ",str);
Результат: «8: iv=12345».
Для вывода переменой double используются знаки «%f»:
double dv=12.3456789; str=StringFormat("dv=%f",dv); Alert("9: ",str);
Результат: «9: dv=12.345679».
Для ограничения количества знаков после запятой перед знаком «f» ставится точка и число, определяющее точность:
str=StringFormat("dv=%.4f",dv); Alert("10: ",str);
Результат: «10: dv=12.3457». Заметьте, происходит округление до указанной точности, а не просто обрезание лишних цифр.
Добавление ведущих нулей делается так же, как с целочисленными переменными, только надо иметь в виду, что в общую длину входит десятичный разделитель (точка) и все знаки после него. В следующем примере указана минимальная длина 9 знаков:
str=StringFormat("dv=%09.4f",dv); Alert("11: ",str);
Результат: «11: dv=0012.3457».
Вывод переменной double в научном формате выполняется при помощи знаков «%e»:
str=StringFormat("dv=%e",dv); Alert("12: ",str);
Результат: «12: dv=1.234568e+01».
Вместо малой «e», можно использовать заглавную «E»:
str=StringFormat("dv=%e",dv); Alert("13: ",str);
Результат: «12: dv=1.234568E+01».
Форматирование времени
Как вы уже знаете, для хранения времени в языке MQL5 используется переменные типа datetime. В таких переменных время представлено как количество секунд, прошедших с 1-го января 1970-го года. При выводе времени через функции Alert(), Comment(), Print() число автоматически преобразуется в строку, удобную для восприятия человеком. Однако иногда бывает удобней сначала сформировать строку, присваивая ее переменной, и только потом выводить. В этом случае для конвертирования числового значения времени в строку используется функция StringToTime(). Кроме того, благодаря дополнительному параметру, функция позволяет выводить время несколькими способами.
Без дополнительного параметра, наиболее часто используемый вариант:
datetime tm=TimeCurrent(); string str=TimeToString(tm); Alert("1: ",str);
Результат: «1: 2020.06.19 20:23».
Этот и следующий примеры располагаются в скрипте с именем «TimeToString».
Для дополнительного параметра используются предопределенные константы. Вывод только даты:
str=TimeToString(tm,TIME_DATE); Alert("2: ",str);
Результат: « 2: 2020.06.19».
Вывод часов и минут:
str=TimeToString(tm,TIME_MINUTES); Alert("3: ",str);
Результат: « 3: 20:28».
Вывод часов, минут и секунд:
str=TimeToString(tm,TIME_SECONDS); Alert("4: ",str);
Результат: « 4: 20:28:42».
Возможно совмещение нескольких вариантов:
str=TimeToString(tm,TIME_DATE|TIME_SECONDS); Alert("5: ",str);
Результат: «5: 2020.06.19 20:42:59».
Второй параметр, это так называемый флаг. Несколько флагов можно объединять при помощи логической операции «или», обозначаемой знаком «|». Позже в разделе, посвященном побитовым операциям, это будет рассмотрено подробно.
Функции
До этого момента мы уже очень много раз пользовались различными функциями языка MQL5. Кроме использования стандартных (встроенных) функций языка MQL5, мы можем писать свои собственные функции. Под функцией в программировании понимают отдельный участок кода, к которому можно обратиться посредством идентификатора – имени этой функции. Обращение к функции называется вызовом. При вызове функции ей передаются параметры (аргументы), но могут быть функции и без параметров, все зависит от задачи решаемой этой функцией. Значит, функции передают параметры, а она в свою очередь возвращает результат. Это может быть числовое значение – результат каких-то вычислений, может быть значение true/fase, уведомляющее об успешности выполнения каких-то действий. В общем, функция может возвращать данные любого типа, в том числе и строки, или не возвращать никаких данных.
При создании функции первым делом указывает тип данных, которые она будет возвращать. Если функция не должна ничего возвращать, указывается тип void. После типа пишется имя функции и в круглых скобках перечисляются параметры, которые надо будет передавать в функцию при ее вызове. Затем, в фигурных скобках, пишется код функции. Для возвращения из функции значения используется оператор return. Если функция возвращает тип void, оператор return использовать необязательно. Вызов оператора return завершает (прерывает) работу функции. В функциях типа void возможно использование оператора return для прерывания их работы.
Для экспериментов с функциями создайте папку «008 Functions», а в ней скрипт «Functions».
Пример простейшей функции:
void func01(){
Alert("Это сообщение из функции func01()");
}
Эта функция открывает окно с сообщением «Это сообщение из функции func01()». Вызовем эту функцию из функции OnStart():
void OnStart()
{
func01();
}
Теперь напишем чуть более сложную функцию. В функцию будет передаваться два параметра, а возвращать функция будет их сумму:
double sum(double a,double b){ return(a+b);
}
Ее вызов из функции OnStart() сразу с выводом результата в функцию Alert(): Alert(«sum(3.0,5.0)=»,sum(3.0,5.0));
Результат: «sum(3.0,5.0)=8.0».
В разделе «Арифметика» было обещано решение проблемы деления на 0 с функцией гиперболы (1/х). Значит, для расчета гиперболы будем использовать функцию типа bool с двумя параметрами. Первым параметром в нее будет передаваться аргумент, а вторым по ссылке будет передаваться переменная для результата. Для указания того, что переменная передается по ссылке, перед ее именем ставится знак «&». Если аргумент будет равен 0, вернем из функции false, тем самым работа функции будет прервана, если же гиперболу можно рассчитать, сделаем это и присвоим результат второй переменной, а из функции вернем true:
bool hyperbola(double x,double &r){ if(x==0){
return(false);
}
r=1.0/x; return(true);
}
Понятно, если в функцию передать 0, она вернет false, то есть результатом нельзя пользоваться. Интересно, как поведет себя функция при передаче в нее минимально возможного значения, отличного от нуля. Как вы уже должны помнить, это число DBL_MIN. Вызовем функции гиперболы из OnStrt():
double r; if(hyperbola(DBL_MIN,r)){
Alert("1/DBL_MIN=",r);
}
else{
Alert("Неправильный аргумент для функции hyperbola()");
}
Результат: «1/DBL_MIN=4.49423283715579e+307». Как видим, результат является числом, так что функцией можно пользоваться.
Массив передать в функцию можно только по ссылке:
void func02(int & a[]){ ArrayResize(a,2); a[0]=1;
a[1]=2;
}
Обратите внимание, при передаче массива, после его имени ставятся квадратные скобки указывающие, что это массив. Так же можно передавать многомерный массив, но каждый раз надо четко обозначать количество измерений у массива, а так же размеры измерений:
void func03(int & a[][2],int & b[][2][3]){
// ...
}
Создать универсальную функцию, принимающую массив с любым количеством измерений невозможно.
Функция может иметь обязательные и не обязательные параметры. Необязательные параметры должны располагаться после обязательных. Чтобы параметр стал необязательным, ему при объявлении необходимо присвоить значение. Таким образом, если при вызове функции необязательный параметр ей не передается, то используется указанное значение. Такое значение называется значением по умолчанию. Напишем степенную функцию с двумя параметрами. Первый параметр – собственно аргумент, второй – степень. Параметр для степени сделаем необязательным, по умолчанию он будет иметь значение 2 (парабола):
double parabola(double x,double p=2){ return(MathPow(x,p));
}
Вызовем ее из функции OnStart():
r=parabola(3); Alert("parabola(3)=",r);
Результат: «parabola(3)=9.0».
Как видим – функция вызвана с одним параметром и произошло возведение аргумента в степень 2. Если же надо выполнить возведение в другую степень, то функцию надо вызвать с двумя параметрами:
r=parabola(2,3); Alert("parabola(2,3)=",r);
Результат: «parabola(2,3)=8.0».
В функцию sum() сейчас передается два параметра, сделаем перегрузку функции – добавим еще одну функцию с именем sum, но с тремя параметрами:
double sum(double a, double b, double c){ return(a+b+c);
}
Теперь, при написании кода с вызовом функции sum(), откроется подсказка с выбором типа функции, как на рис. 29, но только с двумя вариантами.
Добавим в функцию OnStart() следующий вызов:
r=sum(1,2);
Если выполнить компиляцию скрипта, пока все будет нормально.
Сделаем еще один вариант функции, но со строковыми параметрами (исключительно в учебных целях):
double sum(string a,string b){ return(StringToDouble(a)+StringToDouble(b));
}
Теперь при компиляции возникает ошибка «ambiguous call to overloaded function» – непонятный вызов перегруженной функции. Дело в том, что компилятор принимает параметры 1 и 2 за целочисленные, а функции для такого типа параметров у нас нет. Укажем, что это числа double:
r=sum(1.0,2.0);
После этого компиляция пройдет без ошибок. Однако заметьте, пока функции с параметрами string не было, в функцию с параметрами double можно было передавать целочисленные аргументы без проблем.
В языке MQL5 очень много стандартных перегруженных функций, поэтому не исключено, что вам еще не раз придется столкнуться с ошибкой неопределенного вызова перегруженной функции – то точку с ноликом забудешь, то наоборот напишешь, то тип переменной перепутаешь, а перегруженные функции не терпят вольностей с типами параметров.
Еще о редакторе
Уже даже файлы с учебными примерами вырастают в размере так, что их приходится прокручивать полосой прокрутки, но это только начало. Средний эксперт, это десятки функций, сотни, тысячи строк кода. Бывают даже и десятки тысяч строк. Так что во всем этом нужно как-то ориентироваться.
Продолжаем работу с файлом «008 Functions/Functions». Иногда, работая над кодом в одном месте файла, бывает нужно вспомнить все нюансы работы какой-то другой функции или скопировать часть кода. Редактор MetaEditor обеспечивает возможностью быстро найти любую функцию в коде. На панели инструментов есть кнопка «Список функций в файле, Alt+M», при нажатии на эту кнопку открывается вкладка меню со списком всех функций (рис. 33) из файла.
Рис. 33. Кнопка для открытия списка функций и список
Если щелкнуть на какой-то функции из этого списка, произойдет прокрутка файла и курсор встанет перед именем функции.
Другой способ перейти к коду функции – установить курсор на вызов функции, щелкнуть правой кнопкой мыши и выбрать команду «Перейти к определению» (рис. 34).
После того, как вы посмотрели функцию или скопировали какую-то часть кода, бывает нужно быстро вернуться назад – к тому месту, где вы писали код. Возврат можно совершить использованием команды отмены – нажать Ctrl+Z и тут же Ctrl+Y – чтобы вернуть отмененное. Если же вы занимаетесь изучением кода, а для этого бывает нужно от одной функции переходить к другой, то перед переходом к функции рекомендуется в конце какой-нибудь строки поставить пробел, затем, после перехода к другой функции, в ней поставить пробел. Таким образом, используя команду отмены, получится вернуться к предыдущей функции, а используя команду повтора – к следующей. А может быть, вы найдете для себя более удобный способ.
Рис. 34. Команда контекстного меню для перехода к функции
Еще одна полезная функция редактора – поиск. Вам может быть знакома эта функция по любому текстовому редактору, она просто выполняет поиск указанного слова или более крупного фрагмента текста. Обычно команда поиска располагается в главном меню во вкладке «Правка» или «Редактирование», а в редакторе MetaEditor она располагается на верхнем уровне главного меню, поскольку ей приходится пользоваться очень часто. Не обязательно вводить искомое слово с клавиатуры. Выделите какой-нибудь небольшой фрагмент кода, например, имя функции, и в главном меню, во вкладке «Поиск» выберите команду «Поиск» или используйте сочетание клавиш Ctrl+F. В результате откроется окно поиска, а в поле «Найти» будет введен выделенный ранее текст, останется только нажать кнопку «Найти далее» (рис. 35).
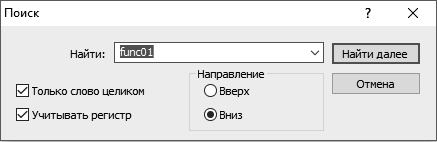
Рис. 35. Окно функции поиска
После первого нажатия на кнопку «Найти далее» можно закрыть окно поиска, а дальше использовать клавишу F3 для поиска вперед или F3+Shift для поиска назад. Обратите внимание на элементы управления ниже поля «Найти». Их назначение должно быть очевидным из их названия, если не все понятно, изучите их по справочному руководству. Не забывайте о них. Если упустить их из вида, то иногда могут возникать сложности с поиском, кажущиеся странными.
Пока в файле не много кода и функций, вкладка меню (рис. 33) небольшая, но бывают такие файлы, в которых вкладка не вмещается на экран, в этом случаи у вкладки появляются элементы управления для ее прокрутки, но все равно, это не очень удобно. В языке MQL5 есть возможность подключать к одному файлу другие файлы. Таким образом, код распределяется, а каждый файл становится удобным для понимания. Делается подключение файлов при помощи директивы «#include». Пока не будет подробно рассматривать эту возможность языка.
Смысл в том, что с одной стороны использование нескольких файлов удобно, однако обычная функция поиска в редакторе ограничена только одним файлов, что приносит некоторые сложности при анализе кода (чужого или при вспоминании своего). На это случай в редакторе есть дополнительная функция поиска – «Поиск в файле» (Главное меню – Поиск – Поиск в файле). В окне поиска по файлам указывается искомое слово, тип файлов, в которых выполняется поиск и папка поиска. Результаты поиска по файлам отображаются списком в окне «Навигатор». Подробно не будем останавливаться на этой функции, пока в ней нет необходимости, а когда необходимость возникнет, у вас будет достаточно опыта, чтобы разобраться с ней самостоятельно.
Так же нужно знать про существование функции замены (Главное меню – Поиск – Заменить). Эта функция бывает очень полезна при выполнении доработок. Иногда бывает нужно переделать какой-то фрагмент кода, например вызов функции технического индикатора – заменить префиксы у параметров. Например, функция скользящей средней iMA() вызывается с параметрами MA01Period, MA01Method, MA01Price, а надо использоваться еще одну среднюю с параметрами MA02Period, MA02Method, MA02Price – при помощи функции замены можно легко заменить все фрагменты «01» на «02». Однако надо с осторожностью пользоваться кнопкой «Заменить все», можно случайно выполнить замену в тех участках кода, в которых вы не планировали это делать. Лучше делать замену по одной при помощи кнопки «Заменить».
Иногда бывает так, что необходимо объявить несколько переменных или функций, но фантазия немного подводит, думаешь, что пока используешь такое имя, а потом его изменишь при помощи функции замены. На этого случай совет из практического опыта – не стоит так делать. В таком коде потом бывает сложно ориентироваться и вспоминать его тоже бывает сложно. Лучше не торопиться – уделить время придумыванию подходящих имен сразу. Совсем другая ситуация возникает при разборе чужого кода, в этом случае функция замены будет очень полезна. Если, разобрав работу какой-то функции или назначение переменной, дать ей имя в соответствии со своими представлениями, код в итоге станет более легким для понимания.
Область видимости переменных
Существует два места для объявления переменных: в общем пространстве файла (там, где объявлялись внешние переменные input) и непосредственно в функциях. Переменная, объявленная в какой-то функции, может использовать только в этой функциях. Из других функций доступа к этим переменным нет. Поэтому такие переменные называются локальными (местными). Таким образом, разные функции могут иметь переменные с одинаковыми именами, но это разные переменные.
Там, где мы раньше объявляли переменные input можно объявлять переменные без спецификатора input, в любом случае (с input и без), эти переменные являются глобальными, то есть они видимы из всех мест файла – из всех функций. В языке MQL5 еще существуют так называемые глобальные переменные терминала. Пока не будем рассматривать их, это особая тема. Главное, условиться с терминологией, если подразумевается глобальная переменная терминала, то всегда так и надо писать и говорить «глобальная переменная терминала», а когда имеется ввиду переменная, объявленная в файле, то просто – «глобальная переменная».
В папке «008 Functions» создадим скрипт с именем «Scope». Объявим переменную с именем а чуть выше функции OnStart() и еще напишем пару функций. В одной функции присвоим переменой a значение и объявим переменную b с инициализацией. А в другой функции, при помощи функции Print() выведем значение переменной a:
int a;
void OnStart()
{
fun1();
fun2();
}
void fun1(){ int b=1; a=2;
}
void fun2(){ Print(a);
}
Пока скрипт компилируется и работает. Попробуем во второй функции сделать вывод переменой
b:
void fun2(){ Print(a);
Print(b);
}
После этого компиляция будет проходить с ошибкой «’b’ – undeclared identifier» (не объявленный идентификатор) – значит, область видимости переменной b ограничено функцией fun1().
Вообще область видимости определяется не конкретно функцией, а именно фигурными скобками. То есть, даже внутри одной функции могут быть переменные разной видимости внутри этой функции. Напишем функцию fun3(), в ней переменную c объявим в самом начале функции, а переменную d внутри фигурных скобок. Вызов функции Print() с переменной c работает нормально из любого места функции, а вот если добавить вывод значения переменой d за пределами скобок, возникнет ошибка компиляции:
void fun3(){ int c=3;
{
Print(c); int d=4;
}
//Print(d);
}
Имейте в виду эту особенность при использовании циклов for, while и т.п. Между прочим, переменная, объявленная в круглых скобках цикла for, имеет локальную видимость:
for(int i=0;i<3;i++){
//
}
//Print(i);
Если в приведенном выше примере убрать знаки комментарий перед функцией Print(), при компиляции будет ошибка.
Но иногда, когда выполняется преждевременное завершение цикла, после него бывает нужно значение этой переменной. В этом случае нужно объявить переменную до оператора for:
int j; for(j=0;j<3;j++){
//
}
Print(j);
Статические переменные
Локальные переменные, то есть переменные, объявленные в функции, при каждом вызове функции инициализируются заново. Иногда бывает нужно, что бы какая-то переменная в функции сохраняла свое значения. В этом случае можно использовать глобальную переменную. Создайте скрипт с именем «Static», пишем код в нем. Объявляем глобальную переменную:
int cnt=0;
Создаем функцию:
int counter(){ cnt++; return(cnt);
}
При каждом вызове функции происходит увеличение переменной cnt на 1, и функция возвращает новое значение. В функции OnStart() вызовем три раза функцию counter(), присваивая результат переменной c:
int c=counter(); c=counter(); c=counter(); Alert("1: ",c);
Результат: «1: 3».
Недостатком такого подхода является то, что код, относящийся к решению одной функциональной задачи, расположен в двух разных местах файла.
Другой способ решения данной задачи – использование статической переменной. Создаем функцию counter2(). Для создания статической переменной используется модификатор static:
int counter2(){ static int cnt2=0; cnt2++; return(cnt);
}
Код в функции OnStart():
c=counter2(); c=counter2(); c=counter2(); Alert("2: ",c);
Результат: «3: 3».
Теперь задача решается только одной функцией без посторонних переменных. Однако в этом случае имеется свой недостаток – отсутствует доступ к переменной-счетчику, нет возможности ее обнулить.
Работа с файлами
Умение работать с файлами является важным и даже необходимым навыком при программировании на MQL5. Хотя при создании советников и индикаторов с файлами работать приходится не часто, тем не менее, бывают случаи, когда использование файлов необходимо. Может быть, надо проанализировать отчет после тестирования или от реальной торговли. Может быть, надо провести статистический анализ исторических данных, результаты которого удобней представить в виде текстовых таблиц. У некоторых советников бывают такие сложные и объемные настройки, что лучше делать описание параметров в текстовом файле, который потом будет читаться советником. Наиболее частая задача, для которой используется файл – задание списка символов для мультивалютного эксперта или индикатора. Записать список из пары десятков символов в файл гораздо проще, чем вводить их через запятую в строковую переменную. Файлы можно даже использовать для обмена данными между несколькими терминалами.
Работа с файлами включает три этапа: открытие, чтение или запись данных, закрытие. Для открытия файла используется функция FileOpen(). Первым параметром в функцию передается имя файла. Файлы, с которыми работает функция, могут находиться только в специальной папке. Что бы найти эту папку, сначала надо открыть папку данных терминала (Главное меню терминала или редактора – Файл – Открыть каталог данных), затем открыть папку «MQL5», а в ней будет находиться папка «Files». Файлы могут находиться непосредственно в ней или в других подпапках. Такие ограничения наложены с целью обеспечения безопасности – чтобы эксперты и прочие программы, написанные на MQL5, не могли нарушить работу терминала или вообще компьютера.
Есть еще одно место, из которого допускается работа с файлами, это общая папка данных терминалов. Допускается установка нескольких терминалов на один компьютере, в этом случае использование общей папки данных позволяет выполнять обмен данными между терминалами. Команда открытия общей папки данных есть только в редакторе: Главное меню – Файл – Открыть общую папку данных, а в ней находится папка «Files».
Вторым параметром в функцию FileOpen() передается набор флагов, определяющих режим работы с файлом. Вообще файлы бывают двух типов: текстовые и бинарные. Если объяснять коротко, то текстовые файлы, это такие, у которых записанные в них данные соответствуют тому, что вы увидите, если откроете файл в текстовом редакторе. Такие файлы можно создавать самостоятельно, а созданные программно читать и редактировать в текстовом редакторе. Можно использовать редактор notepade, входящий в комплект Windows или редактор Metaeditor. Заметьте, в навигаторе редактора есть доступ к папке «Files», расположенной в папке данных терминала. В MQL5 текстовые файлы могут быть двух типов: обычные текстовые, такие файлы обычно имеют расширение *.txt и текстовые с разделителями полей, они обычно имеют расширение *.csv.
Бинарные файлы предназначены только для программного чтения и записи. Если такой файл открыть в редакторе, в нем можно увидеть непонятный набор символов, которые даже и не стоит пытаться редактировать самостоятельно, после этого файл будет читаться с ошибкой. Конечно, существуют специальные бинарные редакторы для работы с такими файлами, но работа с ними уходит слишком далеко за пределы темы программирования на MQL5. Преимущества бинарных файлов в том, что они позволяют очень быстро сохранять и читать большие объемы данных. Если нет задачи чтения и сохранения больших объемов данных, то нужно делать однозначный выбор в пользу текстовых файлов – они позволяют проконтролировать правильность выполняемой с ними роботы, что очень важно для новичков в программировании.
При открытии файла, кроме режима текстовый/бинарный необходимо указать режим чтения или записи (или совместный режим чтения и записи). При открытии файла для записи, если его не существует, он будет создан, а если существует, то он будет очищен – запомните это хорошо, чтобы не потерять данные. Открывать в режиме чтения можно только существующий файл. Наиболее удобно открывать файл одновременно в режиме записи и чтения, в этом случае несуществующий файл будет создан, а если файл существовал, его данные сохранятся.
Функция FileOpen() возвращает так называемый хэндл – числовой идентификатор файла, который потом используется во всех остальных функциях. Если функция вернула значение -1 (соответствует константе INVALID_HANDLE), это значит, что файл не удалось открыть и дельнейшие с ним действия не имеют смысла. Такое случается, если файл открыт в другой программе, то есть одновременно несколько программ не могут открыть один файл. Впрочем, способ для одновременного открытия одного файла существует, но использовать его не рекомендуется. Дело в том, что такую работу с файлом надо очень серьезно продумать, чтобы одна программа не считывала еще не полностью записанные данные. А вот когда с файлом может работать одна программа, ошибка открытия файла означает, что файл занят – надо повторить попытку, и если на очередной попытке открытие произойдет, это означает, что другая программа полностью завершила свои действия. Если запись в файл не выполняется, тогда можно смело давать одновременный доступ к файлу из нескольких программ.
Если из теории что-то оказалось непонятным, все проясниться в процессе практической работы. Создайте папку «009 Files», а в ней скрипт «Files». Сначала создадим текстовый файл и запишем в него пару строк. Открываем текстовый файл для записи:
string fileName="file.txt";
int h=FileOpen(fileName,FILE_TXT|FILE_WRITE);
После попытки открытия проверяем хэндл, если открыть файл не удалось, завершаем работы функции OnStart():
if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
Для записи в файл в текстовом режиме может использоваться только одна функция FileWrite().
Первым параметром в нее передается хэндл, вторым – записываемая строка:
FileWrite(h,"Строка-1");
Запишем еще одну строку:
FileWrite(h,"Строка-2");
После выполнения записи закрываем файл функцией FileClose(). В эту функцию передается один параметр – хэндл файла:
FileClose(h);
Компилируем скрипт и запускаем его в терминале. В навигаторе редактора, в папке Files должен появиться файл. Щелкаем по строке с его именем , чтобы открыть файл в редакторе (рис. 36).
Рис. 36. Файл в навигаторе и он же открытый в рабочем поле редактора
Добавьте в файл вручную еще одну строку: «Строка-3» и нажмите кнопку «Сохранить» на панели инструментов редактора или выполните команду главного меню: Файл – Сохранить.
Теперь будем читать файл. Создайте скрипт с именем «File2». Сначала открываем файл, но уже с флагом для чтения:
string fileName="file.txt";
int h=FileOpen(fileName,FILE_TXT|FILE_READ);
Проверяем хэндл:
if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
Чтение из файла выполняется построчно функцией FileReadString(). Один вызов функции читает первую строку, второй – вторую и т.д. Обычно неизвестно, сколько в файле строк, нужно читать все с начала до конца. О достижении конца файла, можно узнать при помощи функции FileIsEnding(). Создаем цикл while, который будет работать до тех пор, пока конец файла не достигнут, а внутри цикла будем выполнять чтение из файла:
while(!FileIsEnding(h)){
string str=FileReadString(h); Alert(str);
}
В конце закрываем файл:
FileClose(h);
Запускаем скрипт и получаем окно с тремя строками, в том числе со строкой, добавленной вручную (рис. 37).
Иногда в файлах бывают пустые строки, поэтому, прежде чем использовать переменную str, желательно обрезать пробелы по краям и проверить, не пуста ли она. На практике используется примерно такой код:
while(!FileIsEnding(h)){
string str=FileReadString(h); StringTrimLeft(str); StringTrimRight(str); if(str!=""){
Alert(str);
}
}
Теперь попробуйте снова запустить скрипт «Files», а после него сразу «Files2» – в окне сообщения будет только две строки («Строка-1» и «Строка-2»), это значит, что при открытии файл был перезаписан заново, то есть сначала очищен, а потом была выполнена запись.
Рис. 37. Результат работы скрипта «Files2»
Частая задача при работе с файлами в текстовом режиме – добавление строки в конец файла. Для этого надо открыть файл в режиме записи и чтения, установить файловый указатель в конец файла и выполнить запись. Перемещение файлового указателя выполняется функцией FileSeek(). Первым параметром в функцию передается хэндл файла.
Вторым параметром указывается смещение файлового указателя относительно позиции, указываемой третьим параметром. Это смещение указывается в байтах, если вы не знаете что это такое, не беспокойтесь, чуть позже, в разделе, посвященном побитовым операциям, это будет изучено. К тому же, практически не приходится применять никакое смещение кроме нуля, за редким исключением. Третьим параметром указывается позиция от который выполняется отсчет смещения. Может быть три варианта: SEEK_CUR – от текущей позиции, SEEK_SET – от начала файла (сразу после открытия указатель стоит в этой позиции), SEEK_END – от конца файла.
Создайте скрипт «Files3». Открываем файл в режиме записи и чтения, проверяем хэндл:
string fileName="file.txt";
int h=FileOpen(fileName,FILE_TXT|FILE_WRITE|FILE_READ); if(h==INVALID_HANDLE){
Print(«Ошибка открытия файла «,fileName); return;
}
Перемещаем указатель в конец файла:
FileSeek(h,0,SEEK_END);
Пишем две строки:
FileWrite(h,"Еще одна строка-1"); FileWrite(h,"Еще одна строка-2");
Закрываем файл:
FileClose(h);
После запуска скрипта открываем файл «file.txt» в редакторе. В файле должно быть четыре строки
(рис. 38):
Рис. 38. Файл с добавленными строками
Пока что мы сами создавали файлы, сами писали и читали их. В этом случае файлы сохранялись в кодировке UTF. Если же вдруг придется читать файл, сохраненный в кодировке ANSI, могут возникнуть сложности, вместо привычного текста будет набор странных знаков (рис. 39).
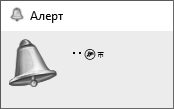
Рис. 39. Результат чтения файла ANSI в режиме UTF.
Чтобы прочитать такой файл правильно, необходимо при его открытии добавить еще один флаг –
FILE_ANSI:
h=FileOpen(fileName,FILE_TXT|FILE_READ|FILE_ANSI);
После этого файл будет читаться правильно. Также надо помнить об этом флаге и при создании файла, если его планируется читать в режиме ANSI.
Файлы *.csv, это своего рода таблицы, поля которых разделены каким-то знаком, чаще всего точкой с запятой или знаком табуляции. Эти файлы можно читать точно так же, как текстовые файлы, и после прочтения одной строки, разбивать ее при помощи функции StringSplit(). Но есть и специальные средства для их чтения. Все делается точно так же, как с текстовыми файлами только вместо флага FILE_TXT указывается флаг FILE_CSV. В этом режиме в функцию FileOpen() можно передать третий параметр – разделитель. По умолчанию в качестве разделителя используется знак табуляции, но все же точка с запятой используется чаще, поэтому укажем ее.
Третий параметр можно указать двумя способами: строкой в двойных кавычках, и числовым кодом – тот же символ, но в одинарных кавычках.
Создаем скрипт «FileCSV» и пишем код в нем. Открываем файл:
string fileName="file.csv";
int h=FileOpen(fileName,FILE_CSV|FILE_WRITE,";"); if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
Запись выполняется тоже функцией FileWrite(), но теперь она используется немного по-другому. Если при записи текстового файла в функцию передавалась одна строка, теперь можно передать несколько, в строке файла они будут представлять собой разные поля, то есть будут отделены друг от друга разделителем, указанным при открытии файла. Запишем две строки по три поля в каждой и закроем файл:
FileWrite(h,"Строка-1-1","Строка-1-2","Строка-1-3");
FileWrite(h,"Строка-2-1","Строка-2-2","Строка-2-3"); FileClose(h);
После выполнения скрипта в папке «Files» появится новый файл, открываем его в редакторе (рис. 40).
Рис. 40. Файл CSV в редакторе
Чтение CSV файла выполняется примерно так же, как текстового, но есть одно существенное отличие. Один вызов функции FileReadString() читает не одну строку, а одно поле, то есть для данного примера потребуется не два вызова функции, а шесть. Для того чтобы можно было отделить поля одной строки от полей другой строки, существует функция FileIsLineEnding (). Выполним чтение файла. Код пишем в файле «FileCSV2». Открытие для чтения:
string fileName="file.csv";
int h=FileOpen(fileName,FILE_CSV|FILE_READ,";"); if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
В цикле читаем файл, все прочитанные поля собираем в одну переменную. Когда функция
FileIsLineEnding () возвращает true, то выводим получившеюся строку, а переменную очищаем:
string line="";
while(!FileIsEnding(h) && !IsStopped()){ string str=FileReadString(h); StringTrimLeft(str); StringTrimRight(str);
if(str!=""){ line=line+str+"/";
}
if(FileIsLineEnding(h)){
Alert(line); line="";
}
}
Не забываем закрывать файл:
FileClose(h);
Запускаем скрипт и получаем две строки с полями разделенными знаком «/» (рис. 41).
Рис. 41. Результат чтения файла»file.csv» – две строки по три поля
При работе с бинарными файлами вместо флагов FILE_TXT и FILE_CSV используется флаг FILE_BIN, а для записи и чтения существует огромный арсенал функций. Есть несколько однотипных функций записи для различных типов переменных: FileWriteInteger(), FileWriteLong() и т.п. Существуют аналогичные функции для записи: FileReadInteger(), FileReadLong() и т.п. Еще существуют функции для записи и чтения массивов: FileWriteArray() и FileReadArray() – эти функции работают со всеми типами данных, кроме строковых.
В начало бинарного файла обычно принято записывать информацию о данных, располагающихся в файле, а уже потом записывать сами данные. Так и сделаем, сначала сохраним переменную int с размером массива, а следом массив double. Пишем код в файле «FileArray». Открываем файл:
string fileName="file.bin";
int h=FileOpen(fileName,FILE_BIN|FILE_WRITE); if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
Объявляем массив и заполняем его:
double a[]; ArrayResize(a,5); for(int i=0;i<5;i++){
a[i]=i;
}
В функцию FileWriteInteger() первым параметром передается хэндл файла, вторым параметром – значение, а третьим – размер переменной. Для переменной int это константа INT_VAL, она используется по умолчанию и ее можно не передавать. Сохраняем размер массива:
FileWriteInteger(h,ArraySize(a));
Сохраняем массив:
FileWriteArray(h,a);
Таким образом можно сохранить в файл любое количество переменных и массивов. Закрываем файл:
FileClose(h);
После запуска скрипта в навигаторе редактора не получится увидеть созданный файл, не отображаются файлы *.bin, в этом и нет необходимости, смотреть его нет смысла.
Напишем скрипт для чтения бинарного файла, имя скрипта «FileArray2». Открываем файл:
string fileName="file.bin";
int h=FileOpen(fileName,FILE_BIN|FILE_READ); if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
Объявляем массив, читаем его размер и изменяем размер массива:
double a[];
int size=FileReadInteger(h); ArrayResize(a,size);
Читаем массив, закрываем файл и делаем вывод:
FileReadArray(h,a);
FileClose(h);
ArrayPrint(a);
Результат: «0.00000 1.00000 2.00000 3.00000 4.00000».
Иногда при работе с бинарными файлами бывает нужно узнать позицию файлового указателя, чтобы потом вернуться к ней, для этого применяется функция FileTell().
Существует еще несколько функций для работы с файлами, которые могут пригодиться, но они очень просты, пока будет достаточно того, что вы будете о них знать. Если в них возникнет необходимость, сможете самостоятельно разобраться с ними по справочному руководству. Это функции: FileCopy() – создание копии файла, FileDelete() – удаление файла, FileMove() – перемещение файла. Есть функции по работе с папками: FolderCreate() – создание папки, FolderDelete() – удаление папки (папка должна быть пустой), FolderClean() – удаление всех файлов из папки.
Пока что мы работали с файлами, располагающимися в папке данных терминала. Для того, чтобы работать с файлами в общей папке терминала, при открытии файл необходимо указать флаг FILE_COMMOM. Создадим файл в общей папке. Для этого примера создайте скрипт «FileCommon». Пишем такой же код, как в скрипте «FileWrite», но изменяем имя файла и добавляем флаг:
string fileName="file_common.txt";
int h=FileOpen(fileName,FILE_TXT|FILE_WRITE|FILE_COMMON); if(h==INVALID_HANDLE){
Print("Ошибка открытия файла ",fileName); return;
}
FileWrite(h,"Строка-1"); FileWrite(h,"Строка-2"); FileClose(h);
После запуска этого скрипта новый файл можно будет обнаружить в общей папке данных.
Четвертый параметр функции FileOpen() – кодовая страница. Скорее всего, этот параметр вам никогда не придется менять. Если вдруг при чтении какого-то файла возникнут сложности, никак не будет получаться получить читаемый текст, при этом не будут помогать флаги FILE_ANSI и FILE_UNICODE, вот тогда, может быть, придется поэкспериментировать с этим параметром. Список возможных значений этого параметра можно посмотреть в справочном руководстве по языку MQL5.
Нужно понимать одну важную особенность работы с файлами. Можно сколько угодно долго и много писать в файл, но фактически сохранение данных на диск произойдет только при закрытии файла. То есть, если произойдет внезапное отключение электропитания компьютера, то данные не сохранятся. Для того чтобы гарантировать сохранение данных, есть специальная функция FileFlush(). Эта функции выполняет принудительных сброс данных на диск без закрытия файла.
Если работа с фалом выполняется по принципу однократного открытия файла на запуске программы и закрытия файла на завершении ее работы, то каждый раз, когда выполнена запись данных в файл, следует вызвать функцию FileFlush(). В функцию передается один параметр – хэндл файла. Что интересно, при аварийном завершении работы терминала через диспетчер задач Windows, операционная система сама успевает выполнить сброс данных в файл даже без его закрытия. Тем не менее, не стоит игнорировать все методы, повышающие надежность функционирования создаваемой программы, и следует всегда применять их.
Особенности тестера
Необходимо знать некоторые особенности функционирования тестера и терминала, касающиеся работы с файлами. Если эксперт работает с файлом, расположенным в общей папке, то он работает с одним и тем же файлом, как при работе на счете, так и при работе в тестере. Нужно иметь это в виду, что бы при тестировании не испортить файл, который может быть нужен эксперту, работающему на счете.
При использовании общей папки данных, рекомендуется использовать разные имена файлов для экспертов, работающих на счете, и для экспертов, работающих в тестере. Определить, что эксперт работает в тестере, можно при помощи функции MQLInfoInteger() с параметром MQL_TESTER:
bool tester=MQLInfoInteger(MQL_TESTER);
При выполнении оптимизации тестер распределяет работу равномерно по всем ядрам компьютера создает агенты тестирования и отправляет им копии эксперта. При этом может получиться так, что несколько экспертов из разных агентов одновременно попытаются открыть файл, разумеется, открыть файл получится только у одного эксперта, а у других экспертов произойдет сбой. Значит, необходимо избегать такой работы с файлами. Но, при крайней необходимости, можно открыть файл, выполнить запись в него или произвести чтение и сразу закрыть. Таким образом, вероятность безошибочной работы эксперта возрастет. К тому же, необходимо обеспечить выполнение повторной попытки работы с файлом после ошибки.
Кроме распределения оптимизации по ядрам одного компьютера, тестер обеспечивает возможность распределения оптимизации по локальной сети (при соответствующей настройке терминала), а также по сети созданной компанией MetaQuotes – по так называемому облаку (за оплату). Разумеется, файл, расположенный в общей папке данных, не будет доступен экспертам из агентов, расположенных на других компьютерах сети или облака.
Если файл находится в папке данных терминала, он будет доступен эксперту только при работе на счете. Для того чтобы файл был доступен эксперту при тестировании, в эксперте необходимо указать соответствующее свойство, тогда, при передаче задания агенту, вместе с файлом эксперта будет передаваться и этот файл. Свойство нужно указывать для каждого файла, который нужен эксперту:
#property tester_file "file1.txt" #property tester_file "file2.txt"
Эти файлы получится использовать только для чтения. Сохранять данные в файл из папки данных при тестировании нет смысла, файл не будет передан на локальный компьютер. Для передачи данных от удаленных агентов на локальный компьютер используются так называемые фреймы. Данная тема является довольно сложной и мало востребованной, поэтому не будет здесь рассматриваться. К тому же, на сайте mql5.com есть подробные статьи по этой теме. В справочном руководстве по MQL5 работа с фреймами описана в разделе «Работа с результатами оптимизации».
Получение списка файлов
Иногда неизвестны точные имена всех фалов, расположенных в какой-то папке, но их нужно обработать все, или перебрать, чтобы найти нужный файл. На этот случай в языке MQL5 существуют функции: FileFindFirst(), FileFindNext() и FileFindClose().
Получим список всех файлов из папки «Files». Код располагается в скрипте «FileFind». Сначала вызывается функция FileFindFirst(). Первым параметром в функцию передается фильтр поиска. Самый простейший фильтр, это знак звездочки «*», обозначающий любое количество любых знаков. Задавая фильтр можно производить поиск в подпапках, например, «Folder1\\*» – все файлы из папки Folder1. Можно выбирать файлы с заданным расширением: «*.txt». Вместо обратного слеша в фильтре допустимо использование прямого слеша: «Folder1/*». Вторым параметром по ссылке передается строковая переменная для имени файла. Третий параметр – для флага FILE_COMMON. Сама функция возвращает хэндл поиска, который используется для продолжения поиска функцией FileFindNext(). Функция FileFindNext() возвращает true/false в зависимости от того, найден ли следующий файл или нет, на основании этого значения принимается решение о продолжении поиска. По окончанию поиска желательно вызвать функцию FileFindClose(), на сам поиск она не влияет, но освобождает системные ресурсы:
string filter="*"; string fileName="";
long h=FileFindFirst(filter,fileName); if(h!=INVALID_HANDLE){
do{
Alert(fileName," ",FileIsExist(fileName));
}
while(FileFindNext(h,fileName)); FileFindClose(h);
}
В результате такого поиска будут найдены не только файлы, но и папки. Для того что бы отличить файл от папки, используется функция FileIsExist(). У этой функции один параметр – имя файла или папки. Если функции передано имя файла, она возвращает true, если папка – false.
Настоятельно рекомендуется самостоятельно ознакомиться с разделом справки, касающимся работы с файлами. Возможно, найдете в нем что-то интересное для себя, например функцию FileSelectDialog(), обеспечивающую использование стандартного диалога открытия и сохранения файла. Также могут быть интересны функции FileLoad() и FileSave(), обеспечивающие быструю работу с бинарными файлами. А может быть, пригодится возможность получения файловых атрибутов (даты создания, последнего изменения и т.п.), для этого используется функция FileGetInteger().
Побитовые операции
На компьютере, на самом глубоком его уровне, вся информация (данные) представлена в виде последовательности нулей и единиц. Одно место в этой последовательности, которое может принимать значение 0 или 1, называется битом. Последовательность из 8-м битов называется байтом. Один байт может находиться в одном из 256-и состояний, то есть может представлять собой число от 0 до 255 (или от -127 до 128, если условиться, что половина значений больше нуля, а другая половина – меньше нуля).
В известной и привычной всем десятичной системе счисления одно место в ряду данных может занимать состояние от 0 до 9. Первое место справа показывает количество единиц в числе. Следующее место (по направлению справа налево) показывает количество десяток в числе и т.д. Например, число 256 в десятичной системе означает, что это сумма из двух сотен, пяти десятков и шести единиц. Тот же принцип используется и в двоичной системе исчисления (в системе исчисления, в которой одно место может принимать значение 1 или 0).
Значит, одно место показывает количество единиц, второе количество двоек, третье – четверок и т.д. В десятичной системе для каждого места используется степень числа 10: 1, 10, 100, 1000 и т.д. А в двоичной – степень числа 2: 1, 2, 4, 8, 16, 32, 64, 128 и т.д. Все ряды начинаются с 1, потому что любое число в степени 0 равно 1. Число, которое возводится в степень, называется основанием системы счисления. Если продолжить степенной ряд двойки, то дальше будет число 256, потом 512 и 1024. Число 1024 это 2 в 10-й степени, такой объем данных называется килобайтом. 2 в 20-й степени равно 1 048 576 – называется мегабайтом. 2 в 30-й в степени равно 1 073 741 824 – называется гигабайтом. 2 в 40-й в степени равно 1 099 511 627 776 – называется терабайтом и т.д.
Переведем двоичное число в десятичное. Допустим, есть двоичное число 10011010. Крайний правый знак – количество единиц равно 0, значит, записываем 0. Следующий знак (количество двоек) равен 1, значит, прибавляем 2. Третий знак (количество четверок) равно 0 – ничего не прибавляем или прибавляем 0. Четвертый знак (количество восьмерок) – 1, прибавляем 8. В итого получается такое выражение: 0*1 + 1*2 + 0*4 + 1*8 + 1*16 + 0*32 + 0*64 + 1*128, что равно 154.
Чтобы перевести десятичное число в двоичное, его надо последовательно делить на 2 и записывать остаток. Переведем число 154 назад в двоичное число. 154 деленное на 2 равно 77, остаток 0. 77 деленное на 2 равно 38 с остатком 1 и т.д. Получаем два ряда чисел:
| Число: | 154 | 77 | 38 | 19 | 9 | 4 | 2 | 1 | 0 |
| Остаток: | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
Первый ряд – результат последовательного деления на 2 с отбрасывание дробной части, второй ряд – остаток от деления на 1). Остается записать ряд остатков в обратном порядке, чтобы старшие разряды были слева: 10011010.
Побитовые операции представляют собой манипулирование данными переменных на уровне нулей и единиц (битов). Используя побитовые операции можно перемещать данные в переменной и некоторым образом объединять несколько переменных в одну и пр. С одной побитовой операцией мы уже имели дело – с побитовым «или», с нее и начнем.
Побитовое «или» выполняется над двумя числами. Выполняется последовательная проверка значений в одном и том же разряде, если хотя бы у одного числа в этом разряде стоит 1, то в итоговом значении будет 1. Например, одно число представлено как «00101010», а второе «00010101», в итоге получаем «00111111». Проверим это на практике.
Создайте папку «010 Bitwise», а в ней скрипт с именем «Bitwise». Сначала напишем функции для перевода двоичных чисел в десятичные и десятичных в двоичные. Функция для перевода двоичных чисел десятичные числа будет называться BinToDec(), в нее будет передаваться строка с набором нулей и единиц, а возвращать функция будет переменную типа uchar. Переменная uchar – это беззнаковая переменная размер 1 байт, то есть 8 бит, – этого достаточно для учебных экспериментов.
uchar BinToDec(string bin){ uchar r=0;
uchar p=1;
for(int i=StringLen(bin)-1;i>=0;i--){ if(StringSubstr(bin,i,1)!="0"){
r+=p;
}
p*=2;
}
return(r);
}
Проверим ее:
Alert("1: ",BinToDec("10011010"));
Результат: «1: 154».
Функция для перевода десятичных чисел в двоичные числа будет называться DecToBin(), в нее будет передаваться переменная uchar, а возвращать функция будет переменную string:
string DecToBin(uchar bin){ string r="";
while(bin!=0){ r=string(bin%2)+r; bin/=2;
}
while(StringLen(r)<8){ r="0"+r;
}
return(r);
}
В функции два цикла while(). Обратите внимание на первый цикл, поскольку переменная bin имеет целочисленный тип, то при ее делении на 2 дробная часть отбрасывается, например, если 3 поделить на 2, получится 1. Во втором цикле выполняется дополнение результата нулями, что бы длина результата всегда соответствовала байту.
Проверим функцию:
Alert("2: ",DecToBin(154));
Результат: «2: 10011010».
Теперь поэкспериментирует с побитовым «или». Объявим две переменных uchar, и, используя функцию BinToDec(), присвоим им значения «00101010» и «00010101»:
uchar v1=BinToDec("00101010"); uchar v2=BinToDec("00010101");
Произведем над ними логическое «или», результат присвоим третей переменной uchar, которую преобразуем в двоичное число, чтобы увидеть его в виде строки:
uchar v1=BinToDec("00101010"); uchar v2=BinToDec("00010101"); uchar v3=(v1|v2);
Alert("3: ",DecToBin(v3));
Результат: «3: 00111111» – что и ожидалось.
Немного изменим задачу, сделаем так, что бы оба числа в одном и том же разряде имели по единице:
v1=BinToDec("10101010"); v2=BinToDec("10010101");
v3=(v1|v2);
Alert("4: ",DecToBin(v3));
Результат: «4: 10111111». Получилось, что в том разряде, в котором обе переменные имеют по единице, итоговая переменная тоже имеет единицу.
Еще существует побитовая операция «исключающее или», при выполнении этой операции итоговая единица по разряду получится только в том случае, если единица в этом разряде есть только у одного числа. Операция «исключающее или» выполняется знаком «^». Проведем
«исключающее или» над теми же исходными данными:
v3=(v1^v2);
Alert("5: ",DecToBin(v3));
Результат: «5: 00111111». Как видим, две единицы дали ноль.
Побитовая операция «и» обозначается знаком «&». При выполнении этой операции в одном разряде итогового значения получается единица, только если в этом разряде у всех исходных значений есть единица. Проведем эксперимент с теми же данными:
v3=v1&v2;
Alert("6: ",DecToBin(v3));
Результат: «6: 10000000».
Побитовая операция «Дополнение до единицы» выполняется знаком «~», она выполняется над одним числом. В результате ее выполнения все нули меняются на единицы, а единицы на нули.
v3=~v1;
Alert("7: ",DecToBin(v3));
Результат: «7: 01010101».
Смысл названия это операции раскрывается при ее выполнении над знаковыми переменными. Сумма исходного значения и дополненного до единицы будет равна -1:
char ch1=25; char ch2=~ch1;
Alert("8: ",ch2);
Результат: «8: -26».
Побитовый сдвиг влево выполняется знаками «<<», производится над одним числом. Очень наглядным будет выполнение побитового сдвига влево над переменной со значением 1. Такое число имеет единицу в младшем разряде, и эта единица будет перемещаться в старшие разряды, а значение числа будет умножаться на 2:
v1=1;
string r="";
for(int i=0;i<9;i++){ r=r+(string)v1+" "; v1=v1<<1;
}
Alert("8: ",r);
Результат: «8: 1 2 4 8 16 32 64 128 0». Последнее значение – 0, потому что единица ушла в несуществующий разряд.
Побитовый сдвиг вправо выполняется знаками «>>», тоже производится над одним числом. При его выполнении все разряды сдвигаются вправо.
v1=128; r="";
for(int i=0;i<9;i++){ r=r+(string)v1+" "; v1=v1>>1;
}
Alert("10: ",r);
Результат: «10: 128 64 32 16 8 4 2 1 0».
Пока что в учебных примерах мы использовали двоичную запись чисел, это было очень наглядно и удобно, но данные имели размер в один байт. На практике приходится иметь дело с переменными типа int, имеющими размер 4 байта и long, имеющими размер 8 байтов. Если записать переменную int нулями и единицами получится ряд из 32-х знаков, а если long, то 64 знака. Такая запись будет громоздкой. Более удобно использовать шестнадцатеричную запись числа. В таком представлении одно место числа может занимать 16 состояний: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, С, D, E, F. Таким образом, двумя знаками можно записать один байт. Чтобы отличить шестнадцатеричную форму записи числа, она начинается со знаков 0x. Переменная uchar, во всех разрядах заполненная единицей запишется так: 0xFF:
v1=0xFF;
Alert("11:",DecToBin(v1));
Результат: «11:11111111».
Переменная int запишется так: 0xFFFFFFFF, а long так: 0xFFFFFFFFFFFFFFFF.
Если в какой-то переменной надо узнать о наличие единицы в каком-то разряде, надо иметь эталонное число, в котором только этот разряд имеет единицу, а остальные нули, и выполнить над ними побитовое «и». Допустим, есть переменная uchar, надо определить наличие в ней единицы в третьем разряде, в седьмом и в восьмом. В двоичном виде число выглядит так: 11000100. Разделяем его на части по 4-ре бита: 1100 0100. Каждая такая часть представляет собой один знак шестнадцатеричного числа, и ее легко перевести в десятичную и в шестнадцатеричную форму. Часть справа, это 4 в десятичной форме, и так же в шестнадцатеричной. Часть слева, это 12 в десятичной форме, а в шестнадцатеричной – С. Таким образом, получаем 0xC4. Допустим, есть переменная с каким-то числом, например с числом 215, проверим, заняты ли в нем третий, седьмой и восьмой разряды. Выполняется это при помощи операции «&»:
v1=215;
v3=v1&0xC4;
После этого, если нужные разряды заняты, в переменной v3 должно остаться число 0xC4, проверим, так ли это:
Alert("12: ",(v3==0xC4));
Результат: «12: true». Значит, все требуемые разряды заняты.
Наконец, решим пару практических задач: разложение значения цвета на компоненты RGB и формирование значения цвета из компонентов RGB. В папке «010 Bitwise» создайте скрипт с именем «RGB», следующий код будем писать в нем. Значит, один компонент цвета изменяется от 0 до 255 (включительно), то есть он представляет собой два байта (16 бит). Компонент R занимает первые два байта, компонент G третий и четвертый байты, компонент B – пятый и шестой байты. Чтобы получить значение компонента R необходимо обнулить все байты, кроме первых двух. Это можно выполнить, произведя побитовое «&» со значением 0x000000FF:
color col=clrBisque; int R=col&0x000000FF;
Для получения компонента G, надо все биты в переменой сдвинуть на восемь позиций вправо и также обнулить все байты кроме первых двух.
int G=(col>>8)&0x000000FF;
Для получения компонента B надо пятый и шестой байты переместить на первую и вторую позицию, то есть произвести сдвиг вправо на четыре байта, что составляет 16 бит:
int B=(col>>16)&0x000000FF;
Для проверки результата воспользуемся функцией ColorToString(). Функция преобразует числовое значение цвета в строку, первым параметром в функцию передается цвет, вторым параметром типа bool определяет режим работы функции. При значении true функция возвращает название цвета, если он является стандартным веб-цветом или значения компонентов RGB. При значении false в любом случае возвращаются компоненты RGB. Делаем вывод:
Alert("R=",R,", G=",G,", B=",B," ColorToString=",ColorToString(col,false));
Результат: «R=255, G=228, B=196 ColorToString=255,228,196».
Проведем обратное преобразование. Для этого для компонента G надо произвести сдвиг влево на 8 бит, для компонента B – на 16 бит и произвести побитовое «или» над всеми компонентами:
color col2=color(R|(G<<8)|(B<<16));
Вывод:
Alert("col2=",ColorToString(col2,true));
Результат: «col2=clrBisque».
Данную задачу можно решить и при помощи обычной арифметики. Берм остаток от деления на 256 – получаем компонент R. Выполняем деление на 256 и берем остаток от деления на 256 – получаем компонент G. Выполняем деление на 65536 (это 256 умноженное на 256) и берем остаток от деления на 256 – получаем компонент B:
R=col%256;
G=(col/256)%256;
B=(col/(65536))%256;
Alert("R=",R,", G=",G,", B=",B);
Результат: «R=255, G=228, B=196».
Наконец, перевод из RGB в цвет при помощи обычной арифметики: col2=color(R+G*256+B*65536); Alert("col2=",ColorToString(col2,true));
Результат: «col2=clrBisque».
Структуры
Один бар на графике описывается несколькими значениями: ценой открытия open, закрытия close, максимальной ценой high, минимальной low, временем открытия, объемом. Причем объема два: тиковый и реальный. К тому же на графике нарисован не один бар, а тысячи. Значит, для данных одного графика необходимо 7 массивов. Допустим, открылся новый бар, все 7 массивов надо увеличить… Короче, необходимо выполнить огромный объем работы, написать много кода.
Конечно, это не наша проблема, а разработчиков терминала, но и при разработке индикаторов, экспертов иногда возникает подобная задача.
С многомерными массивами вы знакомы, отчасти это выход из положения. Но как быть, если данные разнотипные? Как быть, если для описания одного бара нужно несколько переменных типа double, несколько типа long и одна типа datetime. Решение есть, в языке MQL5 можно создавать структуры. Создание (описание) структуры начинается со слова struct, затем следует имя этой структуры и в фигурных скобках объявляются все переменные, входящие в ее состав.
Для экспериментов со структурами создайте папку «011 Struct», а в ней скрипт «Struct». Создаем структуру (пишем код в верхней части файла, после свойств):
struct SMyStruct{ double open; double high; double low; double close; long volume; datetime time;
};
После закрывающей фигурной скобки обязательно должна стоять точка с запятой!
После описания структуры ее имя «SMyStruct» можно использовать точно так же, как тип стандартной переменной int, double и т.п. То есть, можно объявить переменную или массив данного типа.
Объявим переменную:
SMyStruct a;
Теперь пишем имя этой переменной и ставим точку. После постановки точки откроется список полей этой структуры (рис. 42).
Рис. 42. Список полей структуры
Выбираем из списка нужное поле, в результате образуется составное имя переменной, которое используется для присвоения значения полю или для его получения:
a.close=1.2345; a.open=1.6789;
Alert("1: ",a.open," ",a.close);
Результат: «1: 1.6789 1.2345».
Структуру можно инициализировать при объявлении:
SMyStruct b={1.1,1.6,0.9,1.4,555,D'2020.01.01 00:00'};
Alert("2: ",b.open," ",b.high," ",b.low," ",b.close," ",b.volume," ",b.time);
Результат: «2: 1.1 1.6 0.9 1.4 555 2020.01.01 00:00:00»
Для экспериментов с массивами создадим более простую структуру:
struct SMyStruct2{ int iv;
double dv;
};
Массив структур можно объявить как статический, так и динамический. Статический:
SMyStruct2 c[3];
Динамический:
SMyStruct2 d[];
Динамический массив можно масштабировать функцией ArrayResize():
ArrayResize(d,3);
После объявления динамического массива, нужно установить его размер:
SMyStruct2 d[];
ArrayResize(d,3);
Как и с обычными массивами, размер массива структур можно определить функцией ArraySize() и пройтись по нему в цикле:
int size=ArraySize(e); string str="";
for(int i=0;i<size;i++){
str=str+(string)e[i].iv+" "+(string)e[i].dv+" ";
}
Alert("3: ",str);
Результат: «3: 1 1.1 2 2.2 3 3.3».
Особенность и одна из сложностей применения структур в том, что ее полям невозможно присвоить значения при описании структуры. Но есть выход из положения. Членами структуры могут быть не только переменные, но и функции, такие функция называются методами. Если имя метода совпадает с именем структуры, такой метод называется конструктором, он выполняется в момент инициализации структуры. Значит, в конструкторе присвоим всем полям начальные значения. Описание структуры:
struct SMyStruct3{ void SMyStruct3(){
iv=0; dv=0;
}
int iv; double dv;
};
А можно воспользоваться возможностями перегрузки и написать еще один конструктор с набором параметров:
struct SMyStruct3{ void SMyStruct3(){
iv=0; dv=0;
}
void SMyStruct3(int aiv,double adv){ iv=aiv;
dv=adv;
}
int iv; double dv;
};
Теперь, если объявить переменную типа SMyStruct3 обычным образом, сработает конструктор без параметров и всем полям будет присвоено по нулю:
SMyStruct3 f;
Alert("4: ",f.iv," ",f.dv);
Результат: «4: 0 0.0».
А можно при объявлении переменной указать начальные значения, тогда будет вызван конструктор с параметрами и поля структуры будут инициализированы значениями из этих параметров:
SMyStruct3 g(1,2.2); Alert("5: ",g.iv," ",g.dv);
Результат: «5: 1 2.2».
При объявлении массива из таких структур будет срабатывать конструктор без параметров. Другого способа инициализации такого массива нет. В случае необходимости, по массиву надо пройти в цикле и присвоить полям нужные значения.
С простыми структурами можно использовать операцию присвоения «=». Таким образом одной строчкой кода выполняется присвоения полям одной структур значений из всех полей другой структуры:
SMyStruct3 h(2,3.3);
SMyStruct3 i;
i=h;
Alert("6: ",i.iv," ",i.dv);
В последних версиях языка MQL5 такое присвоение работает даже со сложными структурами, включающими в себя строковые переменные и динамические массивы. Тем не менее, если вдруг на каком-то уровне сложности структур такое присвоение перестанет работать, надо будет писать свой метод присвоения. В следующем примере кода это метод set():
struct SMyStruct4{ string str; int ar[];
void set(SMyStruct4 & arg){ this.str=arg.str; ArrayResize(this.ar,ArraySize(arg.ar)); for(int i=ArraySize(arg.ar)-1;i>=0;i--){
this.ar[i]=arg.ar[i];
}
}
};
Чтобы одной структуре присвоить значения другой, надо будет вызвать метод set() и передать в него структуру, значения которой надо использовать:
SMyStruct4 j; j.str="строка"; ArrayResize(j.ar,2); j.ar[0]=10;
j.ar[1]=11;
SMyStruct4 k; k.set(j);
Alert("7: ",k.str," ",k.ar[0]," ",k.ar[1]);
В языке MQL5 можно решить данную задачу используя так называемую перегрузку операторов, в этом случае, не надо будет вызывать метод set(), а можно будет писать код так же, как с простыми структурами и обычными переменными:
k=j;
Но пока не будет углубляться в эту тему, ограничимся минимумом, которого и так вполне достаточно. Подробно перегрузка будет рассмотрена в разделе, посвященном Объектно Ориентированному Программированию (ООП).
Несмотря на то что структуры очень удобны, с ними есть некоторая сложность, при использовании массива структур, к ним невозможно применить стандартные функции сортировки, поиска максимума/минимума и пр. Все эти задачи надо будет решать написанием собственных функций.
В языке MQL5 существует несколько стандартных структур, с которыми вам обязательно придется иметь дело. Наиболее часто придется иметь дело со структурами MqlDateTime, MqlRates, MqlTick. Они будут рассмотрены в дальнейшем по мере необходимости. Однако, если интересно, можно ознакомиться с полным перечнем структур в разделе справки: Константы, перечисления и структуры – Структуры данных.
В функцию структуру можно передавать только по ссылке:
void fun1(SMyStruct2 & arg){ arg.dv=1.1;
arg.iv=2;
}
Вызов этой функции:
SMyStruct2 l; fun1(l);
Alert("8: ",l.dv," ",l.iv);
Результат: «8: 1.1 2».
В функцию можно передавать массив структур:
void fun2(SMyStruct2 & arg[]){ ArrayResize(arg,2); arg[0].dv=1.1;
arg[0].iv=1;
arg[1].dv=2.2;
arg[1].iv=2;
}
Вызов функции:
fun2(d);
Alert("9: ",d[0].dv," ",d[0].iv," ",d[1].dv," ",d[1].iv);
Результат: «9: 1.1 1 2.2 2».
Кроме того, сама функция может возвращать структуру, но только простую:
SMyStruct2 fun3(){ SMyStruct2 r; r.dv=3.3; r.iv=3; return(r);
}
Вызов функции:
l=fun3();
Alert("10: ",l.dv," ",l.iv);
Результат: «10: 3.3 3».
Все же лучше возвращать структуру из функции по ссылке.
Объединения
Объединение подобно структуре, но только поля структуры независимы и содержат в себе различные данные, а поля объединения начинаются в оперативной памяти с одной точки, в результате чего разные поля объединения содержат части одних и тех же данных. Для изучения объединений создайте в папке «011 Struct» скрипт с именем «Union». Что представляет собой объединение, можно понять на следующем примере. Описание объединения:
union UMyUnion{ int v1;
int v2;
};
В функции OnStrat() объявляем переменную, присваиваем значение одному полую, и это же значение оказывается в другом поле:
UMyUnion a; a.v1=12345;
Alert("1: ",a.v2); a.v1=67890;
Alert("2: ",a.v2);
Результат: «1: 12345» и «2: 67890».
Рассмотрим еще один пример:
union UMyUnion2{ uint v1; uchar v2[4];
};
В этой структуре размер массива v2 в байтах соответствует размеру переменной v1. Таким образом, присвоив переменой v1 значение, а потом, обращаясь к элементам поля v2, можно извлекать отдельные байты из переменной v1. Объявим переменную и присвоим ее полю типа uint значение «0x01020304» – в каждом из четырех байтов значения 1, 2, 3, 4:
UMyUnion2 b; b.v1=0x01020304;
Посмотрим, что находится в массиве v2:
Alert("3: ",b.v2[0]," ",b.v2[1]," ",b.v2[2]," ",b.v2[3]);
Результат: «3: 4 3 2 1».
Объединения и массивы объединений, как и структуры, можно передавать в функцию (только по ссылке), также и функция может возвращать объединение:
UMyUnion fun1(UMyUnion & a, UMyUnion & b[]){ ArrayResize(b,2);
b[0].v1=a.v1+1;
b[1].v1=a.v1+2;
return(a);
}
Вызов:
UMyUnion c[];
UMyUnion d=fun1(a,c);
Alert(d.v1," ",c[0].v1," ",c[1].v1);
Результат: «67890 67891 67892».
Шаблоны
Использование шаблонов позволяет писать универсальные функции для разного типа аргументов. Вспомним функции DecToBin() и BinToDec() из раздела про побитовые операции. Эти функции позволяют работать только с переменными типа char. Используя шаблоны, сделаем их универсальными. Создайте новую папку «012 Templates», а в ней скрипт «Templates».
Написание шаблона начинается с ключевого слова template, после которого в треугольных скобках <>, с использованием слова typename, перечисляются неопределенные типы. Поскольку у нас только один тип, начало шаблона будет выглядеть следующим образом:
template<typename T>
Если бы было два неопределенных типа, то шаблон выглядел бы так:
template<typename T1, typename T2>
Следом пишется функция, а везде где раньше указывался типа char, указывается тип «Т». Вместо
«Т» может быть любая другая буква или набор букв. Начнем с функции DecToBin():
template<typename T> string DecToBin(T bin){
string r=""; while(bin!=0){
r=string(bin%2)+r; bin/=2;
}
while(StringLen(r)<8*sizeof(T)){ r="0"+r;
}
return(r);
}
Заметьте отличия этой функции от функции из скрипта «010 Bitwise/Bitwise» – изменен тип аргумента на Т, а во втором цикле, при дополнении результата нулями используется функция sizeof() – эта функция возвращает размер переменой указанного типа в байтах. Размер в байтах умножается на 8, что бы получить биты.
Вызываем функцию из OnStart() и передаем в нее переменную uint с ее максимальным значением:
uint a=UINT_MAX;
string str=DecToBin(a); Alert("1: ",str);
Результат: «1: 11111111111111111111111111111111» – 32-е единицы.
Создание шаблона BinToDec() несколько проще, достаточно только заменить типы:
template<typename T>
T BinToDec(string bin){ T r=0;
T p=1;
for(int i=StringLen(bin)-1;i>=0;i--){ if(StringSubstr(bin,i,1)!="0"){
r+=p;
}
p*=2;
}
return(r);
}
Однако при вызове этой функции есть нюанс. Универсальный тип «T» не используется в параметрах функции, в этом случае, его надо указывать при вызове функции:
uint b=BinToDec<uint>(str); Alert("2: ",b);
Результат: «2: 4294967295» – значение UINT_MAX.
Для полного понимания шаблонов можно представить их работу так, как будто непосредственно перед компиляцией компилятор делает копию функции, но все неопределенные параметры заменяет на те, с которыми функция вызывается. С какими различными типами параметров шаблонная функция вызывается, столько различных копий функций и делается.
По шаблону можно написать не только функцию, но и структуру. Напишем структуры с тремя неопределенными типами:
template<typename T1,typename T2,typename T3> struct SA{
T1 a;
T2 b;
T3 c;
};
При объявлении переменной данного типа необходимо конкретизировать все неопределенные типы:
SA<int,double,bool>c; c.a=1;
c.b=2.2;
c.c=0;
Alert("3: ",c.a," ",c.b," ",c.c);
Результат: «3: 1 2.2 false» – видны типы переменных: int, double, bool. Выведем типы более наглядно, для этого используем функцию typename(): Alert(«4: «,typename(c.a),» «,typename(c.b),» «,typename(c.c)); Результат: «4: int double bool».
Можно совмещать шаблон и перегрузку. Напишем универсальную функцию для преобразования
числа в строку. Любая целочисленная переменная преобразуется при помощи функции IntegerToString(), а переменную double нужно вывести с заданной точность, равной количеству знаков после запятой у котировок. Значит, для целочисленных переменных пишем шаблонную функцию, и создаем еще одну функцию с таким же именем и конкретно указанным типом double:
template<typename T> string NumToStr(T a){
return(IntegerToString(a));
}
string NumToStr(double a){ return(DoubleToString(a,Digits()));
}
Результат: «5: 1 1.00000».
Также можно написать еще один вариант функции – для переменных bool.
Еще шаблон может быть перегружен по количеству параметров:
template<typename T> string fun(T a){
return "1";
}
template<typename T> string fun(T a, T b){
return "2";
}
Вызов в функции OnStart():
Alert("6: ",fun(1)," ",fun(1,1));
Результат: « 6: 1 2».
Обычно при создании индикаторов и советников потребности в шаблонах не возникает, но если вы захотите создать какую-нибудь универсальную библиотеку функций, они будут очень полезны.
Параметрическая макроподстановка
Ранее уже была рассмотрена возможность выполнения простых макроподстановок, но на этом их возможности не исчерпываются. В языке MQL5 есть возможность выполнения параметрических макроподстановок. Такие макроподстановки по своим возможностям чем-то подобны функциям – при вызове макроса в него передаются параметры.
При программировании экспертов очень часто приходится использовать функцию NormalizeDouble() для нормализации числа по количеству знаков, соответствующему количеству знаков после запятой у котировок. У функции очень длинное имя, да еще в нее надо передать два параметра: первый – нормализуемое число, второй – количество знаков у котировок, обычно для их определения количества знаков используется функция Digits(). В итоге получается довольно громоздкая конструкция:
Val=NormalizeDouble(Val,Digits());
Поэтому лучше написать свою функцию с коротким именем и без второго параметра:
double ND(double val){ return(NormalizeDouble(val,Digits()));
}
Использование такой функции значительно упрощает программирование:
Val=ND(Val);
Существует мнение, что вызов функции является более ресурсоемкой операцией, нежели выполнение кода на месте. Параметрический макрос позволяет заменить вызов функции кодом, исполняемым на месте, но с сохранением компактной записи, как при вызове функции. Напишем макрос, заменяющий приведенную выше функцию ND(). Создайте папку «013 Define», а в ней скрипт «Define». Создание параметрического макроса начинается с директивы #define, после нее идет пробел и имя макроса, после имени в круглых скобках через запятую перечисляются параметры (пока у нас будет один параметр), затем, после пробела пишется код, в котором должны фигурировать переменные из параметров:
#define ND(val) NormalizeDouble((val),Digits())
Теперь применяем это макрос:
double v=1.23456789; v=ND(v);
Alert("1: ",v);
Чтобы понять, как это работает, представьте код макроса:
NormalizeDouble((val),Digits())
Замените переменную val кодом, который располагается между круглых скобок макроса при его вызове, в нашем случае это переменная v. Получаем такой код:
NormalizeDouble((v),Digits())
Полученным кодом заменяем весь вызов макроса.
Обратите внимание, в макросе аргумент val заключен в круглые скобки. В данном случае скобки не нужны, тем не менее, рекомендуется всегда заключать аргументы макроса в скобки, не задумываясь, что позволит во многих случаях избежать неожиданного результата. Допустим, есть макрос, выполняющий умножение:
#define MULT(a,b) a*b
Используем его для умножения 2 на 2:
int r=MULT(2,2);
Alert("2: ",r);
Результат: «2: 4» – пока все правильно.
А теперь сделаем так, как многие привыкли делать с функциями – вычислим один из аргументов непосредственно при вызове макроса:
r=MULT(1+1,2);
Alert("3: ",r);
Результат: «3: 3».
Дело в том, что после выполнения замены, получилось выражение 1+1*2, а умножение имеет приоритет. Напишем такой же макрос, но со скобками у параметров:
#define MULT2(a,b) (a)*(b)
Вызов:
r=MULT2(1+1,2);
Alert("4: ",r);
Результат: «4: 4».
В макросах могут использоваться знаки «#» и «##». Рассмотрим простейший макрос с одним аргументом:
#define ARG(a) a
Макрос совершенно ничего не делает – что получит, то и отдаст. Однако если при вызове макроса его аргументом будет выражение, оно будет вычислено:
Alert("5: ",ARG(1+2));
Результат: «5: 3».
Если в макросе, при выводе аргумента перед ним поставить знак «#», он будет заключен в кавычки и выведен как строка:
#define ARG2(a) #a Alert("6: ",ARG2(1+2));
Результат: «6: 1+2».
Знаки «##» используются для соединения двух лексем, что позволяет формировать в макросе имя вызываемой функции, переменной и т.п. Разумеется, только на этапе компиляции, но не в процессе работы программы. В следующий макрос первым аргументом передается префикс функции, а вторым – обрабатываемое значение:
#define NUMTOS(a,b) a##ToString(b)
Это макрос позволяет вызвать функцию DoubleToString() или IntegerTostring():
Alert("7: ",NUMTOS("Double",1.23)," ",NUMTOS("Integer",2));
Результат: «7: 1.23000000 2».
Макросы по размеру могут быт не только в одну строку, но и довольно значительного размера. Если код макроса не заканчивается в конце строки, на ее конце ставится знак «\», а код продолжается на следующей строке и т.д. Следующий пример масштабирует массив и инициализирует его возрастающими значениями от указанного значения:
#define INITARR(ar,size,start) ArrayResize(ar,size); \ for(int i=0;i<size;i++){ \
ar[i]=start+i; \
}
Использование макроса:
int a[];
INITARR(a,5,3);
ArrayPrint(a);
Результат: «3 4 5 6 7».
На этом все возможности макроподстановок еще не исчерпываются. Кроме директивы #define, еще существует директива #undef, что позволяет произвести замены только в части файла, оставшуюся часть оставить как есть или переопределить макрос. Еще существуют директивы условной компиляции: #ifdef, #ifndef, #else, #endif, позволяющие выбирать различные варианты кода при компиляции в зависимости от определенных параметров. Но эти возможности языка на практике почти не востребованы, Если вдруг они вам понадобятся, разберитесь с ними по справочному руководству.
Кроме того, мнение о том, что макросы работают быстрее функций, является мифом. Может быть, когда-то это было истиной, но в настоящее время информационные технологии сделали значительный шаг вперед. Современные компиляторы не просто выполнят компиляцию, а очень серьезно оптимизируют код. Сравнительные тесты быстродействия идентичных макросов и функций показывают равные результаты по времени их выполнения. Код, написанный с использованием макросов, значительно тяжелее в прочтении и понимании, в отличие от кода с использованием функций. Так что, если задача может быть решена с использованием функции, надо использовать функцию, а макросы оставить только на тот случай, когда без них не обойтись никак.
Использования параметрического макроса целесообразно совместно с предопределенными макросами. В языке MQL5 имеется несколько предопределенных макросов, обеспечивающих важной для отладки информацией: FUNCTION – имя функции, LINE – номер строки,
FILE – имя файла. Есть и другие, ознакомьтесь с ними в справочном руководстве: Константы, перечисления и структуры – Именованные константы – Предопределенные макроподстановки.
Конечно, при выводе данных функцией Print(), можно каждый раз передавать в нее необходимые макроподстановки:
Print( FILE ," ", FUNCTION ," ", LINE ," сообщение об ошибке...");
Результат: «сообщение об ошибке…». А можно один раз написать макрос:
#define LOG(str) Print( FILE ," ", FUNCTION ," ", LINE ," ",(str));
Затем, вместо функции Print() использовать его. Таким образом, при вызове макроса достаточно писать только сообщение:
LOG("сообщение об ошибке2...");
Все остальные данные будут добавлены автоматически.
Результат работы макроса: «Define.mq5 OnStart 60 сообщение об ошибке2…».
Включаемые файлы, библиотеки
Код любой программы, написанной на языке MQL5, может располагаться в нескольких файлах. К основному файлы программы можно подключать так называемые включаемые файлы, они имеют расширение *.mqh. Также возможно использование библиотек, это откомпилированные файлы с расширением *.mq5.
Включаемые файлы могут располагаться непосредственно в папке «MQL5/Include», а могут располагаться в подпапках. Желательно для поддержания порядка все свои файлы располагать в одной папке. Используя панель «Навигатор» редактора создайте в папке «MQL5/Include» новую папку с именем «Изучение MQL5». Щелкните правой кнопкой на имени новой папки и выберите команду «Новый файл». В открывшемся окне выберите вариант «Включаемый файл (*.mqh)», нажмите кнопку «Далее», в следующем окне введите имя «Test» и нажмите кнопку «Готово».
В открывшемся файле удалите все комментарии, расположенные ниже строки «#property link» и добавьте в файл простую функцию:
void fun(){
Alert("Это включаемый файл Test.mqh");
}
После написания функции выполните компиляцию, в результате файл *.ex5 не будет создан, но это проверит код на ошибки.
В папке для учебных скриптов («MQL5/Scripts/Изучение MQL5») создайте папку «014 Include», а в ней скрипт «Include». Подключим к скрипту только что созданный файл (пишем код сразу после строки «#property link»):
#include <Изучение MQL5/Test.mqh>
После этого можно воспользоваться функцией из подключенного файла. Код в функции OnStart():
fun();
Запускаем скрипт и получаем сообщение: «Это включаемый файл Test.mqh».
Включаемые файлы могут располагаться в той же папке, что и файл, к которому выполняется подключение (непосредственно в той же папке или в подпапке). К сожалению, при помощи мастера MQL невозможно создать включаемый файл в какой-либо папке, кроме «MQL5/Include» (и ее подпапок). Поэтому придется сделать это через файловую систему Windows. Щелкните правой кнопкой на имени файла «Test.mqh», расположенного в папке «Include/Изучение MQL5» и выберите команду «Открыть папку». В открывшейся папке скопируйте файл «Test.mqh», откройте папку «014 Include» и вставьте в нее файл. Откройте вставленный файл в ректоре и исправьте функцию (измените имя функции и текст сообщения):
void fun2(){
Alert("Это второй включаемый файл Test.mqh");
}
Для подключения файлов, расположенных в той же папке, что и основной файл, имя к файлу записывается в двойных кавычках:
#include "Test.mqh"
Вызываем функцию из этого файла:
fun2();
Теперь при исполнении скрипта открывается два сообщения: «Это включаемый файл Test.mqh» и «Это второй включаемый файл Test.mqh».
Подключение включаемого файла по своему смыслу подобно тому, как если бы просто скопировать весь код из файла и вставить в том месте, где он подключается. Отличие только в том, что это «копирование» можно сделать один раз. Если какой-то файл уже подключен, то вторая команда для его же подключения будет проигнорирована. Это удобно на тот случай, когда функции одного включаемого файла пользуются функциями другого включаемого файла, а главный файл пользуется функциями из обоих файлов (или когда несколько включаемых файлов пользуются функциями другого общего файла).
Если к файлу эксперта, индикатора или скрипта подключен файл *.mqh, после компиляции он будет не нужен, можно будет передавать один основной файл *.ex5 и он будет работать как надо. А вот с библиотеками дело обстоит иначе, их необходимо передавать вместе с основным файлом. С одной стороны это неудобно, а с другой стороны дает возможность независимого обновления отдельных модулей эксперта или индикатора.
Файлы библиотек должны располагаться в папке «MQL5/Libraries». Создайте в этой папке свою папку «Изучение MQL5», а в ней новый файл. При создании файла в мастере MQL выберите тип создаваемого файла «Библиотека», дайте ему имя «Test». Применения каких-то особых премудростей для создания библиотеки не требуется. Все, что нужно – после параметров функции написать слово «export», тогда эта функция будет доступна извне. В только что созданном файле уже есть функция, выполняющая сложение двух аргументов, но она закомментирована, удалим комментарии:
int MyCalculator(int value,int value2) export
{
return(value+value2);
}
Выполняем компиляцию, и библиотекой можно пользоваться.
Чтобы воспользоваться библиотекой, ее сначала надо импортировать. Импорт выполняется директивой «#import» с указанием пути к файлу с библиотекой. Затем, следуют сигнатуры импортируемых функций. Сигнатура функции, это часть ее объявления, определяющая тип возвращаемого значения, имя функции и типы парамтеров. Завершается импорт снова директивой «#import»:
#import "Изучение MQL5/Test.ex5"
int MyCalculator(int value,int value2); #import
Обратите внимание, указано имя откомпилированного файла «Test.ex5», а не файла с кодом «Test.mq5».
Воспользуемся импортированной функцией. Код в OnStart():
Alert(MyCalculator(2,3));
Результат: «5».
Вызов функций Win API
Так же как и функции из библиотек, написанных на языке MQ5, можно использовать библиотеки, написанные на других языках, в том числе и стандартные библиотеки Windows, так называемые функции Windows API (Application Programming Interface – программный интерфейс приложений). Если это не стандартная библиотека, она должна располагаться в папке «MQL5/Libraries» (как и библиотеки, написанные на MQL5). Если же это библиотека Windows API, достаточно знать имя файла, а его фактическое положение нас не интересует (и, конечно же, надо знать сигнатуры импортируемых функций).
Попробуем воспользоваться стандартной функцией Windows для копирования файла CopyFileA(). В папке «CopyFileA» создайте скрипт «WinAPI», следующий код будем писать в нем. Импорт библиотеки:
#import "kernel32.dll"
int CopyFileA(uchar & [],uchar & [],int); #import
Дальше пишем код в функции OnStart(). Объявим две переменные для имени файла, который будем копировать и нового имени файла:
string from="D:\\1.txt"; string to="D:\\2.txt";
Использовать диск «C» для таких экспериментов, скорее всего, не получится из-за настроек безопасности Windows, поэтому используется диск «D». Если у вас только один диск «C», можно вставить флэшку. Создайте на диске «D» файл «1.txt».
Теперь строки string надо преобразовать в массивы uchar, чтобы передать их в функцию
CopyFileA():
uchar ufrom[]; uchar uto[];
StringToCharArray(from,ufrom); StringToCharArray(to,uto);
Остается вызвать функцию:
int rv=CopyFileA(ufrom,uto,0); Alert(rv);
Третий параметр функции определяет действие в случае, если файл назначения существует. Если третий параметр равен 0, выполняется перепись файла. Если действие выполнено успешно, функция возвращает 1, в случае ошибки – 0. Если третий параметр равен 1, то копирование файла происходит только при отсутствии файла назначения, если же он существует, функция возвращает 0, а перезапись файла не выполняется.
Если запустить скрипт, на диске «D» должен появиться файл «2.txt» и должно открыться окно с сообщением «1». Однако этого может не произойти. Дело в том, что с начальными настройками в терминале запрещен импорт библиотек DLL (Dynamic Link Library – библиотека динамической компоновки, это те файлы в которых располагаются функции Windows API), поскольку их использование является потенциально опасным. Для разрешения импорта DLL выполните:
Терминал – Главное меню – Сервис – Настройки – Советники – Разрешить импорт DLL. Можно не включать общее разрешение, тогда нужно сделать так, чтобы скрипт запускался с окном свойств, для этого в верхнюю часть файла добавьте строку:
#property script_show_inputs
Теперь на запуске скрипта можно поставить разрешение только для него одно. В окне свойств во вкладке «Зависимости» поставьте галку «Разрешить импорт DLL» (рис. 43).
Рис. 43. Окно свойств скрипта, использующего импорт DLL
Функцию CopyFileA() можно считать морально устаревшей, поэтому и потребовались такие ухищрения с преобразованием строк в массивы. В файле «kernel32.dll» есть более современный вариант данной функции – CopyFileW(). Попробуем воспользоваться ей. Создайте скрипт «WinAPI2», пишем код в нем. Импорт:
#import "kernel32.dll"
int CopyFileW(string,string,int); #import
Код в функции OnStart():
string from="D:\\2.txt"; string to="D:\\3.txt";
int rv=CopyFileW(from,to,0); Alert(rv);
После выполнения этого скрипта на диске «D» должен появиться файл «3.txt» и открыться окно с сообщением «1».
Указатель на функцию
Если поискать в интернете, можно обнаружить целую сотню различных функций трейлингстопа. Если не сотню, то несколько десятков – точно. Трейлинг стоп, это функция для перемещения стоплосса у рыночной позиции. Допустим, вы решили поэкспериментировать и включить в своего эксперта всю это количество функций. Таким образом, в окне свойств появляется множество переменных для включения/выключения этих трейлингов, но это не проблема.
Проблема в том, что в коде появляется огромное количество проверок if, в результате скорость тестирования эксперта значительно снижается. Использование указателя на функцию позволит сформировать массив указателей только необходимых функций (включенных с данными настройками эксперта) и вызывать только их без лишних проверок. Существует большое количество и других задач, для решения которых указатель на функцию будет очень полезен.
Указатель на функцию это своего рода тип данных, определяемый типом переменной, которую функция возвращает и количеством и типом ее аргументов.
Создайте папку «015 FunPointer», а в ней скрипт с именем «FunPointer», пишем код в нем. Сначала надо описать тип, это делается при помощи ключевого слова typedef, после него указывается тип, возвращаемый функцией. Затем, в скобках указывается имя типа со звёздочкой (звездочка означает, что это указатель). В конце, в круглых скобках, перечисляются все параметры функции. Создадим тип для функции, возвращающей тип double и имеющей два параметра:
typedef double (*TFun01)(double,double);
Напишем две функции, одна для сложения, вторая для умножения:
double sum(double a,double b){ return(a+b);
}
double mult(double a,double b){ return(a*b);
}
Далее пишем код в функции OnStart(). Объявляем переменную для указателя на функцию:
TFun01 fun;
Будем использовать разные функции в зависимости от значения внешнего параметра, для этого в верхней части файла добавим соответствующее свойство и параметр для выбора типа арифметического действия, а также две переменные для ввода аргументов:
#property script_show_inputs input bool add=true;
input double a=2.0; input double b=3.0;
Продолжаем в функции OnStart(). В зависимости от значения внешней переменной add выбираем подходящую функцию:
if(add){
fun=sum;
}
else{
fun=mult;
}
Вызываем функцию:
double r=fun(A,B);
Alert(r);
Если запустить скрипт и установить параметру add значение true, будет результат 5 (сложение), а с
false будет результат 6 (умножение).
Как видим, все универсальные функции должны быть идентичны, в общем-то, это не проблема. Если использовать такой подход для включения функций трейлинга, следует сделать функции без параметров. Кроме того, язык MQL5 является объектно-ориентированным, и эту задачу, может быть, будет удобней решить при помощи объектов.
Обработка ошибок
Многие функции в языке MQL5 возвращают значение true/false, сообщающее об успешности/не успешности ее выполнения. Некоторые функции вместо true/false возвращают целочисленное значение, указывающее на успешное выполнение функции и 0 или -1 при неуспешном выполнении. Иногда, особенно на стадии освоения языка, бывает нужно разобраться, почему функция не отработала как надо.
В этом может помочь функция GetLastError(). Эта функция возвращает код последней ошибки, которая была зафиксирована в процессе работы программы, а по этому коду в справке можно посмотреть описание ошибки и что-то понять о проблеме и о способе ее решения. К сожалению, довольно часто эти сведения бывают бесполезными, тем не менее, если проблема не поддается решению, надо пробовать все способы. Функция GetLastError() используется совместно с функцией ResetLastError(). Перед проблемным участком кода необходимо вызвать функцию ResetLastError(). А после проблемного участка нужно посмотреть значение, возвращаемое функцией GetLastError().
Создайте папку «016 GetLastError», а в ней скрипт «GetLastError», следующий код будем писать в этом файле. Напишем такой код, который будет давать ошибку при попытке открытия файла.
string fileName="1.txt";
int h=FileOpen(fileName,FILE_WRITE); if(h==-1){
Alert("Ошибка 1");
}
int h2=FileOpen(fileName,FILE_WRITE); if(h2==-1){
Alert("Ошибка 2");
}
FileClose(h);
При выполнении этого скрипта будет открываться окно с сообщением «Ошибка 2». Конечно, сейчас понятно, отчего возникает эта ошибка, но ведь предшествующий код может быть более сложным и находиться в какой-то функции, расположенной за пределами прямой видимости.
Из-за ошибки в коде не поучается открыть файл второй раз. Для выяснения причины ошибки перед функцией открытия добавляем вызов функции ResetLastEror(), а сразу после – GetLastError(). Теперь код в функции OnStart() будет выглядеть так:
string fileName="1.txt";
int h=FileOpen(fileName,FILE_WRITE);
if(h==-1){
Alert("Ошибка 1");
}
ResetLastError();
int h2=FileOpen(fileName,FILE_WRITE); if(h2==-1){
int er=GetLastError();
Alert("Ошибка 2, номер ошибки ",er);
}
FileClose(h);
При выполнении этого кода будет открываться окно с сообщением «Ошибка 2, номер ошибки 5004». Чтобы посмотреть расшифровку ошибки, воспользуйтесь поиском по справке (рис. 44).
Рис. 44. Поиск в справке по номеру ошибки
Находим описание: ERR_CANNOT_OPEN_FILE – Ошибка открытия файла. На это раз не повезло, не очень полезная информация. Тем не менее, не стоит пренебрегать функцией GetLastError() иногда ее помощь незаменима.
Обратите внимание, в примере кода значение функции GetLastError() присваивается переменной, а уже потом используется в сообщении. Рекомендуется делать именно так – вызывать GetLastErorr() сразу после проблемной функции. Дело в том, что при формировании сообщения часто вызываются разные другие функции. Поэтому может получиться, что функция GetLastError() будет вызвана после них, соответственно вы будете введены в заблуждение ее значением.
С некоторыми функциями нет смысле использовать GetLastError(), например с математическими. Известно, что аргумент функции арксинуса не может превышать 1. Вызовем функцию MathArcsin() с аргументом 2:
ResetLastError(); double r=MathArcsin(2); int er=GetLastError(); Alert(er," ",r);
Результат: «0 -nan(ind)» – функция явно отработала с ошибкой, вместо числового результата получено «-nan(ind)» – неопределенное значение, но GetLastEroror() дает 0.
Наиболее полезны в практической деятельности коды возврата торгового сервера. Обязательно ознакомьтесь с ними по справочному руководству: Константы, перечисления и структуры – Коды ошибок и предупреждений – Коды возврата торгового сервера.
Профилирование и проверка быстродействия
В разделе про массивы рекомендовалось использовать переменную для размера массива при организации цикла, а не вызывать функция ArraySize() на каждой итерации. Теперь проверим, насколько этот совет оправдан. Для измерения времени воспользуемся функцией GetTickCount(), функция возвращает количество миллисекунд, прошедших от момента запуска скрипта. Сначала напишем две функции, которые будем сравнивать. Надо помнить, что компилятор выполняет оптимизацию кода, поэтому нужно написать такой код, который выполняет какие-то полезные действия. Напишем функции, которые заполняют массивы возрастающими значениями, начиная от значений, указанных в параметрах скрипта. В конце подсчитаем сумму значений в массивах и выведем результаты.
В папке «016 GetLastError» создайте скрипт с именем «SpeedTest» с двумя внешними параметрами типа int: s1 и s2. Пишем код в этом файле. Надо учитывать, что заполнение массива значениями происходит очень быстро, а нам нужны действия, которые будут выполняться несколько секунд. Конечно, можно значительно увеличить размер массива, но тогда можно столкнуться со сложностями операционной системы по обеспечению работы с массивами большого размера. Поэтому добавим еще по оному циклу. Получаются такие функции:
void f1(int & a[],int s,int c){ for(int k=0;k<c;k++){
for(int i=0;i<ArraySize(a);i++){ a[i]=s+i;
}
}
}
void f2(int & a[],int s,int c){ int sz=ArraySize(a);
for(int k=0;k<c;k++){ for(int i=0;i<sz;i++){
a[i]=s+i;
}
}
}
Первая функция с вызовом ArraySize() на каждой итерации, вторая – с использованием переменной для размера массива. Параметры функций: a – массив, s – начальное значение, с – количество циклов. Объявим два массива и переменные для размера массивов и количества циклов (код располагается сразу после внешних параметров):
int a1[];
int a2[];
int array_size=1000; int cycles=1000;
В функции OnStart() изменяем размер массивов и вызываем функции:
ArrayResize(a1,array_size); ArrayResize(a2,array_size);
f1(a1,s1,cycles); f2(a2,s2,cycles);
Напишем еще одну функцию для суммирования всех элементов массива:
int f3(int & a[]){ int rv=0;
int sz=ArraySize(a); for(int i=0;i<sz;i++){
rv+=a[i];
}
return(rv);
}
В конце функции OnStart() используем ее и выведем результаты:
Print(f3(a1));
Print(f3(a2));
Остается дописать код для замера времени. Перед функцией OnStart() добавляем переменную:
long tm;
Перед вызовом функции f1() засекаем время:
tm=GetTickCount();
После функции вычисляем время и выводим его:
Alert("1: ",GetTickCount()-1);
Так же и со второй функции, в итоге получаем такой код в функции OnStart():
ArrayResize(a1,array_size); ArrayResize(a2,array_size);
tm=GetTickCount(); f1(a1,s1,cycles);
Alert("1: ",GetTickCount()-tm);
tm=GetTickCount(); f2(a2,s2,cycles);
Alert("2: ",GetTickCount()-tm);
Print(f3(a1));
Print(f3(a2));
Запускаем скрипт и смотрим результат. Если скрипт отработает очень быстро, надо увеличить значение переменной cycles. Увеличивайте значение в 10 раз и запускайте скрипт, пока время его работы не будет составлять несколько секунд. К удивлению, результаты оказываются примерно одинаковые для обеих функций.
Теперь воспользуемся специализированным средством для исследования быстродействия – профилировщиком, встроенным в редактор MetaEditor. Выполните команду главного меню ректора: Отладка – Начать профилирование на реальных данных. При этом откроется окно терминала, автоматически запустится скрипт, а через несколько секунд снова откроется редактор с результатами профилирования. Наиболее полные результаты профилирования находятся в окне «Инструменты», во вкладке «Профилировщик» (рис. 45). В этом случае отчетливо видно, что функция f1() почти в два раза медленнее.
Из данных экспериментов можно сделать два очевидных вывода. Первый вывод – использование переменной и однократного вызова функции ArraySize() все-таки работает быстрее. Второй вывод — если существуют специализированные средства для решения какой-то задачи, следует пользоваться ими.
Рис. 45. Результаты профилирования
Отладчик
Наиболее частые ошибки в работе программы, это деление на ноль и выход за пределы массива. При этих ошибках работа программы прерывается, то есть ошибки являются критическими. При тестировании на этапе разработки, в случае ошибки с выходом за пределы массива, бывает нужно узнать, с какой стороны произошел выход за пределы, чтобы принять соответствующие меры. Работа с массивом обычно происходит в цикле, поэтому взять и вывести значение индекса через Print() – не вариант, будет выведено слишком много данных. Можно добавить в код дополнительную проверку, но это лишние действия, тем более, что в редакторе есть специализированное средство, позволяющие легко решить данную проблему, – отладчик.
В папке «016 GetLastError» Создайте скрипт с именем «Debug». Напишем код с массивом и циклом, но такой, что бы заранее было непонятно с какой стороны произойдет выход за пределы массива. Для этого понадобится случайное число 1 или -1:
MathSrand(0); int n[]={-1,1};
int r=n[MathRand()%2];
Массив из десяти элементов:
int a[10];
Цикл от 0 до 10, в котором обращение к элементу массива происходит со смещением на полученное ранее случайное число r:
for(int i=0;i<10;i++){ a[i+r]=i;
}
Если запустить этот скрипт, во вкладке «Эксперты» будет сообщение: «array out of range in ‘Debug.mq5’ (23,8)» (выход за пределы массива). Числа в скобках, это строка и номер символа, где обнаружилась ошибка. Но нам надо узнать значение переменной i, при котором случилась эта ошибка. Используем отладчик. Для запуска отладки есть две команды главного меню: Отладка – Начать на реальных данных, а вторая команда «Отладка начать на исторических данных». При отладке на реальных данных выполняется запуск программы на активном графике, а при отладке в тестере – на выбранном в нем символе и таймфорейме. Разумеется, выполнять отладку скриптов можно только на реальных данных. В настройках редактора можно один раз задать параметры отладки: символ, таймфрейм и пр. Для этого выполните команду главного меню: Сервис – Настройки – Отладка. В этом случае отладка не будет зависеть от активного графика или параметров, установленных в тестере.
Рис. 46. Сообщение отладчика
Значит, запускаем отладку на реальных данных, открывается окно терминала, в нем на активном графике запускается скрипт, а поскольку в скрипте происходит критическая ошибка, открывается окно с сообщением об этой ошибке и предложением продолжить в отладчике (рис. 46).

Рис. 47. Строка с ошибкой отмечена стрелкой
При нажатии на кнопку «OK» произойдет открытие редактора, а строка, в которой произошла ошибка, будет помещена стрелкой (рис. 47).
Остается посмотреть значения интересующих нас переменных. Для этого надо установить курсор перед переменной, щелкнуть правой кнопкой и в контекстном меню выбрать команду «Добавить наблюдение» (рис. 48).
Сделаем так для переменных i и r. Теперь в панели «Инструменты», во вкладке «Отладка» можно увидеть их значения (рис. 49).
По значениям переменных i и r понятно, что выход за пределы массива произошел слева – со стороны наименьших индексов.
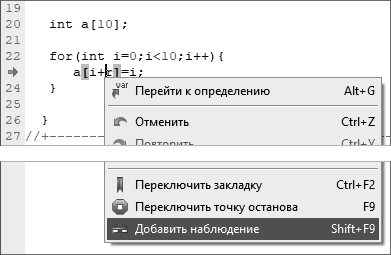
Рис. 48. Команда «Добавить наблюдение» в контекстном меню
Рис. 49. Значения наблюдаемых переменных
Если критической ошибки в программе нет, но есть сомнения в правильности ее действий, можно самостоятельно добавить точку останова на нужной строке и так же исследовать содержимое переменных. Создайте скрипт «Debug2», следующий код будем писать в нем. Объявим две переменных, инициализируем их случайными значениями. Напишем формулу с их использованием и присвоим результаты ее вычисления третьей переменной:
MathSrand(0);
int a=MathRand(); int b=MathRand(); int c=a+b;
Полученный скрипт работает без ошибок, но нам бы хотелось «заглянуть» в него во время работы. Установите курсор в строку с формулой и выполните команду главного меню: Отладка – Переключить точку останова. От этого в начале строки появится отметка (рис. 50).
Рис. 50. Точка останова
Запускаем отладку командой главного меню: Отладка – Начать на реальных данных. Откроется окно терминала, запуститься скрипт и снова откроется редактор, и точка останова будет выделена. Остается добавить наблюдения, как и в предыдущем примере.
Для удаления ненужного наблюдения щелкните на нем правой кнопкой и выберите «Удалить». При отладке может использоваться любое количество точек останова. Если их больше одной, то чтобы перейти к следующей точке, надо выполнить команду главного меню: Отладка – Продолжить выполнение. Этих кнопок две, одна из них соответствует клавише F5, другая – Ctrl+F5. При использовании F5, при достижении последней точки останова отладка начинается сначала, а при использовании Ctrl+F5 завершается.
Для завершения отладки выполнятся команда главного меню: Отладка – Завершить. Чтобы удалить ненужную точку останова, надо установить курсор в строку с ней и выполнить команду главного меню: Отладка – Переключить точку останова. Для удаления всех точек останова используется команда главного меню: Отладка – Убрать все точки останова». Вместо команд главного меню может быть удобней использовать соответствующие кнопки на панели инструментов.