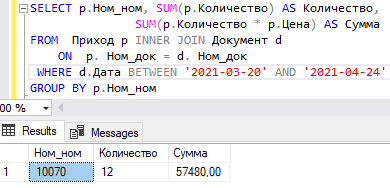
Язык SQL — Оконные функции T-SQL
1. Описание оконных функций
Оконные функции (window functions) это функции, применяемые к набору строк связанных с текущей строкой.
Эти функции основаны на принципе языка SQL — принципе работы с окнами (windowing). Основа этого принципа — возможность выполнять различные вычисления с набором строк, или окном, и возвращать одно значение.
Оконные функции в основном используются для решения аналитических задач, например, для вычисления каких-то статистических значений (нарастающие итоги, скользящие средние, промежуточные итоги и так далее).
Конечно, все что могут оконные функции, можно реализовать и без них, например, с помощью агрегатных функциях AVG, SUM, COUNT и др. Однако оконные функции обладают большим преимуществом перед агрегатными функциями: оконные функции не приводят к группированию строк в одну строку вывода, строки сохраняют значения своих атрибутов, а агрегированное значение добавляется к каждой строке.
В стандарте языка SQL предусмотрена поддержка нескольких типов оконных функций:
- агрегатные,
- ранжирующие,
- сдвига,
- аналитические (или распределения).
В одной команде SELECT с одним предложением FROM можно использовать несколько оконных функций.
Впервые поддержка оконных функций появилась в версии Microsoft SQL Server 2005, в которой была реализованы базовая функциональность. В Microsoft SQL Server 2012 функционал оконных функций был расширен, и теперь он с лёгкостью решает много задач, для решения которых до этого приходилось писать сложный код.
Определение оконной функции указывается в предложении OVER:
Имя оконной функции (<столбец для вычислений>) OVER
(
[PARTITION BY <столбец для секционирования >] [ORDER BY <столбец для упорядочения [ASC | DESC]>
[ROWS или RANGE <выражение для фильтрации строк в пределах кадра>]]
)
Предложение OVER определяет набор строк по отношению к текущей строке (окно), предоставляемый как входные данные этапа обработки запроса. Оно содержит три ключевых элемента — секционирование, упорядочение и кадрирование. Задача этих трех элементов — фильтровать строки в окне.
Элемент секционирования реализован как предложение PARTITION BY и поддерживается всеми оконными функциями. Предложение PARTITION BY не является обязательным, но дополняет OVER и позволяет ограничить окно только теми строками, у которых те же атрибуты секционирования, что и в текущей строке.
Например, если в функции присутствует предложение PARTITION BY Val и значение атрибута val в текущей строке равно 100, окно, связанное с текущей строкой, обеспечит выбор из результирующего набора всех строк, у которых значение атрибута val равно 100. Если значение атрибута val текущей строки равно 150, в окно войдут все строки со значением атрибута val равным 150. Если предложение PARTITION BY не указано, функция будет обрабатывать все строки результирующего набора.
Элемент упорядочения реализован как предложение ORDER BY. Параметры этого предложения ASC и DESC определяют порядок обработки строк в секции по возрастанию или по убыванию значений. По умолчанию записи сортируются по возрастанию. Все оконные функции поддерживают элемент упорядочения.
Кадрирование применяется как к агрегатным функциям, так и к трем функциям сдвига: FIRST_VALUE, LAST_VALUE и NTILE. Для кадрирования в стандарте SQL используются предложения ROWS и RANGE. Предложение ROWS ограничивает строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей строкой. Предложение RANGE логически ограничивает строки за счет указания диапазона значений в отношении к значению текущей строки. Оба предложения ROWS и RANGE используются вместе с предложением ORDER BY.
Для того, чтобы лучше понять как работают оконные функции, рассмотрим несколько примеров. Для демонстрации работы оконных функций будем использовать тестовую таблицу с именем TestOver, представленную на рис. 4.
Таблица TestOver содержит три столбца. Как видно на рис. 4 столбец IdGroup имеет три группы значений, а столбец IdSubGroup — две подгруппы с разным количеством элементов в подгруппе.
Рассмотрение примеров начнем с запросов, использующих агрегатные оконные функции.
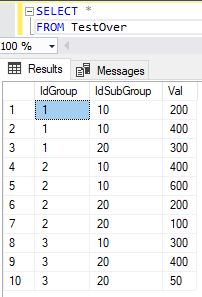
Рис. 4. Таблица TestOver
2. Агрегатные оконные функции
Агрегатные функции – это функции SUM, AVG, MIN, МАХ, COUNT, которые выполняют на наборе данных вычисления и возвращают результирующее значение.
Обычно агрегатные функции используются в запросах в сочетании с предложением GROUP BY. Но их также можно использовать и с предложением OVER. В последнем случае они будут вычислять значения в определённом окне (наборе данных) для каждой текущей строки.
Использование в агрегатных оконных функциях элемента секционирования (предложение PARTITION BY)
Давайте посмотрим, как работает предложение OVER с предложением PARTITION BY, на примере функции суммирования:
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER() AS Sum1,
SUM(Val) OVER(PARTITION BY IdGroup) AS Sum2
FROM TestOver
Результат выполнения команды SELECT с предложением PARTITION BY представлен на рис. 5.
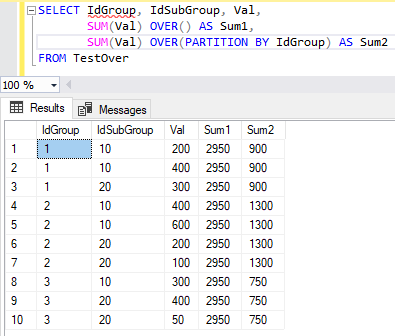
Рис. 5. Результат выполнения команды SELECT с агрегатной оконной функцией, содержащей предложение PARTITION BY
Обратите внимание на новые столбцы с именами Sum1 и Sum2, которые появился в результирующей таблице. Давайте разберемся со значениями, которые содержат эти столбцы.
Первое предложение OVER() не содержит элементов секционирования, упорядочения и кадрирования. В таком варианте окном будет весь набор данных и никакого упорядочивания не применяется.
Для каждой строки выводится одно и то же значение 2950. Это общая сумма всех значений столбца с именем Val.
Второе предложение OVER содержит предложение PARTITION BY, определяющее столбец, по которому будет производиться секционирование данных, и он является ключевым в разбиении набора строк на окна. Предложение PARTITION BY секционировало строки по столбцу IdGroup. Теперь для каждой секции будет применяться оконная функция и рассчитываться своя сумма значений. Можно создавать секции по нескольким столбцам. Тогда в предложении PARTITION BY нужно писать поля для секции через запятую, например, PARTITION BY IdGroup, Val.
Использование в агрегатных оконных функциях элемента упорядочения (предложение ORDER BY)
Вместе с предложением PARTITION BY в оконной функции может применяться предложение ORDER BY, которое определяет порядок упорядочения внутри секции. В этом случае оконная функция будет обрабатывать данные согласно этому порядку. Рассмотрим следующую команду
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY Val) ASSum3
FROM TestOver
В данном примере в оконной функции применяется агрегатная функция SUM по столбцу Val, окно секционируется по столбцу IdGroup, а строки секции упорядочиваются (по возрастанию) по столбцу Val.
Результат выполнения этой команды представлен на рис. 6. По умолчанию, если не задано предложение ORDER
BY внутри предложения OVER, границами окна являются все строки. Если предложение ORDER BY задано, то границей для текущей строки будут все предшествующие строки и текущая строка. Таким образом, мы указали, что хотим видеть для каждого значения атрибута Val сумму со всеми предыдущими значениями. Такое суммирование часто называют нарастающий итог или накопительный итог.
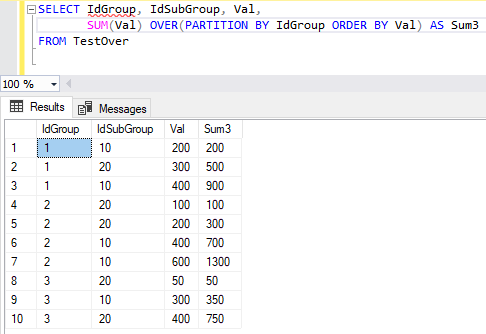
Рис. 6. Результат выполнения команды SELECT с агрегатной оконной функцией, содержащей предложения PARTITION BY и ORDER BY
Если при описании окна секционирование отсутствует, т.е. предложение PARTITION BY не указано, а имеется только предложение ORDER BY, то окном будет весь набор данных.
Рассмотрим, как изменится нарастающий итог, в зависимости от упорядочения. Изменим предыдущую команду, добавив в предложение ORDER BY столбец IdSubGroup:
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup, Val) AS Sum4
FROM TestOver
Результат выполнения этой команды приведен на рис. 7.
Как следует из рис. 7, в столбце Sum4 последние в секции значения сходятся с предыдущим примером, но сумма для всех остальных строк отличается. Поэтому важно четко понимать, что вы хотите получить в итоге.
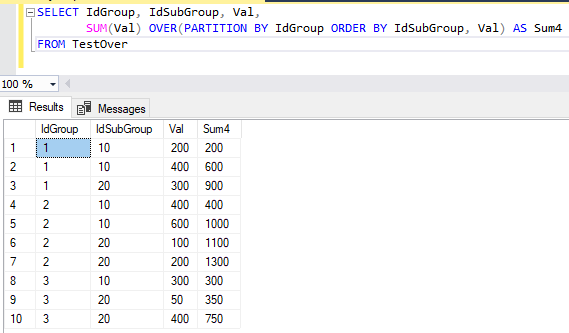
Рис. 7. Результат выполнения команды SELECT с агрегатной оконной функцией, содержащей предложение ORDER BY IdSubGroup, Val
Использование в агрегатных оконных функциях элемента кадрирования (предложения ROWS и RANGE)
Теперь рассмотрим, как использовать в оконных функциях элемент кадрирования. При наличии упорядочения кадрирование определяет нижнюю и верхнюю границы в секции окна, так что фильтр проходят только строки между этими двумя границами. Для кадрирования используются два предложения ROWS и RANGE.
Предложение ROWS
Предложения ROWS означает, что границы кадра могут задаваться в виде смещения числа строк или разницы от текущей строки. Предложение ROWS содержит следующее выражение для ограничения строк в пределах кадра:
ROWS BETWEEN UNBOUNDED PRECEDING |
<n> PRECENDING |
<n> FOLLOWING |
CURRENT ROW
AND
UNBOUNDED FOLLOWING |
<n> PRECENDING |
<n> FOLLOWING |
CURRENT ROW
где CURRENT ROW – параметр указывает, что окно начинается или заканчивается на текущей строке, он может быть задан как начальная или как конечная точка;
UNBOUNDED FOLLOWING –параметр указывает, что окно заканчивается на последней строке секции, т.е. в окно входят все записи после текущей строки. Этот параметр может быть указан только как верхняя граница окна;
UNBOUNDED PRECEDING – параметр указывает, что окно начинается с первой строки секции, т.е. в окно входят все записи до текущей строки. Данный параметр используется только как нижняя граница окна;
<n > PRECEDING – параметр определяет число строк перед текущей строкой;
<n> FOLLOWING – параметр определяет число строк после текущей строки. Если FOLLOWING используется как начальная точка окна, то конечная точка должна быть также указана с помощью FOLLOWING.
Предшествующие и последующие строки определяются на основании порядка, заданного в предложении ORDER BY.
Для формирования оконного кадра, создаваемого для каждой строки, можно использовать комбинацию этих параметров для достижения желаемого результата, например:
ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING
В этом случае в кадр попадут текущая и одна следующая запись. Предложение ROWS поддерживает лаконичную форму. Если не указать верхнюю границу, предполагается, что это CURRENT ROW
(то есть текущая строка). Поэтому описания
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
и
ROWS UNBOUNDED PRECEDING
эквивалентны друг другу Рассмотрим следующий запрос:
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup, Val ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS Sum5
FROM TestOver
В результате эта команда сформирует итоговую таблицу, представленную на рис. 8.
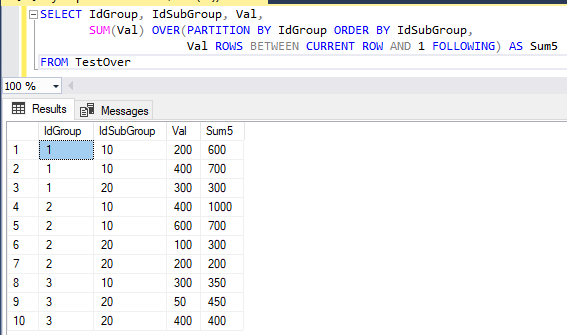
Рис. 8. Результат выполнения команды SELECT с агрегатной оконной функцией SUM, содержащей предложение ROWS
Здесь, значения столбца Sum5 рассчитывается как сумма текущей и следующей строки в кадре. А последняя в кадре строка имеет то же значение, что и в столбце Val. Первое значение столбца Sum5 равное 600 рассчитано сложением 200 и 400. Для следующего значения ситуация аналогичная. А последняя в кадре сумма имеет значение 300, потому что в текущей строке значение атрибута Val больше не с чем складывать.
В качестве второго примера использования предложения ROWS создадим три оконные функции с тремя определениями кадра:
SELECT IdGroup, IdSubGroup, Val,
MAX(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup, Val ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS Max1,
MAX(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup, Val ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING)) AS Max2,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup, Val ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) AS Sum6
FROM TestOver
При вычислении атрибута Max1 определяется кадр, состоящий из строк между 1 предыдущей и 1 предыдущей. Это означает, что кадр содержит только предыдущую строку в секции. Агрегат MAX, применяемый здесь к столбцу Val, излишен, потому что в кадре будет максимум одна строка. Максимальным значением будет значение в этой строке или NULL, если в кадре строк нет (то есть, если текущая строка является первой в секции). На рис. 9 приведен результат выполнения команды SELECT.
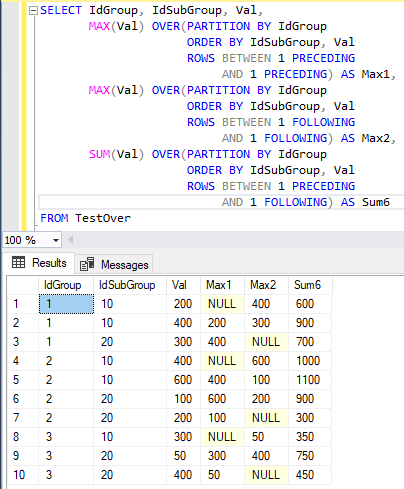
Рис. 9. Результат выполнения команды SELECT с агрегатной оконной функцией MAX, содержащей предложение ROWS
Обратите внимание, что у первой строки в секции нет соответствующей предыдущей, поэтому значение Max1 в первой строке секции равно NULL.
Аналогично при вычислении атрибута Max2 определяется кадр, состоящий из строк между 1 последующей и 1 последующей, то есть имеется в виду только следующая строка. Агрегат MAX(Val) возвращает значение из предыдущей строки (рис. 9).
Так как за последней строкой в секции никаких других строк нет, значение Max2 в последней строке секции равно NULL.
При вычислении атрибута Sum6 определяется кадр, состоящий из строк между одной предыдущей и одной следующей, то есть численность строк в кадре может достигать трех.
Как и в предыдущих примерах, нет строки, предшествующей первой строке, и строки, последующей за последней. Функция SUM корректно суммирует количество строк в кадре.
Предложение RANGE
Язык SQL позволяет определять оконный кадр с использованием предложения RANGE. В отличие от предложения ROWS, он работает не с физическими строками, а с диапазоном строк в предложении ORDER BY. Это означает, что строки с одинаковыми значениями в столбце предложения ORDER BY будут считаться как одна текущая строка для параметра CURRENT ROW. А в предложении ROWS текущая строка – это одна текущая строка набора данных.
Вот перечень возможностей для верхней и нижней границ в кадре:
RANGE BETWEEN UNBOUNDED PRECEDING |
CURRENT ROW
AND
UNBOUNDED FOLLOWING |
CURRENT ROW
Как и ROWS, предложение RANGE также поддерживает лаконичную форму.
В качестве примера рассмотрим запрос, в котором описаны две оконные функции
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup RANGE CURRENT ROW) AS Sum7,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS Sum8,
FROM TestOver
Результирующая таблица этого запроса приведена на рис. 10.
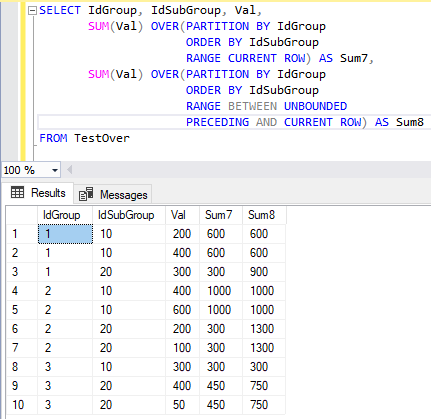
Рис. 10. Результат выполнения команды SELECT с агрегатной оконной функцией, содержащей предложение RANGE
В первой оконной функции предложение RANGE настроено на текущую строку. Но для предложения RANGE текущая строка, это все строки, соответствующие одному значению упорядочивания. Упорядочивание в данном примере осуществляется по столбцу IdSubGroup. Первые две строки первого кадра имеют значение атрибута IdSubGroup равное 10.
Следовательно, оба эти значения удовлетворяют ограничению RANGE CURRENT ROW. Поэтому значение атрибута Sum7 для каждой из этих строк равно общей сумме по ним 600. Так как во второй кадр входит только одна строка (третья строка) значение атрибута Sum6 будет равно 300.
Во второй оконной функции кадр задан по всем предыдущим строкам и текущей в секции. Для первой и второй строки это правило работает как в первой оконной функции этого примера, а для третьей как сумма атрибута Val предыдущих строк с текущей.
В следующем примере оконная функция содержит предложение RANGE, которое настроено так, что в кадр входят текущая строка и все записи после текущей строки:
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Sum9
FROM TestOver
Результат запроса представлен на рис. 11.
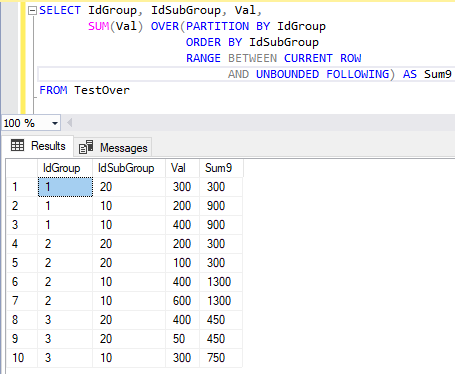
Рис. 11. Результат выполнения команды SELECT с агрегатной оконной функцией, содержащей кадр, в который входят текущая строка и все записи после текущей строки
В оконной функции заданное ограничение кадра позволяет получить сумму из текущей строки и всех последующих в рамках одного окна. Так как вторая и третья строка у нас в одной подгруппе, то эти значения и есть текущая строка (Current Row). Поэтому значения атрибута Val этих строк просуммированы сразу.
Обратите внимание на порядок строк в таблице на рис. 11. Дело в том, что предложение ORDER BY в описание окна не определяет порядок вывода в результирующей таблице. Если нужно гарантировать упорядочение итоговой таблицы, необходимо добавить в команду SELECT предложение ORDER BY. Например так:
SELECT IdGroup, IdSubGroup, Val,
SUM(Val) OVER(PARTITION BY IdGroup ORDER BY IdSubGroup RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Sum8
FROM TestOver
ORDER BY IdGroup, IdSubGroup
На рис. 12 приведена таблица, полученная в результате выполнения последней команды SELECT.
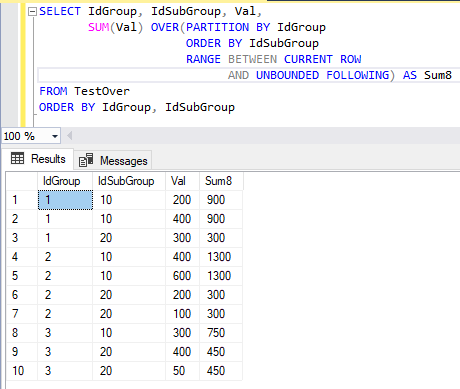
Рис. 12. Результат выполнения команды SELECT с агрегатной оконной функцией и сортировкой
3. Оконные функции ранжирования
Функции ранжирования – это функции, которые ранжируют значение для каждой строки в группе. Например, их можно использовать для того, чтобы пронумеровать строки по группам или выставить ранг и составить рейтинг.
В Microsoft SQL Server существуют следующие ранжирующие функции:
- ROW_NUMBER –функция вычисляет последовательные номера строк, начиная с 1, в соответствующей секции окна и в соответствии с заданным упорядочением окна;
- RANK — функция возвращает ранг каждой строки в зависимости от значения заданного столбца. В случае нахождения одинаковых значений в столбце, возвращает одинаковый ранг с пропуском следующего;
- DENSE_RANK — функция возвращает «уплотненный» ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая возвращает результирующий набор, разделённый на группы по определенному столбцу.
Все четыре функции ранжирования поддерживают необязательное предложение секционирования (PARTITION BY) и обязательное предложение упорядочения окна (ORDER BY). Если предложение секционирования окна отсутствует, весь результирующий набор базового запроса считается одной секцией. Что касается предложения упорядочения окна, то оно обеспечивает упорядочение при вычислениях. Понятно, что ранжирование строк без определения упорядочения не имеет смысл.
Рассмотрим примеры использования ранжирующих оконных функций. В первом примере запрос пронумерует все строки таблицы TestOver в соответствии со значениями столбца Val в порядке убывания:
SELECT IdGroup, IdSubGroup, Val,
ROW_NUMBER() OVER (ORDER BY Val DESC) AS Rownumber1
FROM TestOver
На рис. 13 приведен результат запроса.
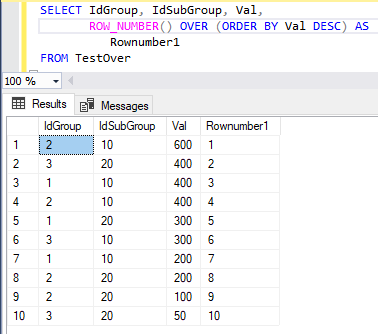
Рис. 13. Результат выполнения команды SELECT с оконной функцией ранжирования ROW_NUMBER
Так как в запросе SELECT нет предложения ORDER BY, сортировка итоговой таблицы не гарантируется. Если нужно, чтобы сортировка итоговой таблицы запроса выполнялась на основе номера строки, можно использовать псевдоним оконной функции в предложении ORDER BY команды SELECT, например:
SELECT IdGroup, IdSubGroup, Val,
ROW_NUMBER() OVER (ORDER BY Val DESC) AS Rownumber1
FROM TestOver
ORDER BY Rownumber1
Результат этого запроса совпадает с предыдущим запросом (рис. 13).
Если необходимо упорядочение итоговой таблицы, которое отличается от упорядочения окна, то можно использовать, например, следующий запрос:
SELECT IdGroup, IdSubGroup, Val,
ROW_NUMBER() OVER (ORDER BY Val DESC) AS Rownumber1
FROM TestOver
ORDER BY IdGroup, IdSubGroup
На рис. 14 приведены результаты этого запроса.
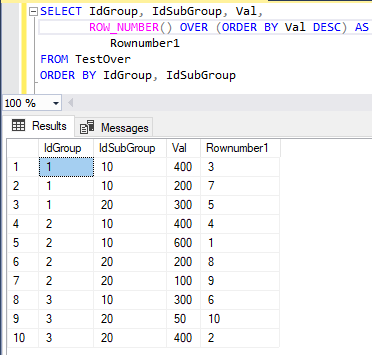
Рис. 14. Результат выполнения команды SELECT с оконной функцией ранжирования ROW_NUMBER и сортировкой
Следующий запрос вычисляет ранги и «уплотненные» ранги строк. При этом используется секционирование окна по умолчанию и упорядочение по атрибуту Val по убыванию (DESC):
SELECT IdGroup, IdSubGroup, Val,
RANK() OVER(ORDER BY Val DESC) AS Rank1, DENSE_RANK() OVER(ORDER BY Val DESC) AS DenseRank
FROM TestOver
Результаты запроса представлены на рис. 15.
Все строки с одним номером подгруппы, например 300, получили одинаковый «неплотный» ранг 5 и «плотный» ранг 3. Ранг 5 означает, что есть четыре строки с большими значениями атрибута Val (упорядочение ведется по убыванию), а «плотный» ранг 3 означает, что есть два значения атрибута Val в таблице (600 и 400), больше, чем 300.
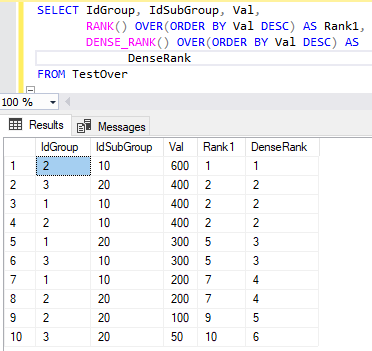
Рис. 15. Результат выполнения команды SELECT с оконными функциями ранжирования RANK() и DENSE_RANK()
Рассмотрим использование элемента секционирования в функциях ранжирования, например:
SELECT IdGroup, IdSubGroup, Val,
ROW_NUMBER() OVER (PARTITION BY IdSubGroup ORDER BY IdGroup) AS Rownumber2, RANK() OVER (PARTITION BY IdSubGroup ORDER BY Val) AS Rank2
FROM TestOver
Обе оконные функции имеют секционирование по атрибуту IdSubGroup. Первая оконная функция ROW_NUMBER() нумерует строки в каждой подгруппе, при этом используется упорядочивание по столбцу IdGroup. Во второй функции RANK() выставляется ранг каждой записи в подгруппе на основе значения атрибута Val.
На рис. 16 представлена результирующая таблица выполнения команды из рассмотренного примера.
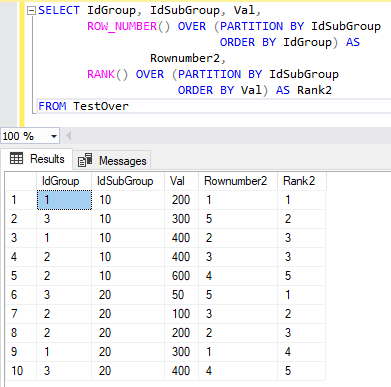
Рис. 16. Результат выполнения команды SELECT с оконными функциями ранжирования ROW_NUMBER() и RANK()
Функция NTILE позволяет разбивать строки в секции окна на примерно равные по размеру подгруппы (tiles) в соответствии с заданным числом подгрупп и упорядочением окна. Допустим, что нужно разбить строки таблицы TestOver на 5 подгрупп одинакового размера на основе упорядочения по атрибуту Val. В таблице 10 строк, значит размер каждой подгруппы будет составлять 2 строки. Поэтому первым 2 строкам будет назначен номер группы 1, следующим 2 строкам — номер подгруппы 2 и т. д. Вот запрос, вычисляющий номера подгрупп:
SELECT IdGroup, IdSubGroup, Val,
NTILE(5) OVER(ORDER BY Val) AS Ntile1
FROM TestOver
На рис. 17 представлен результат выполнения этого запроса. Ранее при описании функции NTILE использовалось слово «примерно», потому что число строк, полученное в базовом запросе, может не делиться нацело на число подгрупп. Допустим, вы хотите разбить строки таблицы TestOver на 4 подгруппы. При делении 10 на 4 получаем частное 2 и остаток 2. Это означает, что базовая размерность подгрупп будет две строки, но часть подгрупп получать дополнительную строку.
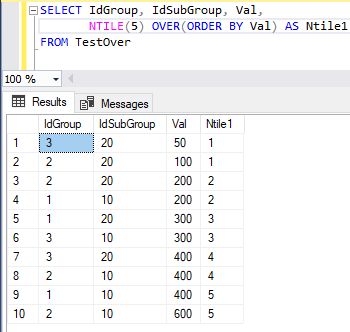
Рис. 17. Результирующая таблица выполнения команды SELECT с оконной функцией ранжирования NTILE, разбивающая данные на 5 подгрупп
Функция NTILE не пытается распределять дополнительные строки среди подгрупп с равным расстоянием между подгруппами — она просто добавляет по одному ряду в первые подгруппы, пока не распределит остаток. При наличии остатка равного 2 размерность первых 2 подгрупп будет на единицу больше базовой размерности. Поэтому первые 2 подгруппы будут содержать 3 строки, а последние 2 подгруппы — 2 строки, как показано в следующем запросе:
SELECT IdGroup, IdSubGroup, Val,
NTILE(4) OVER(ORDER BY Val) AS Ntile2
FROM TestOver
Результаты запроса приведены на рис. 18
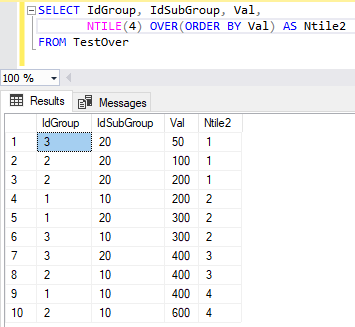
Рис. 18. Результирующая таблица выполнения команды SELECT с оконной функцией ранжирования NTILE, разбивающая данные на 4 подгруппы
4. Оконные функции смещения
Функции смещения – это функции, которые позволяют перемещаться и, соответственно, обращаться к разным строкам в наборе данных (окне) относительно текущей строки или просто обращаться к значениям в начале или в конце окна. Эти функции появились в Microsoft SQL Server 2012.
К функциям смещения в SQL относятся:
- LEAD – функция обращается к данным из следующей строки набора данных. Ее можно использовать, например, для того чтобы сравнить значение указанного атрибута в текущей строке со значением этого атрибута в следующей строке. Функция имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть, если после смещения возвращается значение NULL;
- LAG – функция обращается к данным из предыдущей строки набора данных. В данном случае функцию можно использовать для того, чтобы сравнить значение указанного атрибута в текущей строке со значением этого атрибута в предыдущей строке. Функция имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1, значение, которое необходимо вернуть, если после смещения возвращается значение NULL;
- FIRST_VALUE — функция возвращает первое значение из набора данных. В качестве параметра функции принимается столбец, значение которого необходимо вернуть;
- LAST_VALUE — функция возвращает последнее значение из набора данных. В качестве параметра функции принимается столбец, значение которого необходимо вернуть.
Оконные функции смещения делятся на две категории. Первая категория — функции, смещение которых указывается по отношению к текущей строке. К этой группе относятся функции LAG и LEAD. В функциях второй категории смещение указывается по отношению к началу или концу окна. В эту группу входят функции FIRST_VALUE, LAST_VALUE.
Функции первой категории (LAG и LEAD) поддерживают предложение секционирования, а также упорядочения окна. Функции из второй категории (FIRST_VALUE и LAST_VALUE) помимо предложения секционирования и упорядочения окна поддерживают предложение оконного кадра.
Рассмотрим запрос, в котором используются оконные функции смещения LEAD и LAG:
SELECT IdGroup, IdSubGroup, Val,
LEAD(Val) OVER (PARTITION BY IdGroup ORDER BY IdSubGroup) AS Lead,
LAG(Val) OVER (PARTITION BY IdGroup ORDER BY IdSubGroup) AS Lag
FROM TestOver
На рис. 19 приведена итоговая таблица запроса с оконными функциями смещения LEAD и LAG.
Так как смещение явно не задано, по умолчанию предполагается смещение на единицу. Так как данные в функции секционируются по IdGroup, каждая секция будет содержать только те строки, у которых одинаковое значение атрибута IdGroup (в нашем примере три секции). Что касается упорядочения окон, то понятия «предыдущий» и «следующий» определяются упорядочением по значениям атрибута IdSubGroup. Заметьте, что в результатах запроса LAG возвращает NULL для первой строки оконной секции, потому что перед первой строкой других строк нет. Аналогично LEAD возвращает NULL для последней строки каждой секции.
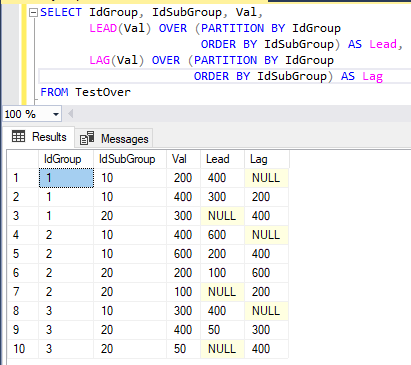
Рис. 19. Итоговая таблица запроса с оконными функциями смещения LEAD и LAG
Если необходимо смещение, отличное от единицы, его нужно указать в качестве второго аргумента функций LAG и LEAD.
Оконные функции LAG и LEAD по умолчанию возвращают NULL, если по заданному смещению нет строки. Если нужно возвращать другое значение, можно указать его в качестве третьего аргумента функции. Например, LAG(val, 3, 0.00) возвращает «0.00», если по смещению 3 перед текущей строкой нет строки.
Функции FIRST_VALUE и LAST_VALUE возвращают запрошенные значения соответственно из первой и последней строки в окне.
Рассмотрим запрос, демонстрирующий, как возвращать значения из первой и последней строки каждого окна:
SELECT IdGroup, IdSubGroup, Val,
FIRST_VALUE(Val) OVER (PARTITION BY IdGroup ORDER BY IdGroup) AS FirstValue,
LAST_VALUE (Val) OVER (PARTITION BY IdGroup ORDER BY IdGroup ) AS LastValue
FROM TestOver
Результат запроса приведен на рис. 20.
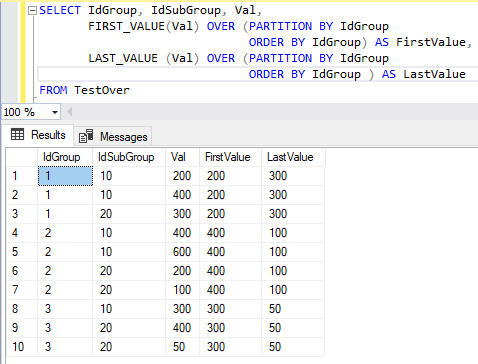
Рис. 20. Итоговая таблица запроса с оконными функциями смещения FIRST_VALUE и LAST_VALUE
Оконную функцию можно использовать в выражениях. В следующем примере запрос возвращает, разницу между текущим значением атрибута Val и значением этого атрибута в первой и последней строке:
SELECT IdGroup, IdSubGroup, Val,
Val FIRST_VALUE(Val) OVER (PARTITION BY IdGroup ORDER BY IdGroup) AS DiffFirst,
Val LAST_VALUE (Val) OVER (PARTITION BY IdGroup ORDER BY IdGroup) AS DiffLast
FROM TestOver
На рис. 21 представлена итоговая таблица этого запроса.
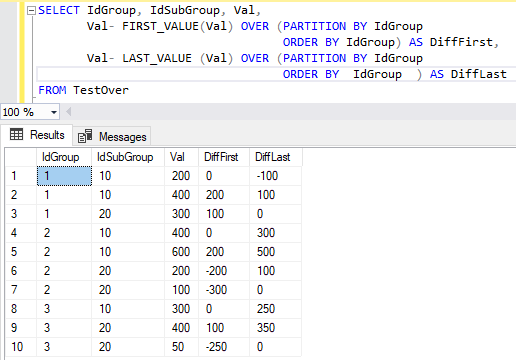
Рис. 21. Итоговая таблица запроса с оконными функциями смещения FIRST_VALUE и LAST_VALUE, входящими в выражения
5. Аналитические оконные функции
Аналитические оконные функции, или функции распределения (distribution function), предоставляют информацию о распределении данных. Эти функции очень специфичны и в основном используются для статистического анализа, к ним относятся:
- CUME_DIST — вычисляет и возвращает интегральное распределение значений в наборе данных. Иными словами, она определяет относительное положение значения в наборе;
- PERCENT_RANK — вычисляет и возвращает относительный ранг строки в наборе данных;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Функции PERCENT_RANK и CUME_DIST относятся к функциям распределения рангов. Функции PERCENTILE_CONT и PERCENTILE_DISC являются функциями обратного распределения.
Функции распределения рангов
Оконные функции распределения рангов поддерживают необязательное предложение секционирования и обязательное предложение упорядочения окна.
Рассмотрим пример запроса, использующего две аналитические функции PERCENTILE_CONT и PERCENTILE_DISC, которые вычисляют относительный ранг строки в секции окна, выраженный как дробное число от нуля до единицы:
SELECT IdGroup, IdSubGroup, Val,
PERCENT_RANK() OVER (PARTITION BY IdGroup ORDER BY Val) AS PercentRank,
CUME_DIST() OVER (PARTITION BY IdGroup ORDER BY Val) AS CumeDist
FROM TestOver
Результаты запроса приведены на рис. 22.
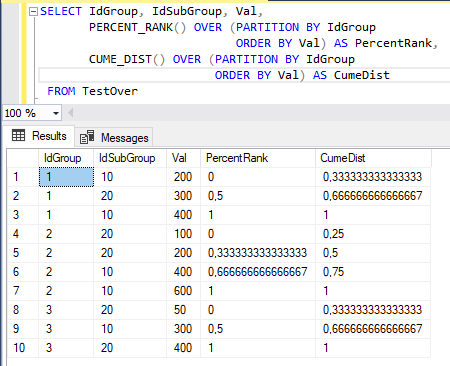
Рис. 22. Результирующая таблица выполнения команды SELECT с аналитическими оконными функциями PERCENT_RANK и CUME_DIST
Функции PERCENT_RANK и CUME_DIST выполняют вычисления немного по-разному. Чтобы понять смысл этих вычислений надо знать статистический анализ. Проще говоря процентильный ранг (функция PERCENT_RANK) в данном примере можно считать долей записей, у которых значение атрибута Val меньше значения этого атрибута в текущей строке, а интегральное распределение (функция CUME_DIST ) — долей записей, у которых значение атрибута Val меньше или равно этому атрибуту в текущей строке.
Значения, которые возвращают эти функции, многие воспринимает как процент.
Функции обратного распределения
Функции обратного распределения, более известные под именем процентилей, выполняют вычисление, которое можно считать обратным к функциям распределения рангов. Как известно, функции распределения рангов (PERCENT_RANK и CUME_DIST) вычисляют относительный ранг текущей строки в секции окна, который выражается числом от 0 до 1 (процентом).
Функции обратного распределения принимают в качестве входных данных процент и возвращают значение из группы, соответствующее этому проценту. Грубо говоря, если на вход поступает процент P и упорядочение в группе основано, например, на атрибуте Val, возвращенный процентиль является значением Val, для которого доля значений Val, которые меньше процентиля, равна P. Наверное самый известный процентиль — 0,5 (50-й процентиль), более известный как медиана. К примеру, если группа состоит из значений 5, 7, 11, 101, 759, то процентиль 0,5 для нее равен 11.
Рассмотрим пример запроса, использующего две аналитические функции PERCENTILE_DISC и PERCENTILE_CONT
SELECT IdGroup, IdSubGroup, Val,
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY Val) OVER (PARTITION BY IdGroup) AS PercentRank,
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY Val) OVER (PARTITION BY IdGroup) AS PercentileCont
FROM TestOver
Результаты выполнения этого запроса приведены на рис. 23.
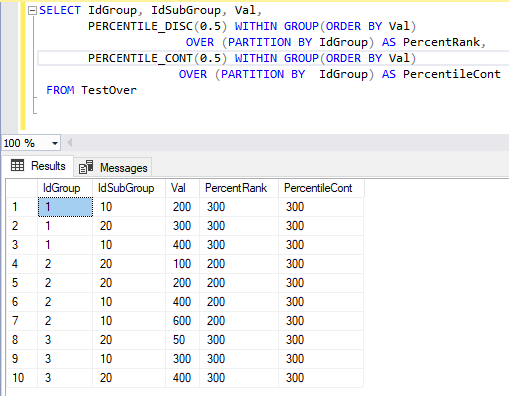
Рис. 23. Результирующая таблица выполнения команды SELECT с аналитическими оконными функциями PERCENTILE_DISC и PERCENTILE_CONT
Функция PERCENTILE_DISC (DISC означает «discrete distribution model», то есть «модель дискретного распределения») возвращает первое значение в группе, интегральное распределение которого больше или равно входному значению, при этом предполагается, что группа трактуется как секция окна с тем же упорядочением, которое определено в группе.
Посмотрите на запрос, результаты которого представлены на рис. 23, где вычисляется процентильный ранг и интегральное распределение. В данном случае функция PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY Val) OVER(PARTITION BY IdGroup) вернет результат 300 для секции со значением атрибута IdGroup равным 1, потому что этот результат относится к интегральному распределению 0.666666666666667, а это первое значение, большее или равное входному числу 0.5.
Оконные функции обратного распределения поддерживают необязательное предложение секционирования окна. В функциях обратного распределения также важно упорядочение, но оно не входит в определение окна, но для этого применяется отдельное предложение WITHIN GROUP.